Peter Bruce - Estadística práctica para ciencia de datos con R y Python
Здесь есть возможность читать онлайн «Peter Bruce - Estadística práctica para ciencia de datos con R y Python» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на испанском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Estadística práctica para ciencia de datos con R y Python
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Estadística práctica para ciencia de datos con R y Python: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Estadística práctica para ciencia de datos con R y Python»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Muchos recursos de la ciencia de datos incorporan métodos estadísticos, pero carecen de una perspectiva estadística más profunda. Si estás familiarizado con los lenguajes de programación R o Python y tienes algún conocimiento de estadística, este libro suple esas carencias de una forma práctica, accesible y clara.
Con este libro aprenderás:
Por qué el análisis exploratorio de datos es un paso preliminar clave en la ciencia de datos
Cómo el muestreo aleatorio puede reducir el sesgo y ofrecer un conjunto de datos de mayor calidad, incluso con Big Data
Cómo los principios del diseño experimental ofrecen respuestas definitivas a preguntas
Cómo utilizar la regresión para estimar resultados y detectar anomalías
Técnicas de clasificación esenciales para predecir a qué categorías pertenece un registro
Métodos estadísticos de aprendizaje automático que «aprenden» a partir de los datos
Métodos de aprendizaje no supervisados para extraer significado de datos sin etiquetar
Peter Bruce es el fundador del Institute for Statistics Education en Statistics.com.
Andrew Bruce es científico investigador jefe en Amazon y tiene más de 30 años de experiencia en estadística y ciencia de datos.
Peter Gedeck es científico de datos senior en Collaborative Drug Discovery, desarrolla algoritmos de aprendizaje automático para pronosticar propiedades de posibles futuros fármacos.
Estadística práctica para ciencia de datos con R y Python — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Estadística práctica para ciencia de datos con R y Python», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Diagrama y estimación de la curva de densidad
Relacionado con el histograma existe el diagrama de densidad, que muestra la distribución de los valores de los datos mediante una línea continua. Un diagrama de densidad se puede considerar como un histograma suavizado, aunque normalmente se calcula directamente a partir de los datos a través de una estimación de la densidad del núcleo ( kernel density estimate ) (ver [Duong, 2001], un breve tutorial). La figura 1.4muestra la estimación de la densidad, que aparece superpuesta al histograma. En R , podemos calcular la estimación de la densidad utilizando la función density:

pandas proporciona el método density para crear el diagrama de densidad. Utilizamos el argumento bw_method para controlar la suavidad de la curva de densidad:
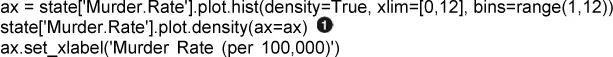
 Las funciones del diagrama a menudo adoptan opcionalmente el argumento de eje (ax), lo que hará que el diagrama se agregue al mismo gráfico.
Las funciones del diagrama a menudo adoptan opcionalmente el argumento de eje (ax), lo que hará que el diagrama se agregue al mismo gráfico.
Una distinción clave del histograma con diagrama de la figura 1.3es la escala del eje y: el diagrama de densidad corresponde a la representación del histograma en porcentajes en lugar de hacerlo por el número de valores (esta opción la especificamos en R usando el argumento freq=FALSE). Hay que tener en cuenta que el área total por debajo de la curva de densidad es igual a 1 y, en lugar de aparecer el número de valores de los contenedores, calculamos el área que queda por debajo de la curva entre dos puntos cualesquiera en el eje x, que corresponde al porcentaje de la distribución que se encuentra entre esos dos puntos.
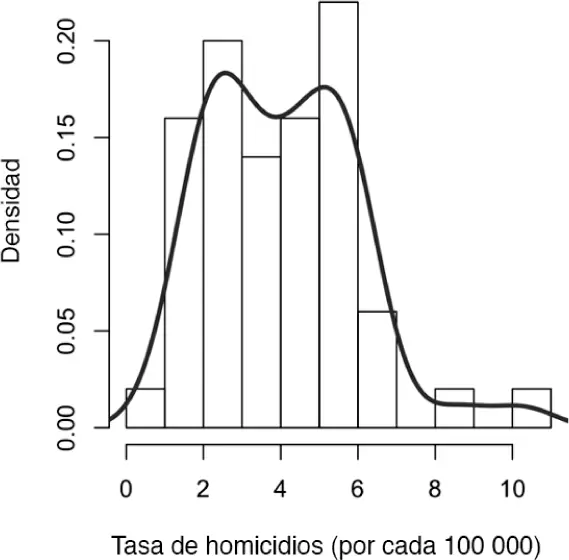
Figura 1.4 Densidad de las tasas de homicidios por estados.

