Jonas Wibowo - Betreuung selbständigen Lernens im Sportunterricht
Здесь есть возможность читать онлайн «Jonas Wibowo - Betreuung selbständigen Lernens im Sportunterricht» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на немецком языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Betreuung selbständigen Lernens im Sportunterricht
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Betreuung selbständigen Lernens im Sportunterricht: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Betreuung selbständigen Lernens im Sportunterricht»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Die Fragestellung ergibt sich aus einem komplexen Herausforderungsprofil für Lehrkräfte im Kontext der Betreuung selbständigen Lernens im Sportunterricht. Einerseits soll die Sportlehr-kraft Schülern helfen fachliche Fortschritte zu machen, indem die Schüler bewegungsbezo-gene Problemstellungen lösen, andererseits sollen diese Problemstellungen so gelöst werden, dass die Schüler so viel Verantwortung wie möglich für ihren eigenen Lernprozess übernehmen – sie also möglichst selbständig agieren. Solche Forderungen – wie auch weitere z.B. nach einer demokratieorientierten Einbettung von Sportunterricht – leiten sich aus Ansprüchen eines erziehenden Sportunterrichts ab wie ihn bspw. Prohl formuliert (Prohl, 2010).
Als Antwort auf diesen Fragehorizont und Ergebnis der Untersuchung wird eine Systematik vorgestellt, die das Lehrerhandeln hinsichtlich seiner Adaption an die Problemlöseprozesse der Schüler und an das Verantwortungsübernahmepotential der Schüler kategorisiert. Gemes-sen an den beiden oben genannten Zielen von Sportunterricht – fachlicher Fortschritt und Verantwortungsübernahme der Schüler – wird angenommen, dass adaptiertes Verhalten der Lehrkraft dazu führt, dass erstens Schüler größere Fortschritte in ihrem Problemlöseprozess erzielen und zweitens soviel Verantwortung für ihren Lernprozess übernehmen wie es ihnen zu diesem Zeitpunkt möglich ist.
Betreuung selbständigen Lernens im Sportunterricht — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Betreuung selbständigen Lernens im Sportunterricht», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Bei beiden Autoren sind die angebotenen Beziehungsmöglichkeiten als Anregungen zu verstehen, die sich anhand der Daten bewähren bzw. an ihnen validiert werden müssen.
Für die vorliegende Arbeit ist die Ausdifferenzierung bzw. die Konzeptualisierung der beiden Grounded Theories zum einen auf das Kodierparadigma zurückgegriffen worden, zum andern auch auf die Vorlagen Glasers26F[27].
Tabelle 2 – Formale Kodierfamilien27F [28]nach Glaser (nach Mey und Mruck, 2011, S.37)
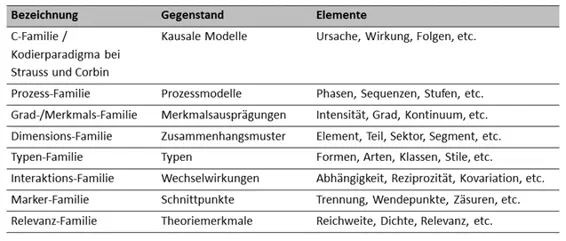
Als wichtigstes integratives Modell wurde die C-Familie bzw. das Kodierparadigma verwendet. Die Darstellung der Theorie anhand kausaler Wirkungszusammenhänge und Einflussfaktoren auf diese Wirkungsketten werden als Übersichten für die jeweiligen Ergebnisse verwendet (vgl. Kapitel 3.2 und 4.2).
Zur Konzeptualisierung der einzelnen Teile der jeweiligen Theorien wurden aber auch weitere Familien im Sinne Glasers verwendet. Z.B. werden in Studie I die Ziele der Schüler hinsichtlich der Reichweite kategorisiert (Relevanz-Familie; vgl. Kapitel 3.2.1.1); die Verantwortungsübernahme für den Problemlöseprozess des Lehrers wird in verschiedenen Graden / Ausprägungen dargestellt (Grad-/Merkmals-Familie; vgl. Kapitel 4.2.2) oder die Ausdifferenzierung der Ressourcen der Schüler in unterschiedliche Formen (Typen-Familie; vgl. Kapitel 3.2.1.2).
