Peter Bruce - Estadística práctica para ciencia de datos con R y Python
Здесь есть возможность читать онлайн «Peter Bruce - Estadística práctica para ciencia de datos con R y Python» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на испанском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Estadística práctica para ciencia de datos con R y Python
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Estadística práctica para ciencia de datos con R y Python: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Estadística práctica para ciencia de datos con R y Python»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Muchos recursos de la ciencia de datos incorporan métodos estadísticos, pero carecen de una perspectiva estadística más profunda. Si estás familiarizado con los lenguajes de programación R o Python y tienes algún conocimiento de estadística, este libro suple esas carencias de una forma práctica, accesible y clara.
Con este libro aprenderás:
Por qué el análisis exploratorio de datos es un paso preliminar clave en la ciencia de datos
Cómo el muestreo aleatorio puede reducir el sesgo y ofrecer un conjunto de datos de mayor calidad, incluso con Big Data
Cómo los principios del diseño experimental ofrecen respuestas definitivas a preguntas
Cómo utilizar la regresión para estimar resultados y detectar anomalías
Técnicas de clasificación esenciales para predecir a qué categorías pertenece un registro
Métodos estadísticos de aprendizaje automático que «aprenden» a partir de los datos
Métodos de aprendizaje no supervisados para extraer significado de datos sin etiquetar
Peter Bruce es el fundador del Institute for Statistics Education en Statistics.com.
Andrew Bruce es científico investigador jefe en Amazon y tiene más de 30 años de experiencia en estadística y ciencia de datos.
Peter Gedeck es científico de datos senior en Collaborative Drug Discovery, desarrolla algoritmos de aprendizaje automático para pronosticar propiedades de posibles futuros fármacos.
Estadística práctica para ciencia de datos con R y Python — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Estadística práctica para ciencia de datos con R y Python», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Valores atípicos
A la mediana se le conoce como una estimación robusta ( robust ) de la localización, ya que no está influenciada por valores atípicos ( outliers ) (casos extremos) que podrían sesgar los resultados. Un valor atípico es cualquier valor que está muy lejos de los otros valores en el conjunto de datos. La definición exacta de valor atípico es algo subjetiva, a pesar de que se utilizan ciertas convenciones en distintos resúmenes de datos y diagramas (consultar "Percentiles y diagramas de caja" en la página 20). Ser un valor atípico en sí mismo no hace que un valor de los datos no sea válido o sea erróneo (como en el ejemplo anterior con Bill Gates). Aun así, los valores atípicos son a menudo el resultado de errores de datos, como la combinación de datos de diferentes unidades (kilómetros en lugar de metros) o las lecturas incorrectas de un sensor. Cuando los valores atípicos son el resultado de datos incorrectos, la media dará como resultado una estimación deficiente de la localización, mientras que la mediana seguirá siendo válida. Los valores atípicos deben identificarse y, por lo general, merecen una investigación más profunda.

Detección de anomalías
En contraste con el análisis normal de datos, donde los valores atípicos son a veces informativos y a veces molestos, en la detección de anomalías ( anomaly detection ) los puntos que nos interesan son los valores atípicos, y la mayor masa de datos sirve principalmente para definir la "normalidad" con la que se miden las anomalías.
La mediana no es la única estimación robusta de la localización. De hecho, la media truncada se usa habitualmente para evitar la influencia de valores atípicos. Por ejemplo, truncar el 10% inferior y superior (una opción frecuente) de los datos proporcionará protección contra valores atípicos en todos los conjuntos de datos, excepto en los más pequeños. La media truncada se puede considerar un compromiso entre la mediana y la media: es robusta a los valores extremos de los datos, pero utiliza más datos para calcular la estimación de la localización.