Valoración de la densidad
La valoración de la densidad es un tema candente con una larga historia en la literatura estadística. De hecho, se han publicado más de 20 paquetes R que ofrecen funciones para la valoración de la densidad. [Deng-Wickham, 2011] proporciona una revisión completa de los paquetes R , con una recomendación particular para ASH o KernSmooth. Los métodos de valoración de la densidad en pandas y scikit-learn también proporcionan buenas aplicaciones. Para muchos problemas de ciencia de datos, no hay necesidad de preocuparse por los diversos tipos de estimaciones de la densidad, basta con utilizar las funciones básicas.
Ideas clave
• El histograma de frecuencias representa las frecuencias de los resultados (recuentos) en el eje y y los valores de la variable en el eje x. Proporciona de un vistazo una idea de la distribución de los datos.
• La tabla de frecuencias es una versión tabular de las frecuencias de los resultados que se encuentran en un histograma.
• Un diagrama de caja, con la parte superior e inferior de la caja en los percentiles 75 y 25, respectivamente, también da una idea rápida de la distribución de los datos. A menudo se utiliza en visualizaciones paralelas para comparar distribuciones.
• El diagrama de densidad es una versión suavizada del histograma. Requiere una función para estimar el diagrama basado en los datos (por supuesto, son posibles múltiples estimaciones).
Lecturas complementarias
• Un profesor de SUNY Oswego proporciona una guía paso a paso para crear un diagrama de caja ( https://www.oswego.edu/~srp/stats/bp_con.htm ).
• La valoración de la densidad en R se trata en el artículo del mismo nombre de Henry Deng y Hadley Wickham ( http://vita.had.co.nz/papers/density-estimation.pdf ).
• R -Bloggers tiene una publicación muy útil sobre histogramas con R ( https://www.rbloggers.com/2012/12/basics-of-histograms/ ), que incluye elementos de personalización, como es el agrupamiento (uso de breaks()).
• R -Bloggers también tiene una publicación similar sobre el diagrama de caja con R ( https://www.r-bloggers.com/2013/06/box-plot-with-r-tutorial/ ).
• Matthew Conlen tiene una presentación interactiva ( https://mathisonian.github.io/kde/ ) que demuestra el efecto de elegir diferentes núcleos y ancho de banda en las estimaciones de densidad del núcleo.
Exploración de datos binarios y categóricos
En el caso de los datos categóricos, las proporciones simples o porcentajes cuentan la historia de los datos.
Términos clave de la exploración de datos categóricos
Moda
Categoría o valor que ocurre con más frecuencia en un conjunto de datos.
Valor esperado
Cuando las categorías se pueden asociar con un valor numérico, el valor esperado proporciona un valor promedio basado en la probabilidad de ocurrencia de una categoría.
Gráficos de barras
Frecuencia o proporción de cada categoría representada en barras.
Gráficos en forma de tarta
Frecuencia o proporción de cada categoría representada en forma de cuña de un pastel.
Obtener el resumen de una variable binaria o una variable categórica con varias categorías es un asunto bastante fácil: sencillamente calculamos la proporción de 1 o las proporciones de las categorías importantes. Por ejemplo, la tabla 1.6muestra el porcentaje de vuelos que han llegado con retraso a sus destinos como consecuencia de los retrasos en el aeropuerto de Dallas/Fort Worth en 2010. Los retrasos se clasifican como debidos a: factores bajo el control de la aerolínea, retrasos en el sistema de control del tráfico aéreo (CTA), el clima, la seguridad o las aeronaves que llegan tarde.
Tabla 1.6Porcentaje de retrasos causados por el aeropuerto de Dallas/Fort Worth

Los gráficos de barras, que se ven a menudo en la prensa de gran difusión, son una herramienta visual muy utilizada para mostrar una única variable categórica. Las categorías se enumeran en el eje x y las frecuencias o porcentajes, en el eje y. La figura 1.5muestra los retrasos por año en el aeropuerto de Dallas/Fort Worth (DFW), y se genera con la función R barplot:

pandas también soporta gráficos de barras para marcos de datos:

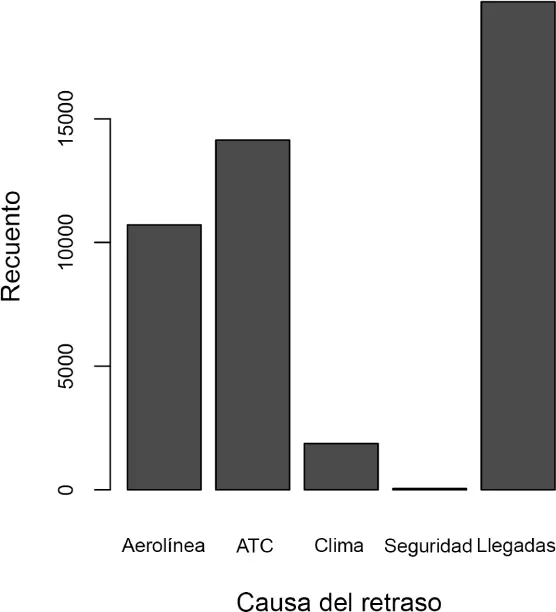
Figura 1.5 Gráfico de barras de retrasos de aerolíneas en el aeropuerto de DFW.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Estadística práctica para ciencia de datos con R y Python»
Представляем Вашему вниманию похожие книги на «Estadística práctica para ciencia de datos con R y Python» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Estadística práctica para ciencia de datos con R y Python» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.