Peter Bruce - Estadística práctica para ciencia de datos con R y Python
Здесь есть возможность читать онлайн «Peter Bruce - Estadística práctica para ciencia de datos con R y Python» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на испанском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Estadística práctica para ciencia de datos con R y Python
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Estadística práctica para ciencia de datos con R y Python: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Estadística práctica para ciencia de datos con R y Python»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Muchos recursos de la ciencia de datos incorporan métodos estadísticos, pero carecen de una perspectiva estadística más profunda. Si estás familiarizado con los lenguajes de programación R o Python y tienes algún conocimiento de estadística, este libro suple esas carencias de una forma práctica, accesible y clara.
Con este libro aprenderás:
Por qué el análisis exploratorio de datos es un paso preliminar clave en la ciencia de datos
Cómo el muestreo aleatorio puede reducir el sesgo y ofrecer un conjunto de datos de mayor calidad, incluso con Big Data
Cómo los principios del diseño experimental ofrecen respuestas definitivas a preguntas
Cómo utilizar la regresión para estimar resultados y detectar anomalías
Técnicas de clasificación esenciales para predecir a qué categorías pertenece un registro
Métodos estadísticos de aprendizaje automático que «aprenden» a partir de los datos
Métodos de aprendizaje no supervisados para extraer significado de datos sin etiquetar
Peter Bruce es el fundador del Institute for Statistics Education en Statistics.com.
Andrew Bruce es científico investigador jefe en Amazon y tiene más de 30 años de experiencia en estadística y ciencia de datos.
Peter Gedeck es científico de datos senior en Collaborative Drug Discovery, desarrolla algoritmos de aprendizaje automático para pronosticar propiedades de posibles futuros fármacos.
Estadística práctica para ciencia de datos con R y Python — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Estadística práctica para ciencia de datos con R y Python», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
La diferencia entre el mayor y el menor valor de un conjunto de datos.
Estadísticos ordinales
Métricas basadas en los valores de datos ordenados de menor a mayor.
Sinónimo
rangos
Percentil
Valor tal que el P por ciento de los valores toma este valor o un valor inferior y para (100 – P) el porcentaje toma este valor o un valor superior.
Sinónimo
cuantil
Rango intercuartil
Diferencia entre el percentil 75 y el percentil 25.
Sinónimo
IQR
Así como existen diferentes formas de medir la localización (media, mediana, etc.), también existen diferentes formas de medir la variabilidad.
Desviación estándar y estimaciones relacionadas
Las estimaciones de la variación más utilizadas se basan en las diferencias o desviaciones ( deviations ) entre la estimación de la localización y los datos observados. Para un conjunto de datos {1, 4, 4}, la media es 3 y la mediana es 4. Las desviaciones de la media son las diferencias: 1 - 3 = –2, 4 - 3 = 1, 4 - 3 = 1. Estas desviaciones nos dicen lo dispersos están los datos en torno al valor central.
Una forma de medir la variabilidad es estimar un valor típico para estas desviaciones. El promedio de las desviaciones en sí no nos diría mucho: las desviaciones negativas compensan las positivas. De hecho, la suma de las desviaciones de la media es precisamente cero. En cambio, un enfoque sencillo consiste en extraer el promedio de los valores absolutos de las desviaciones de la media. En el ejemplo anterior, el valor absoluto de las desviaciones es {2 1 1} y su promedio es (2 + 1 + 1) / 3 = 1.33. A esta medida se conoce como desviación media absoluta ( mean absolute deviation ) y se calcula con la fórmula:
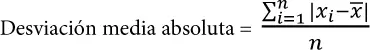
donde x es la media muestral.
Las estimaciones de variabilidad más conocidas son la varianza ( variance ) y la desviación estándar ( standard deviation ), que se calculan a partir del cuadrado de las desviaciones. La varianza es un promedio del cuadrado de las desviaciones y la desviación estándar es la raíz cuadrada de la varianza:
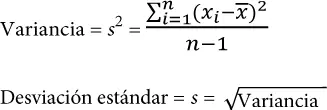
La desviación estándar es mucho más fácil de interpretar que la varianza, ya que está en la misma escala que los datos originales. Aun así, con su fórmula más complicada y menos intuitiva, podría parecer peculiar que en estadística se prefiera la desviación estándar a la desviación media absoluta. Debe su supremacía a la teoría estadística, ya que trabajar matemáticamente con valores al cuadrado es mucho más conveniente que con valores absolutos, especialmente en el caso de modelos estadísticos.
