Stefan Schneider - Bilingualer Erstspracherwerb
Здесь есть возможность читать онлайн «Stefan Schneider - Bilingualer Erstspracherwerb» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на немецком языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Bilingualer Erstspracherwerb
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Bilingualer Erstspracherwerb: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Bilingualer Erstspracherwerb»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Bilingualer Erstspracherwerb — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Bilingualer Erstspracherwerb», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Die neurolinguistischen Hypothesen von Penfield und Roberts (1959) und Lenneberg (1967) beruhten allein auf Untersuchungen der Auswirkung von Hirnläsionen. In den letzten Jahren ermöglichen jedoch moderne Methoden der neuronalen Bildgebung die Beobachtung des intakten Gehirns (Wahl 2009, 10; Kuhl 2010, 713–715; Li 2013, 221–223). Zwei davon, die funktionelle Magnetresonanztomographie (fMRT) und ereigniskorrelierte Potentiale (EKP), sind besonders bedeutsam. Dank der unterschiedlichen magnetischen Eigenschaften von oxygeniertem und desoxygeniertem Blut machen fMRT-Aufnahmen die Veränderungen der Durchblutung von Hirnarealen sichtbar. Werden Kortexareale aktiviert, kommt es zu einer Erhöhung des Blutflusses aufgrund des gesteigerten Energiebedarfs. Dadurch steigt die Konzentration von oxygeniertem relativ zu desoxygeniertem Hämoglobin. Die räumliche Auflösung ist in der Größenordnung von Millimetern, also sehr präzis. Ereigniskorrelierte Potentiale sind Wellen im Elektroenzephalogramm in der Größenordnung von Millisekunden, die mit neuronaler Aktivität, wie Sinneswahrnehmungen, erhöhte Aufmerksamkeit und Sprachverarbeitung, korrelieren. Allerdings ist der Ursprung der elektrischen Veränderungen schwer neuronal zu lokalisieren, weshalb sich die beiden Methoden hinsichtlich ihrer bildgebenden Möglichkeiten ergänzen (Li 2013, 223). Während man mit der fMRT-Methode ein Hirnareal, in dem eine neuronale Aktivität stattfindet, räumlich genau bestimmen kann, ist die zeitliche Auflösung aufgrund der Langsamkeit der Blutflussveränderungen ungenau. Der zeitliche Ablauf neuronaler Aktivitäten kann besser mit der EKP-Methode erfasst werden.
Ein Maßstab, der in der Forschung zum monolingualen und auch bilingualen Spracherwerb oft eingesetzt wird, ist die durchschnittliche Äußerungslänge (engl. mean length of utterance, MLU). Sie wurde zunächst von Brown (1973) für das amerikanische Englisch entwickelt und seither auch in vielen anderen Sprachen angewendet. Die MLU kann sowohl in Morphemen (MLUm) als auch in Wörtern (MLUw) gemessen werden. Mit Morphem bezeichnet man die kleinste sprachliche Einheit mit einer Bedeutung oder grammatischen Funktion. Die MLUm wird besonders bei der Messung des grammatischen Fortschritts angewendet und hat sich dort bewährt. Warum das so ist, kann man anhand eines einfachen Beispiels verstehen. Ein Wort wie Enten besteht aus zwei Morphemen, dem Stammmorphem Ente und dem Pluralmorphem -n. Wenn nun ein Kind gelegentlich nicht nur das Wort Ente, sondern auch das Wort Enten äußert, darf man annehmen, dass es eine Möglichkeit der Pluralmarkierung erworben hat. Diesem grammatischen Fortschritt wird durch die Berücksichtigung der Morpheme Rechnung getragen. Zur Berechnung der MLUm einer Stichprobe zerlegt man ihre Äußerungen zuerst in Morpheme und dividiert anschließend die Gesamtzahl der Morpheme der Stichprobe durch die Anzahl ihrer Äußerungen. Im Folgenden aus Szagun (2006, 81) stammenden Beispiel wird die MLUm auf der Basis von sieben Äußerungen eines Kindes berechnet:
| (1) Kindliche Äußerungen | Anzahl der Morpheme | |
| *FAL: ab. | 1 | |
| *FAL: fal-‘n. | 2 | |
| *FAL: katze raus. | 2 | |
| *FAL: nichs ab#ge#mach-t. | 5 | |
| *FAL: will d-en. | 3 | |
| *FAL: moecht-e kein-e mau&aeus-e fang-‘n. | 9 | |
| *FAL: da is oben ein boes-er huhu. | 7 | |
| Summe: | 29 Morpheme | |
| MLUm = 29/7 = 4,14 |
Allerdings kann der Grammatikerwerb nur bis zu einer MLUm von ca. 5,0 bis 6,0 abgebildet werden, danach verliert die MLUm an Aussagekraft (Szagun 2006, 83), da die Situationsbedingtheit der Sprache immer mehr an Einfluss gewinnt.
