Peter Bruce - Estadística práctica para ciencia de datos con R y Python
Здесь есть возможность читать онлайн «Peter Bruce - Estadística práctica para ciencia de datos con R y Python» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на испанском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Estadística práctica para ciencia de datos con R y Python
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Estadística práctica para ciencia de datos con R y Python: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Estadística práctica para ciencia de datos con R y Python»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Muchos recursos de la ciencia de datos incorporan métodos estadísticos, pero carecen de una perspectiva estadística más profunda. Si estás familiarizado con los lenguajes de programación R o Python y tienes algún conocimiento de estadística, este libro suple esas carencias de una forma práctica, accesible y clara.
Con este libro aprenderás:
Por qué el análisis exploratorio de datos es un paso preliminar clave en la ciencia de datos
Cómo el muestreo aleatorio puede reducir el sesgo y ofrecer un conjunto de datos de mayor calidad, incluso con Big Data
Cómo los principios del diseño experimental ofrecen respuestas definitivas a preguntas
Cómo utilizar la regresión para estimar resultados y detectar anomalías
Técnicas de clasificación esenciales para predecir a qué categorías pertenece un registro
Métodos estadísticos de aprendizaje automático que «aprenden» a partir de los datos
Métodos de aprendizaje no supervisados para extraer significado de datos sin etiquetar
Peter Bruce es el fundador del Institute for Statistics Education en Statistics.com.
Andrew Bruce es científico investigador jefe en Amazon y tiene más de 30 años de experiencia en estadística y ciencia de datos.
Peter Gedeck es científico de datos senior en Collaborative Drug Discovery, desarrolla algoritmos de aprendizaje automático para pronosticar propiedades de posibles futuros fármacos.
Estadística práctica para ciencia de datos con R y Python — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Estadística práctica para ciencia de datos con R y Python», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Dos variables categóricas
Una forma conveniente de resumir dos variables categóricas es mediante una tabla de contingencia, una tabla de recuentos por categorías. La tabla 1.8muestra la tabla de contingencia con la calificación de un préstamo personal y el resultado de ese préstamo. Esta información se ha extraído de los datos proporcionados por Lending Club, líder en el negocio de préstamos entre particulares. La calificación va desde A (la más alta) a G (la más baja). El resultado es: totalmente pagado, al corriente de pago, atrasado o cancelado (no se espera que se cobre el importe del préstamo). La tabla muestra el recuento y las filas de porcentajes. Los préstamos de alta calificación tienen un porcentaje muy bajo de retrasos en el pago/cancelaciones en comparación con los préstamos de baja calificación.
Tabla 1.8 Tabla de contingencia de las calificaciones y estados de los préstamos
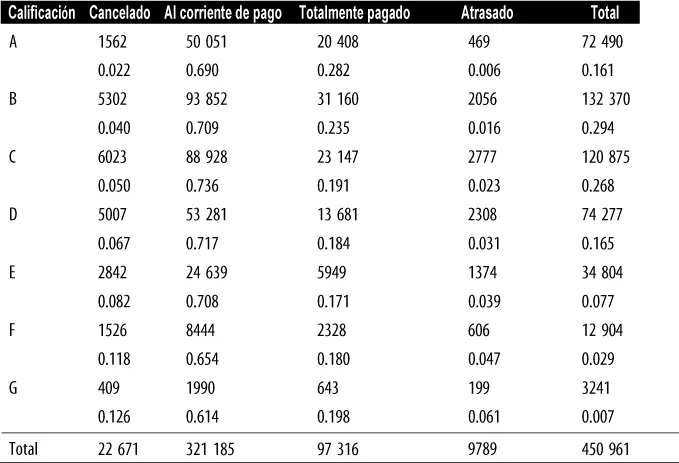
En las tablas de contingencia solo se suelen ver recuentos, aunque también pueden incluir porcentajes totales y de cada columna. Las tablas dinámicas en Excel son quizá la herramienta más utilizada para crear tablas de contingencia. En R , con la función CrossTable del paquete descr podemos generar tablas de contingencia. Para crear la tabla 1.8se ha utilizado el siguiente código:

El método pivot_table crea las tablas dinámicas en Python . El argumento aggfunc nos permite obtener los recuentos. Calcular los porcentajes es un poco más complicado:

 El argumento de palabra clave margins agregará las sumas de filas y columnas.
El argumento de palabra clave margins agregará las sumas de filas y columnas.
 Creamos una copia de la tabla dinámica ignorando las sumas de las columnas.
Creamos una copia de la tabla dinámica ignorando las sumas de las columnas.
 Dividimos las filas por la fila suma.
Dividimos las filas por la fila suma.
 Dividimos la columna 'All' por su suma.
Dividimos la columna 'All' por su suma.
Datos categóricos y numéricos
Los diagramas de caja (consultar "Percentiles y diagramas de caja" en la página 20) son una forma sencilla de comparar visualmente las distribuciones de una variable numérica agrupada de acuerdo con una variable categórica. Por ejemplo, es posible que deseemos comparar cómo varía el porcentaje de retrasos en los vuelos entre las aerolíneas. La figura 1.10muestra el porcentaje de vuelos que se retrasaron en un mes en el que el retraso lo controlaban las aerolíneas:
El método boxplot de pandas toma el argumento by que divide el conjunto de datos en grupos y crea los diagramas de caja individuales:
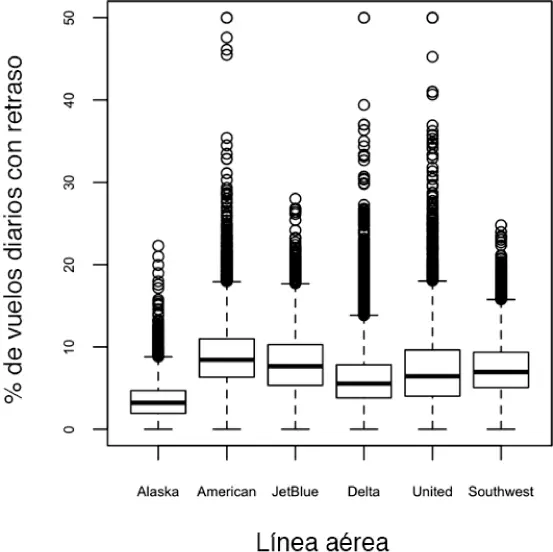
Figura 1.10 Diagrama de caja del porcentaje de retrasos por aerolínea.
Alaska se destaca por tener la menor cantidad de retrasos, mientras que American tiene la mayor cantidad de retrasos: el cuartil inferior de American está más alto que el cuartil superior de Alaska.
El diagrama de violín ( violin plot ), introducido por [Hintze-Nelson, 1998], es una mejora del diagrama de caja y representa la estimación de la densidad, con la densidad asociada al eje y. Se obtiene la imagen especular del diagrama de densidad, volcando a continuación ambas imágenes. La forma resultante se rellena, creando una imagen que se asemeja a un violín. La ventaja de un diagrama de violín es que puede mostrar matices en la distribución que no son perceptibles en un diagrama de caja. Por otro lado, el diagrama de caja muestra más claramente los valores atípicos de los datos. En ggplot2, la función geom_violin se puede usar para crear un diagrama de violín de la siguiente manera:

Los diagramas de violín están disponibles con el método violinplot del paquete seaborn:

El diagrama correspondiente se muestra en la figura 1.11. El diagrama del violín muestra una concentración en la distribución cercana a cero para Alaska y, en menor medida, para Delta. Este fenómeno no es tan obvio en el diagrama de caja. Podemos combinar el diagrama de violín con el diagrama de caja agregando geom_boxplot al diagrama (aunque su funcionamiento mejora cuando se presenta en color).
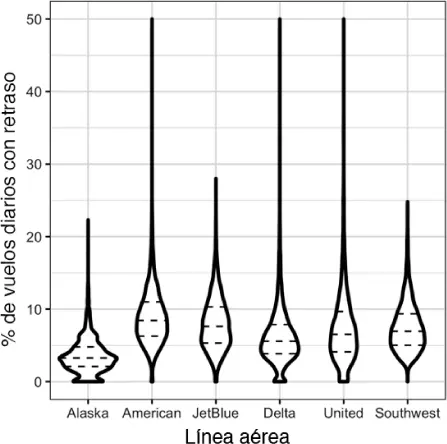
Figura 1.11 Diagrama de violín del porcentaje de retrasos por aerolínea.
Visualización de varias variables
Los tipos de gráficos que se utilizan para comparar dos variables (diagramas de dispersión, agrupación hexagonal y diagramas de caja) se extienden fácilmente a más variables mediante la noción de a condicionamiento ( conditioning ). Como ejemplo, veamos la anterior figura 1.8, que muestra la relación entre las superficies en pies cuadrados de las viviendas terminadas y sus valores de tasación fiscal. Observamos que parece haber un grupo de viviendas que tienen un valor fiscal más alto por pie cuadrado. Profundizando, la figura 1.12explica el efecto de la localización al representar los datos para un conjunto de códigos postales. Ahora el panorama es mucho más claro: el valor fiscal es mucho más alto en algunos códigos postales (98105, 98126) que en otros (98108, 98188). Esta disparidad da lugar a los conglomerados observados en la figura 1.8.
Creamos la figura 1.12usando ggplot2 y el concepto de facetas ( facets ) o de una variable condicionante (en este caso, el código postal):

Utilizamos las funciones facet_wrap y facet_grid de ggplot para especificar la variable condicionante.
Интервал:
Закладка:
Похожие книги на «Estadística práctica para ciencia de datos con R y Python»
Представляем Вашему вниманию похожие книги на «Estadística práctica para ciencia de datos con R y Python» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Estadística práctica para ciencia de datos con R y Python» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.