Otras métricas robustas para la localización
Los estadísticos han desarrollado una plétora de otros estimadores de localización, principalmente con el objetivo de desarrollar un estimador más robusto que la media y también más eficiente (es decir, más capaz de discernir pequeñas diferencias de localización entre conjuntos de datos). Si bien estos métodos son potencialmente útiles para conjuntos de datos pequeños, no es probable que proporcionen algún beneficio adicional para conjuntos con cantidades grandes de datos o incluso de tamaño moderado.
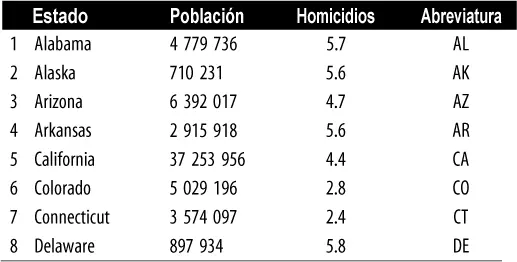
Ejemplo: estimaciones de localización de la población y tasas de homicidios
La tabla 1.2muestra las primeras filas del conjunto de datos que contienen la población y las tasas de homicidios (en unidades de homicidios por cada 100 000 habitantes y por año) para cada estado de EE. UU. (censo de 2010).
Tabla 1.2Algunas filas de data.frame de la situación de la población y la tasa de homicidios por estados
Utilizamos R para calcular la media, la media truncada y la mediana de la población:

Para calcular la media y la mediana con Python , podemos emplear los métodos pandas del marco de datos. La media truncada requiere la función trim_mean de scipy.stats:

La media es mayor que la media truncada, que es mayor que la mediana.
Esto se debe a que la media truncada excluye los cinco estados más grandes y más pequeños (trim=0.1 ignora el 10% de cada extremo). Si queremos calcular la tasa de homicidios promedio para el país, necesitamos usar una media o mediana ponderadas para dar cuenta de las diferentes poblaciones de los estados. Dado que el software básico de R no tiene una función para la mediana truncada, necesitamos instalar el paquete matrixStats:

Con NumPy podemos disponer de la media ponderada. Para la mediana ponderada, podemos usar el paquete especializado wquantiles ( https://pypi.org/project/wquantiles/ ):
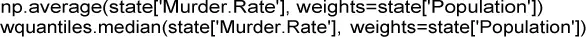
En este caso, la media ponderada y la mediana ponderada son aproximadamente iguales.
Ideas clave
• La métrica básica para la localización es la media, pero puede ser sensible a valores extremos (valores atípicos).
• Otras métricas (mediana, media truncada) son menos sensibles a valores atípicos y a distribuciones inusuales y, por lo tanto, son más robustas.
Lecturas complementarias
• El artículo de Wikipedia sobre tendencia central contiene un amplio debate sobre varias medidas de localización.
• El clásico Exploratory Data Analysis (Pearson) de John Tukey de 1977 todavía se lee bastante.
Estimación de la variabilidad
La localización es solo una dimensión para extraer el resumen de una característica. Una segunda dimensión, la variabilidad ( variability ), también conocida como dispersión ( dispersion ), mide el grado de agrupación o dispersión de los valores de los datos. En el corazón de la estadística se encuentra la variabilidad: hay que medirla, reducirla, distinguir la variabilidad aleatoria de la real, identificar las diversas fuentes de variabilidad real y tomar decisiones teniéndola en cuenta.
Términos clave de métricas de variabilidad
Desviaciones
Diferencias entre los valores observados y la estimación de la localización.
Sinónimos
errores, residuales
Varianza
Suma de los cuadrados de las desviaciones de la media al cuadrado y dividida por n – 1, donde n es el número de valores de datos.
Sinónimo
error cuadrático medio
Desviación estándar
Raíz cuadrada de la varianza.
Desviación media absoluta
Media de los valores absolutos de las desviaciones de la media.
Sinónimos
norma L1, norma Manhattan
Desviación absoluta mediana de la mediana
Mediana de los valores absolutos de las desviaciones de la mediana.
Rango
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Estadística práctica para ciencia de datos con R y Python»
Представляем Вашему вниманию похожие книги на «Estadística práctica para ciencia de datos con R y Python» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Estadística práctica para ciencia de datos con R y Python» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.