Peter Bruce - Estadística práctica para ciencia de datos con R y Python
Здесь есть возможность читать онлайн «Peter Bruce - Estadística práctica para ciencia de datos con R y Python» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на испанском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Estadística práctica para ciencia de datos con R y Python
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Estadística práctica para ciencia de datos con R y Python: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Estadística práctica para ciencia de datos con R y Python»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Muchos recursos de la ciencia de datos incorporan métodos estadísticos, pero carecen de una perspectiva estadística más profunda. Si estás familiarizado con los lenguajes de programación R o Python y tienes algún conocimiento de estadística, este libro suple esas carencias de una forma práctica, accesible y clara.
Con este libro aprenderás:
Por qué el análisis exploratorio de datos es un paso preliminar clave en la ciencia de datos
Cómo el muestreo aleatorio puede reducir el sesgo y ofrecer un conjunto de datos de mayor calidad, incluso con Big Data
Cómo los principios del diseño experimental ofrecen respuestas definitivas a preguntas
Cómo utilizar la regresión para estimar resultados y detectar anomalías
Técnicas de clasificación esenciales para predecir a qué categorías pertenece un registro
Métodos estadísticos de aprendizaje automático que «aprenden» a partir de los datos
Métodos de aprendizaje no supervisados para extraer significado de datos sin etiquetar
Peter Bruce es el fundador del Institute for Statistics Education en Statistics.com.
Andrew Bruce es científico investigador jefe en Amazon y tiene más de 30 años de experiencia en estadística y ciencia de datos.
Peter Gedeck es científico de datos senior en Collaborative Drug Discovery, desarrolla algoritmos de aprendizaje automático para pronosticar propiedades de posibles futuros fármacos.
Estadística práctica para ciencia de datos con R y Python — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Estadística práctica para ciencia de datos con R y Python», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Los datos rectangulares (como puede ser una hoja de cálculo) son la estructura básica de datos para los modelos estadísticos y de aprendizaje automático.
Característica
Una columna de una tabla se denomina generalmente característica ( feature ).
Sinónimos
atributo, entrada, predictor, variable
Resultado
Muchos proyectos de ciencia de datos implican pronosticar un resultado ( outcome ), a menudo un resultado de sí/no (en la tabla 1.1, es si "la subasta ha sido competitiva o no"). A veces, las características ( features ) se utilizan para pronosticar el resultado ( outcome ) de un estudio.
Sinónimos
variable dependiente, respuesta, objetivo, salida
Registros
A una fila dentro de una tabla se le denomina generalmente registro ( register ).
Sinónimos
caso, ejemplo, instancia, observación, patrón, muestra
Tabla 1.1Típico formato del marco de datos
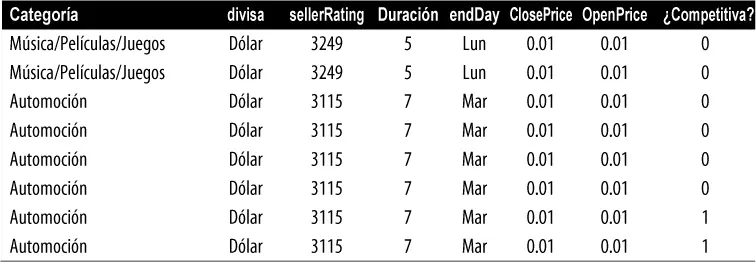
En la tabla 1.1, hay una combinación de datos medidos o contabilizados (por ejemplo, duración y precio) y datos categóricos (por ejemplo, categoría y divisa). Como se ha mencionado anteriormente, una forma especial de variable categórica es una variable binaria (sí/no o 0/1), como se ve en la columna de la derecha en la tabla 1.1, una variable indicadora que muestra si una subasta ha sido competitiva (si ha tenido varios postores) o no. Esta variable indicadora también resulta ser una variable de resultado ( outcome ), cuando el escenario es pronosticar si una subasta es competitiva o no.
Marcos de datos e índices
Las tablas de bases de datos tradicionales tienen una o más columnas designadas como índice, esencialmente un número de fila. Esta funcionalidad puede mejorar enormemente la eficiencia de determinadas consultas a bases de datos. En Python , con la biblioteca de pandas, la estructura básica de datos rectangulares es el objeto DataFrame. Por defecto, se crea un índice de enteros automático para un DataFrame basado en el orden de las filas. En pandas, también es posible establecer índices jerárquicos/multinivel para mejorar la eficiencia de ciertas operaciones.