Grados de libertad, y ¿ n o n – 1?
En los libros de estadística, siempre se discute por qué tenemos n – 1 en el denominador en la fórmula de la varianza, en lugar de n, lo que conduce al concepto de grados de libertad ( degrees of freedom ). Esta distinción no es importante ya que n es generalmente lo suficientemente grande como para que no haya mucha diferencia si dividimos entre n o n – 1. Pero en caso de que sea de interés, lo explicamos a continuación. Se fundamenta en la premisa de que deseamos hacer estimaciones sobre una población, basándonos en una muestra.
Si usamos el denominador intuitivo de n en la fórmula de la varianza, subestimaremos el valor real de la varianza y la desviación estándar en la población. Esto se conoce como estimación sesgada ( biased ). Sin embargo, si dividimos por n – 1 en lugar de n , la varianza se convierte en una estimación no sesgada ( unbiased ).
Explicar completamente por qué el uso de n conduce a una estimación sesgada implica la noción de grados de libertad, que tiene en cuenta el número de restricciones al calcular una estimación. En este caso, hay n – 1 grados de libertad, ya que hay una restricción: la desviación estándar depende del cálculo de la media muestral. Para la mayoría de los problemas, los científicos de datos no necesitan preocuparse por los grados de libertad.
La varianza, la desviación estándar y la desviación absoluta mediana son robustas a valores atípicos y extremos (consultar "Estimación de medianas robustas" en la página 10, donde se desarrolla un debate sobre estimaciones robustas para la localización). La varianza y la desviación estándar son especialmente sensibles a los valores atípicos, ya que se basan en las desviaciones al cuadrado.
Una estimación robusta de la variabilidad es la desviación absoluta mediana de la mediana ( median absolute deviation from the median ) o MAD:
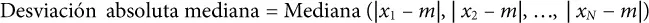
donde m es la mediana. Al igual que la mediana, la MAD no se ve influenciada por valores extremos. También es posible calcular la desviación estándar truncada análoga a la media truncada (consultar "Media" en la página 9).

La varianza, la desviación estándar, la desviación media absoluta y la desviación absoluta mediana no son estimaciones equivalentes, incluso en el caso de que los datos provengan de una distribución normal. De hecho, la desviación estándar es siempre mayor que la desviación absoluta media, que a su vez es mayor que la desviación absoluta mediana. A veces, la desviación absoluta mediana se multiplica por un factor de escala constante para adaptarla a la misma escala que la desviación estándar en el caso de una distribución normal. El factor que se utiliza normalmente de 1.4826 significa que el 50% de la distribución normal cae dentro del rango ± MAD.
Estimación basada en percentiles
Un enfoque diferente para estimar la dispersión se centra en observar la distribución de los datos ordenados. Los estadísticos que tienen como base los datos ordenados (clasificados) se denominan estadísticos de orden ( order statistics ). La medida más elemental es el rango ( range ): la diferencia entre los números de mayor y menor valor. Es de utilidad conocer los valores mínimos y máximos en sí, además de práctico, para identificar valores atípicos, pero el rango es extremadamente sensible a los valores atípicos y no es muy útil como medida general de la dispersión de datos.
Para evitar la sensibilidad a los valores atípicos, podemos observar el rango de los datos después de eliminar valores de cada extremo. Formalmente, este tipo de estimaciones se basan en diferencias entre percentiles ( percentiles ). En un conjunto de datos, el percentil P es un valor tal que al menos el P por ciento de los valores toman este valor o un valor inferior y al menos (100 - P ) por ciento de los valores toman este valor o un valor superior. Por ejemplo, para encontrar el percentil 80, ordenamos los datos. Luego, comenzando por el valor más pequeño, continuamos hasta el 80% del recorrido para llegar al mayor valor. Hay que tener en cuenta que la mediana es lo mismo que el percentil 50. El percentil es esencialmente lo mismo que el cuantil ( quantile ), con los cuantiles referenciados por porcentajes (por lo que el cuantil 0.8 es lo mismo que el percentil 80).
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Estadística práctica para ciencia de datos con R y Python»
Представляем Вашему вниманию похожие книги на «Estadística práctica para ciencia de datos con R y Python» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Estadística práctica para ciencia de datos con R y Python» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.