Naoki Sugimoto - Chemistry and Biology of Non-canonical Nucleic Acids
Здесь есть возможность читать онлайн «Naoki Sugimoto - Chemistry and Biology of Non-canonical Nucleic Acids» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Chemistry and Biology of Non-canonical Nucleic Acids
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Chemistry and Biology of Non-canonical Nucleic Acids: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Chemistry and Biology of Non-canonical Nucleic Acids»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Chemistry and Biology of Non-canonical Nucleic Acids — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Chemistry and Biology of Non-canonical Nucleic Acids», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
2.6.3.4 Kissing-Loop Interaction
Kissing-loop interaction is a basic type loop-loop interaction that causes cross-linkage between different helices, which are located in intrastrand or interstrand ( Figure 2.15). The basic interaction of the kissing loop is formation of base pairing by complementary sequences in the apical loops of two hairpins. Intramolecular kissing complexes have been found in many RNA structures, ranging from transfer RNA (tRNA), in which length is shorter than 100 nucleotides, to ribosomal RNA (rRNA) with more than 1000 nucleotides [31]. The kissing-loop complex is usually stabilized by coaxial stacking of nucleobases included in the interhelical duplex ( Figure 2.15) [32]. On the other hand, even if the sequence in the loop forms only two G·C base pairs without the coaxial stacking, a simplest kissing interaction is observed between hairpins each with a GACG tetraloop [33]. In that case, kissing base pairs are stabilized through cross-strand interactions caused by adjacent adenines in the loop [33].
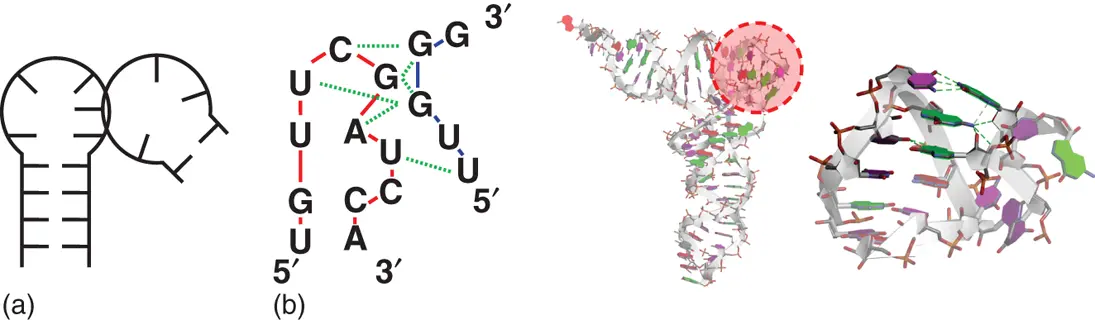
Figure 2.14 T-loop motifs. (a) General secondary structure of T-loop motif consisting of neighboring stem loop and single-stranded regions. (b) Sequence and tertiary structures of yeast phenylalanine-tRNA containing T-loop motif (PDB ID: 1EHZ). Solid lines show sequence connectivity of different RNA regions involved in T-loop motif. Dashed lines show interaction between nucleobases. Enlarged image of T-loop motif surrounded by dashed circle at the overall structure is shown on right.
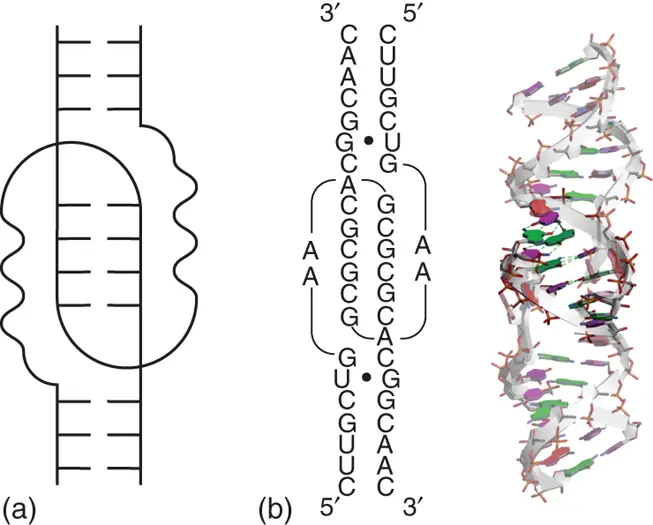
Figure 2.15 Kissing-loop interaction. (a) General secondary structure of kissing-loop interaction. (b) Sequence and tertiary structure of typical kissing-loop interaction (PDB ID: 1XPE). The RNA sequence is derived from dimerization initiation site (DIS) of human immunodeficiency virus type 1 (HIV-1). Nucleobases forming base pairs in kissing-loop region are emphasized dark. Hydrogen bonds between the nucleobases in the kissing-loop region are shown in dashed lines. Mismatched base pairs are shown with black circles in the secondary structure.