En R , la estructura básica de datos rectangulares es el objeto data.frame. data.frame también tiene un índice implícito de enteros basado en el orden de las filas. El data.frame nativo de R no admite índices especificados por el usuario o multinivel, aunque se puede crear una clave personalizada mediante el atributo row.names. Para superar esta deficiencia, hay dos nuevos paquetes que se están utilizando de forma generalizada: data.table y dplyr. Ambos admiten índices multinivel y ofrecen importantes aumentos de velocidad cuando se trabaja con data.frame.

Diferencias terminológicas
La terminología de datos rectangulares puede resultar confusa. Los estadísticos y los científicos de datos usan términos diferentes para referirse al mismo concepto. Para un estadístico, las variables predictoras ( predictor variables ) se utilizan en un modelo para pronosticar una respuesta ( response ) o variable dependiente ( dependent variable ). Para un científico de datos, las características ( features ) se utilizan para pronosticar un objetivo ( target ). Los sinónimos resultan particularmente confusos: los informáticos usarán el término muestra ( sample ) para una única fila. Una muestra ( sample ) para un estadístico es una colección de filas.
Estructuras de datos no rectangulares
Existen otras estructuras de datos además de los datos rectangulares.
Los datos de serie de tiempo registran mediciones sucesivas de la misma variable. Es la materia prima de los métodos de pronóstico estadístico y también es un componente clave de los datos generados por los dispositivos del Internet de las cosas.
Las estructuras de datos espaciales, que se utilizan en cartografía y análisis de la localización, son más complejas y variadas que las estructuras de datos rectangulares. En la representación del objeto ( object ), el foco de los datos es un objeto (por ejemplo, una casa) y sus coordenadas espaciales. La vista de campo ( field ), por el contrario, se centra en pequeñas unidades de espacio y el valor de la métrica correspondiente (brillo de píxeles, por ejemplo).
Las estructuras de datos en forma de gráficos (o redes) se utilizan para representar relaciones físicas, sociales y abstractas. Por ejemplo, un gráfico de una red social, como Facebook o LinkedIn, puede representar conexiones entre personas en la red. Los centros de distribución conectados por carreteras son un ejemplo de una red física. Las estructuras de gráficos son útiles para ciertos tipos de problemas, como la optimización de redes o los sistemas de recomendación.
Cada uno de estos tipos de datos tiene su metodología especializada en ciencia de datos. El enfoque de este libro se centra en los datos rectangulares, el bloque de construcción fundamental del modelado predictivo.
Gráficos en estadística
En informática y tecnologías de la información, el término gráfico ( graph ) hace referencia normalmente a la descripción de las conexiones entre entidades y a la estructura de datos subyacente. En estadística, gráfico ( graph ) se utiliza para referirse a una variedad de diagramas y visualizaciones ( visualizations ), no solo de conexiones entre entidades, aunque el término se aplica solo a la visualización, no a la estructura de datos.
Ideas clave
• La estructura de datos básica en ciencia de datos es una matriz rectangular en la que las filas están formadas por registros y las columnas son las variables (características).
• La terminología puede resultar confusa. Existe una serie de sinónimos, procedentes de diferentes disciplinas, que contribuyen a la ciencia de datos (estadística, informática y tecnologías de la información).
Lecturas complementarias
• Documentación sobre marcos de datos en R ( https://stat.ethz.ch/R-manual/R-devel/library/base/html/data.frame.html ).
• Documentación sobre marcos de datos en Python ( https://pandas.pydata.org/pandas-docs/stable/user_guide/dsintro.html ).
Estimación de la localización
Las variables, con los datos medidos o procedentes de recuentos, pueden tener miles de valores distintos. Un paso fundamental para explorar los datos es obtener un "valor típico" para cada característica (variable): una estimación de dónde se encuentra la mayoría de los datos (es decir, su tendencia central).
Términos clave de la estimación de la localización
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Estadística práctica para ciencia de datos con R y Python»
Представляем Вашему вниманию похожие книги на «Estadística práctica para ciencia de datos con R y Python» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Estadística práctica para ciencia de datos con R y Python» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.