Selbstverständlich ist die Morphemgliederung sprachspezifisch und im Grunde nicht von einer Sprache auf eine andere übertragbar (De Houwer 1990, 15). Abgesehen davon bestehen bei vielen Sprachen unterschiedliche Auffassungen hinsichtlich der Segmentierung in Morpheme. Die konkreten MLUm-Werte können deshalb auch vom theoretischen morphologischen Ansatz abhängig sein. Zusätzlich hängen die MLUm-Werte so wie auch die MLUw-Werte vom Sprachtyp ab. In agglutinierenden Sprachen, in denen fast jede grammatische Kategorie durch ein eigenes Morphem ausgedrückt wird, hat die Anzahl der Morpheme ein anderes Gewicht als in synthetischen Sprachen, in denen mehrere grammatische Kategorien in einem Morphem verpackt auftreten oder grammatische Kategorien durch Allomorphe ausgedrückt werden. In analytischen Sprachen ist hingegen prinzipiell die Anzahl der Wörter pro Äußerung größer als in synthetischen Sprachen.
Im bilingualen Erstspracherwerb wird, weil nur wenige bilinguale Korpora morphologisch codiert sind, zumeist die MLUw als Maßstab angewendet. Die MLUw wird hier in erster Linie benutzt, um ein eventuelles Ungleichgewicht zwischen den Sprachen festzustellen. Yip und Matthews (2007, 76–81) berechnen hierzu die individuellen Unterschiede in der MLUw (MLU differentials) zwischen den beiden Sprachen (Englisch und Kantonesisch) der von ihnen untersuchten Kinder. Wenn man die Variation der MLUw auf eine Zeitachse projiziert, kann man anhand der grafischen Darstellung die Entwicklung der beiden Sprachen nachvollziehen. Bei dieser Darstellung ist nicht so sehr die Variation zwischen den beiden Sprachen relevant, sondern die Variation innerhalb einer Sprache auf der Zeitachse. Wie man an der Abbildung 4erkennen kann, entwickeln sich z. B. die beiden Sprachen von Timmy insgesamt gesehen in etwa gleich weit, obwohl ihre jeweiligen Anfangs- und Endpunkte unterschiedlich sind. Die MLUw von Timmys Englisch macht allerdings bis 2;8 kaum Fortschritte während nach 2;9 ihre Variation in beiden Sprachen vergleichbar ist.
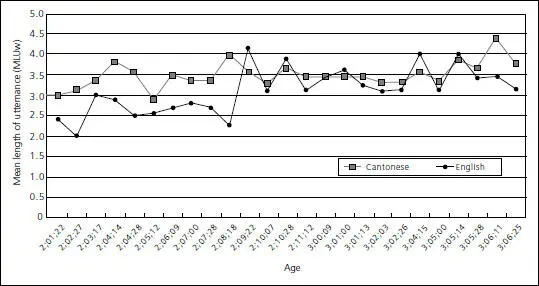
Abb. 4: MLU-Unterschiede bei Timmy (Yip und Matthews 2007, 76)
4 Forschungsüberblick: frühe Studien
4.1 Ronjat (1913)
Anfang des 20. Jahrhunderts entstehen die ersten Studien zur Kindersprache und zum Spracherwerb. Der Sprachwissenschaftler Maurice Grammont (1866–1946) fasst 1902 in einem Aufsatz seine Beobachtungen zur Kindersprache zusammen (Grammont 1902). Das ein paar Jahre später erschienene Buch des Ehepaares Clara (1877–1948) und William (1871–1938) Stern über die Kindersprache (Stern und Stern 1907) stellt einen Höhepunkt in der damaligen Spracherwerbsforschung dar. Nicht lange danach, in der Zeit vor dem Ersten Weltkrieg, erwacht dann das wissenschaftliche Interesse für die frühkindliche Mehrsprachigkeit. Linguisten, Mediziner, Psychologen und Soziologen machen sich zum ersten Mal Gedanken über den Erwerb zweier oder mehrerer Sprachen im Kindesalter und die daraus resultierende frühkindliche Mehrsprachigkeit. Die erste diesbezügliche Studie verdanken wir dem französischen Sprachwissenschaftler und Romanisten Jules Ronjat (1864–1925), der im Jahr 1913 seine Beobachtungen zur Entwicklung seines zweisprachig aufwachsenden Sohnes Louis veröffentlicht. Jules Ronjat bezieht sich in seinem Buch auf Grammont (1902) und Stern und Stern (1907) und vergleicht seine Daten mit denjenigen aus dem monolingualen Erstspracherwerb. Die Studie ist in vieler Hinsicht innovativ und bahnbrechend; sie stellt unter anderem die erste ausführliche Beschreibung des Versuchs dar, ein Kind gemäß der Erwerbskonstellation eine Person → eine Sprache zu erziehen. Interessant ist die Studie noch heute, weil in ihr viele der Themen und Fragestellungen zur Sprache kommen, die in der heutigen Forschung eine zentrale Rolle spielen.
Gleich nach der Einleitung, in einem mit Méthode suivie pour apprendre les deux langues betitelten Kapitel, schreibt Jules Ronjat, er habe kurz nach dem 30. Juli 1908, dem Tag der Geburt seines Sohnes, von seinem Kollegen Maurice Grammont einen Brief mit der folgenden Empfehlung erhalten:
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Bilingualer Erstspracherwerb»
Представляем Вашему вниманию похожие книги на «Bilingualer Erstspracherwerb» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Bilingualer Erstspracherwerb» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.