2.6.3.5 GNRA Tetraloop Receptor Interaction
GNRA, in which N is any nucleobase and R is purine nucleobase, is one of the two majorities of tetraloop sequences in RNAs. The other majority is UNCG, which contributes to the stabilization of hairpin loop structure, as described above. While GNRA tetraloops are thermodynamically less stable than UNCG tetraloops, they are more common in part because of their propensity to form tertiary interactions [34]. The last three nucleobases in the GNRA tetraloop are exposed to solvent and can interact with minor groove of other helices by forming hydrogen bonds. GAAA/11nt interaction is one of the classic motifs of the GNRA tetraloop interactions, which are observed in long-range interactions in large functional RNAs including rRNA, group I and group II ribozymes, and RNA unit of RNase P. In the GAAA/11nt interaction, a receptor helix has an internal loop with conserved sequence neighboring to consecutive two G·C base pairs. The last two nucleobases of the GAAA tetraloop interact with the consecutive G·C base pairs forming hydrogen bonding as similar way as the A-minor motif. Neighboring internal loop region forms characteristic stacked adenine nucleobases that support the interaction by forming hydrogen bonds with second adenine of the tetraloop ( Figure 2.16).
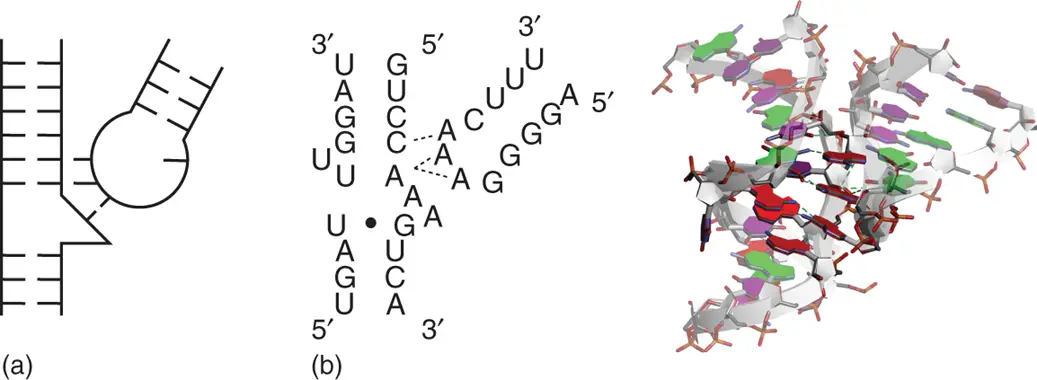
Figure 2.16 Tetraloop receptor interaction. (a) General secondary structure of tetraloop receptor interaction. (b) Sequence and tertiary structure of typical GAAA/11nt tetraloop interaction (PDB ID: 2R8S). The RNA sequence is derived from Tetrahymena group I intron. Nucleobases involved in GAAA tetraloop and its receptor helix are emphasized dark. Hydrogen bonds between the GAAA tetraloop and the receptor helix are shown in dashed lines. Dashed lines in the secondary structure show connections between Watson–Crick base pair in the receptor and nucleobase in the GAAA tetraloop, at which at least one hydrogen bond is observed. Mismatched base pairs are shown with black circles in the secondary structure.