Selektives Kodieren
Das selektive Kodieren ist die Zentrierung der Arbeit auf einen integrativen Kern. Hierzu gehört zum einen, dass eine oder mehrere Kategorien ausgewählt und weiter verdichtet werden, von denen erwartet wird, dass sie besonders viele und bedeutsame Verbindungen zu anderen Kategorien haben und dadurch die „Geschichte“ der Theorie erzählen können. Zum anderen werden durch diesen Prozess auch Kategorien ausgeschlossen bzw. in Bezug auf die Verdichtung der Theorie nicht weiter verfolgt.
Während das offene Kodieren und das axiale Kodieren jeweils eigene Funktionen hatten – Benennen und theoretische Verdichtung der Kategorien -, ist das selektive Kodieren kein prinzipiell neues Verfahren. „Integration [selektives Kodieren; J.W.] unterscheidet sich nicht sehr vom axialen Kodieren. Sie wird nur auf einer höheren, abstrakteren Ebene der Analyse durchgeführt.“ (Strauss & Corbin, 1996, S. 95).
Obwohl verschiedene Kategorien auf ihr integratives Potential getestet werden und dann erst eine letztendlichen Festlegung auf eine Kernkategorie erfolgt, wird im Forschungsprozess auch immer wieder zu den Daten zurückgekehrt. „Das selektive Kodieren spielt sich wieder um zwei Pole ab, den Pol des `Er-Findens´ der Geschichte und den der Überprüfung an den Daten. Offensichtlich ist, dass die Theorie sich nicht automatisch aus den Daten ergibt, sondern auf der theoretischen Sensibilität der Forschenden beruht, die aber ihrerseits wieder an den Daten geschärft wird.“ (Berg & Milmeister, 2011, S. 325).
In Studie I erscheint die Kernkategorie „Problemlösen im Sportunterricht“ zunächst nicht unbedingt innovativ, deren detaillierte theoretische Ausarbeitung auf der Mikroebene hat jedoch durchaus Neuigkeitsgehalt im sportpädagogischen Kontext. In Studie II erscheint die „Adaption des Lehrerhandelns in selbständigen Arbeitsphasen“ als Kernkategorie ebenfalls wenig neuwertig, aber auch hier sind die fachbezogene theoretische Konzeptualisierung und insbesondere die strukturelle Anknüpfung an schülerseitige Prozesse neuartig. Auch dass der Fokus in den selbständigen Arbeitsphasen auf diese beiden Phänomene gelegt wird, impliziert Handlungsbedarf für die Lehrerbildung und andere Forschungsfelder (vgl. Kapitel 5).
2.1.3 Aufbereitung des Videodatenpools für die Untersuchung
Im Folgenden wird vor allem in technischer Hinsicht dargestellt, wie die Videodaten in und für die Auswertung aufbereitet wurden28F[29].
Videodaten bieten viele Möglichkeiten, z.B. die Wiederholbarkeit in der Beobachtung und die Dokumentation von nicht-sprachlich indizierten Ereignissen in den untersuchten Videoaufnahmen (vgl. Dinkelaker & Herrle, 2009). Aber sie stellen den Forscher auch vor besondere Herausforderungen. Für die qualitative Auswertung kann insbesondere die Dichte und Reichhaltigkeit von Videodokumenten und die Flüchtigkeit der Szenen zu einer enormen Anstrengung werden, trotz der Reduktion durch Fragestellung und Wahl des Bildausschnittes durch die Kameraführung (vgl. Frankenhauser, 2013).
Um diese Möglichkeiten zu nutzen und sich den Herausforderungen zu stellen, wurde für die Untersuchung ein Weg gewählt, der entlang der dargestellten Kodierverfahren die Daten systematisch im Zuge der Theorieentwicklung reduziert und im Sinne der GTM kodierbar macht.
Als eröffnender Schritt wurde eine beliebig gewählte selbständige Arbeitsphase einer dokumentierten Sportstunde kodiert. Bei der Einteilung der zu kodierenden Segmente wurde der Bedeutungssinn als Kriterium für den Umfang festgelegt. Das bedeutet, dass nicht technische Merkmale, wie Wort, Zeile oder Absatz, per se eingeteilt wurden, sondern dass die Länge eines Segmentes von der Bedeutung des kodierten Ereignisses abhängt29F[30].
Da die direkte Kodierung von Videodokumenten vor allem aufgrund der Ereignisdichte bei der gewählten Mikroperspektive unübersichtlich ist und auch die technischen Möglichkeiten zur direkten Kodierung von Videodaten begrenzt sind30F[31], wurde die entsprechende Sequenz - wie auch später alle kodierten Videodokumente - in Protokolle überführt (vgl. auch Jost, Klug, Schmidt, Neumann-Braun & Reautschnig, 2013). Dabei wurde erstens die gesprochene Sprache transkribiert31F[32] und zweitens wurden als relevant erachtete Beobachtungen32F[33] in das Transkript eingebettet (Beispiele finden sich bei der Auslegung der Ankerbeispiele in den Ergebniskapiteln). Die Verschriftlichung der Beobachtungen war insofern von hoher Bedeutung, da nur hierdurch Ereignisse kodiert werden konnten, die auf nicht-sprachlichen Indikatoren beruhen (z.B. die diagnostische Tätigkeit des Beobachtens, aber auch die Problemlösetätigkeit des Probierens). Die Protokolle wurden innerhalb der Software Atlas.ti (Version 7) mit den Videodaten parallelisiert, so dass die Videos jederzeit zur Auswertung der Protokolle hinzugezogen wurden.
An dieser Stelle sei darauf hingewiesen, dass eine durchgehend standardisierte und extensive Form der Transkription der ursprünglichen Videodaten für die Auswertung im Rahmen dieser Untersuchung aus forschungsmethodischen und gegenstandsspezifischen Gründen nicht gewinnbringend und nicht geboten erschien (vgl. Kapitel 2.1). Beide Gründe begegnen sich in der Beziehung von Auswertungsstrategie und Gegenstandsbeschaffenheit33F[34].
Aufgrund der Forschungsgegenstände der Untersuchung war von Beginn an zu erwarten, dass die zu entwickelnden theoretischen Zusammenhänge nicht alleine durch Transkripte34F[35] zu erfassen sind. Für Studie I, mit dem Fokus auf den Gegenstand des selbständigen Lernens von Schülern im Sportunterricht, war aufgrund des in Kapitel 3.1 skizzierten Gegenstandsverständnisses zu erwarten, dass neben sprachlich-reflexiven Aspekten die Bewegungen der Schüler von Bedeutung sein würden. Gleiches gilt für die Betreuungstätigkeiten der Lehrkräfte, den Gegenstandsbereich von Studie II. Hier war anzunehmen, dass Bewegungen der Lehrkräfte im Sinne einer Vorbildfunktion, aber auch verschiedene Formen des Beobachtens als diagnostische Tätigkeit von Bedeutung sein würden (vgl. Kapitel 4.1). Aufgrund dieser beiden Foki nahm die direkte Beobachtung der Videodaten einen hohen Stellenwert im Auswertungsprozess ein.
Dieser hohe Stellenwert hat sich derart niedergeschlagen, dass für die Auswertung - bzw. die Kodierung - Protokolle angefertigt wurden, die einerseits die Sprache der Akteure dokumentiert, aber andererseits, im Sinne eines Beobachtungsprotokolls, potentiell bedeutsame nicht sprachliche Aspekte aufnimmt35F[36]. Da die direkte Kodierung der Videodaten technisch zum Auswertungszeitpunkt nicht praktikabel war, hatten die Beobachtungsprotokolle eine Brückenfunktion, um relevante sprachliche und nicht sprachliche Aspekte der Videodaten zu kodieren, diese kodierten Segmente über verschiedene Videos hinweg zu vergleichen und letztendlich in den theoretischen Auswertungsphasen in modelbildender Absicht zu integrieren (vgl. Kapitel 2.1.1). Essentieller Bezug des Auswertungsvorgehens sind jedoch letztendlich die Videodaten geblieben; sie wurden bis zuletzt zur Kodierung der Beobachtungsprotokolle immer wieder herangezogen (vgl. Kapitel 2.1.3).
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Betreuung selbständigen Lernens im Sportunterricht»
Представляем Вашему вниманию похожие книги на «Betreuung selbständigen Lernens im Sportunterricht» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Betreuung selbständigen Lernens im Sportunterricht» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.