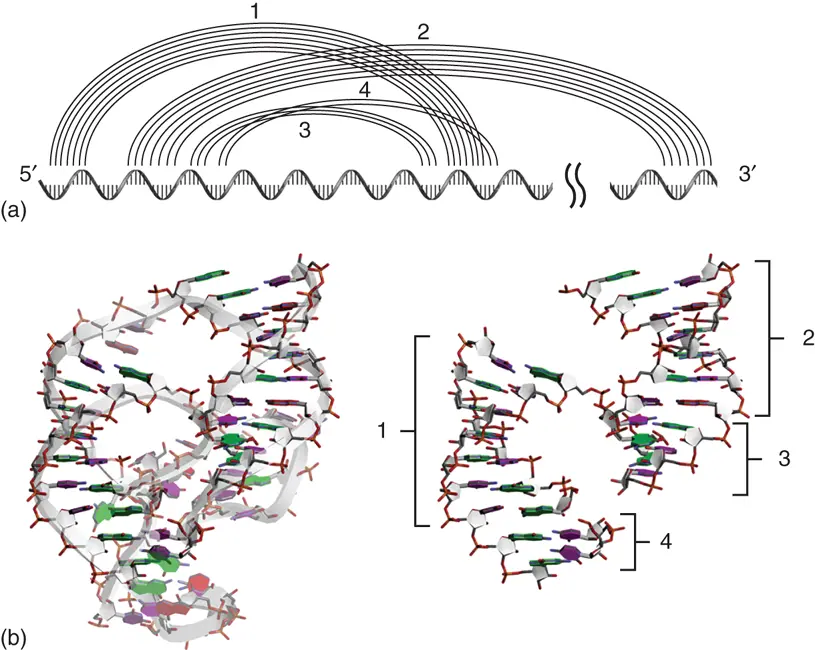
Figure 2.17 Pseudoknot structure. (a) Base pairing patterns on the primary sequence characterizing the pseudoknot structure. Lines show base pairing involved in pseudoknot formation of ribozyme region derived from hepatitis delta virus (HDV). (b) Tertiary structure of the HDV ribozyme precursor (PDB ID: 1SJ3). Extracted stem regions involved in the pseudoknot structure are shown on right. Numbers show the location of stems indicated at (a).
2.6.3.6 Pseudoknot Crosslinking Distant Stem Regions
Pseudoknot is one of the intramolecular tertiary structure motifs characterized by base pairing between the single-stranded regions in a hairpin such as loop and bulge with a region outside of the hairpin ( Figure 2.17) [35]. Based on this definition, irrespective of the distance of nucleobases, it can be regarded as a pseudoknot when a region that is in the middle of the region forming particular stem contributes to the formation of another stem with another RNA region. When long RNA strands such as rRNA and internal ribosome entry site (IRES) form specific structures, pseudoknots are often formed in distant regions. Since the biological functions of pseudoknot are well studied during translation, the detailed structures and their contributions are described in Chapter 7.
2.7 Conclusion
1 Learn interactions in nucleic acid structures.
Nucleobases can adopt syn and anti conformations in their glycosidic bond angle. In addition, in the ribose conformation, there are C2′-end- and C3′-end-type conformations, which are found in the B-form and A-form duplexes, respectively. The flexible feature of the strands allows formation of various base pair patterns and their dynamic fluctuations. In the case of DNA, mismatched base pairs can be formed by incorporation of incorrect substrate during replication reaction. Each mismatched base pair exhibits different thermodynamic stability, in which several types of mismatched base pairs are comparable with standard Watson–Crick base pairs. This is because not only hydrogen bonding between nucleobases but also stacking interactions are important factors that determine the stability.
1 Understand structure polymorphisms of nucleic acids.
Canonical right-handed duplex with Watson–Crick base pairs is one of the polymorphic structures of nucleic acids. DNA varies in its backbone conformation, such as Z-type duplex, multi-stranded helix, and cruciform depending on the primary sequence. In the case of RNA, since the backbone is intrinsically single stranded, it forms a variety of higher-order structures compared with DNA. Various proteins that recognize these non-canonical nucleic acid structures are present in cells. These proteins are usually involved in modulation of gene expression. It is likely that the non-canonical higher-order structures and their polymorphisms play roles in altering the expression of genetic information, whereas the canonical duplex structure plays a role in retaining genetic information. In Chapters 5– 8, reactions of transcription, translation, and replication including telomere region that are affected by the non-canonical nucleic acid structures are described.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Chemistry and Biology of Non-canonical Nucleic Acids»
Представляем Вашему вниманию похожие книги на «Chemistry and Biology of Non-canonical Nucleic Acids» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Chemistry and Biology of Non-canonical Nucleic Acids» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.