Christian FG Schendera - Deskriptive Statistik verstehen
Здесь есть возможность читать онлайн «Christian FG Schendera - Deskriptive Statistik verstehen» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на немецком языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Deskriptive Statistik verstehen
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Deskriptive Statistik verstehen: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Deskriptive Statistik verstehen»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Dieses Taschenbuch stellt dazu die Grundlagen und Spielregeln sowie die wichtigsten Maße, Tabellen und Visualisierungen vor. Weitere Themen sind die Datenqualität (u. a. der Umgang mit fehlenden Werten), die Sampling-Theorie (Designstrukturen und Ziehungsarten), das Rechnen mit Gewichten oder auch das Schreiben von Zahlen in Texten.
Zahlreiche Beispiele aus der lehrreichen Welt des Fußballs helfen beim schnellen Verständnis. Kompakte Einführungen in IBM SPSS Statistics und den Enterprise Guide von SAS runden die praktische Anwendung ab.
Deskriptive Statistik verstehen — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Deskriptive Statistik verstehen», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
„Entscheidend is aufm Platz.“
Adi Preißler
Dieses Kapitel geht in Abschnitt 1.1der Frage nach: Was ist deskriptive Statistik? Deskriptive Statistik ist ein Teilbereich der Statistik und darin die regelgeleitete Anwendung eines Methodenkanons auf u.a. numerische oder Textdaten. Das Beherrschen der deskriptiven Statistik ist auch Kompetenz . Anschließend geht Abschnitt 1.2darauf ein, was deskriptive Statistik nicht ist: Deskriptive Statistik ist keine explorative Analyse, konfirmatorische Analyse oder Inferenzstatistik. Deskriptive Statistik kommt auch nicht ohne Qualität und Hintergrundinformation über die Daten aus. Auch ist sie keine Projektionsfläche willkürlicher Auslegungen oder Spielball hemmungslosen Verallgemeinerns.
Die deskriptive Statistik ist ein Teilbereich der Statistik (vgl. Schulze, 2007; von der Lippe, 2006). Als eine allgemeine Definition könnte man die Statistik als die wissenschaftliche Anwendung mathematischer Prinzipien auf die Sammlung, Analyse und Präsentation (alpha)numerischer Daten verstehen. Teilbereiche der Statistik sind u.a. die Theoretische und Mathematische Statistik, darin eingebettet als Unterbereich die Angewandte Statistik (darin die Deskriptive Statistik und Inferenzstatistik) und darin wiederum als Unterbereich eingebettet der Bereich der Datenanalyse mit der explorativen und der konfirmatorischen Analyse.
In der folgenden Abbildung sind Bezüge zur Nachbarin der Statistik, der Wahrscheinlichkeit ausgeschlossen, z.B. bei der Inferenzstatistik (vgl. Mosler & Schmid, 2003), um die Hinführung zur deskriptiven Statistik stromlinienförmig zu gestalten. Anmerkungen zur Wahrscheinlichkeit und der damit verbundenen Unsicherheit (als wahrscheinlichkeitstheoretisches Konzept) sind bei der Deskriptiven Statistik nicht nötig (und aus diesem Grund auch in der eingangs allgemeinen Definition von Statistik nicht erwähnt). Was ist nun eine deskriptive Statistik? Eine erste Antwort ist: ein Methodeninstrumentarium, das auf Daten unabhängig von Erhebung (online, POS, Fragebogen, Interview, Beobachtung, Experiment, Simulation), Studiendesign (Querschnitt, Längsschnitt, Panel usw.), Ziehungsart oder Umfang (Stichprobe, Vollerhebung) angewandt wird. Als weitere Antwort verdeutlicht diese Grafik den Stellenwert der deskriptiven Statistik: Wer die deskriptive Statistik als Teilbereich der angewandten Statistik beherrscht, hat damit auch das Werkzeug für die explorative Datenanalyse (klassisch: Tukey, z.B. 1980, 1977) und auch eine der zentralen Voraussetzungen vor der Durchführung einer inferenzstatistischen Analyse. Die Übergänge zwischen deskriptiver Statistik, explorativer und konfirmatorischer Datenanalyse sowie Inferenzstatistik werden sich dabei (wie so oft) als fließend herausstellen (vgl. Behrens, 1997; Cochran, 1972, 19). Gigerenzer (1999, 606ff.) zählt deskriptive Statistiken zu den wichtigsten Methoden aus der „Werkzeugkiste“ für das Prüfen von Hypothesen. Während Tukey (1977) eine explorative Analyse als „attitude“, als Einstellung, bezeichnet, werden wir hier sagen: Eine deskriptive Statistik ist auch Kompetenz.
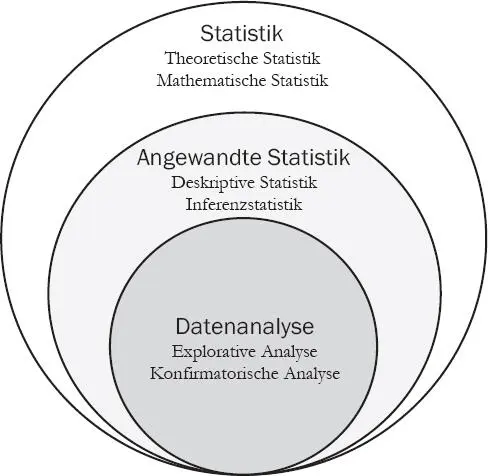
Abb. 1: Die Deskiptive Statistik als Teilbereich der Statistik
1.1 Was ist deskriptive Statistik?
Was ist der Sinn von deskriptiver Statistik? Die deskriptive (auch: darstellende, beschreibende) Statistik ist die Vorstufe und das Fundament jeder professionellen Analyse von Daten. Die deskriptive Statistik ist dabei keineswegs ignorierbar oder trivial. Im Gegenteil, ihre Funktionen sind vielfältig, ihre Maßzahlen sind allgegenwärtig, und ihre Bedeutung kann nicht hoch genug eingeschätzt werden. Die deskriptive Statistik ist die Grundlage und in vielen Fällen die Voraussetzung für den sinnvollen Einsatz der Inferenzstatistik. Je nach Datenart kann sie diese ggf. sogar ersetzen. Eine deskriptive Analyse geht einer professionellen Datenanalyse, sei sie nun inferenzstatistisch oder nicht, immer voraus. Im ersteren Falle gilt: Keine Inferenzstatistik ohne deskriptive Statistik!
Die deskriptive Statistik besitzt zahlreiche wichtige Funktionen:
■ Methoden und Kennziffern: Die grundlegende Funktion der deskriptiven Statistik als Disziplin ist, ein Instrumentarium an Methoden und Kriterien zur statistischen oder visuellen (1) Reduktion von Daten und (2) Beschreibung durch z.B. Kennziffern, Tabellen oder Graphiken bereitzustellen. Die explorative Datenanalyse verwendet meist dieselben Methoden und Kriterien, hat jedoch das Ziel, anhand v.a. visueller Analyse der Daten neue Annahmen und Hypothesen über Strukturen, Ursachen oder Zusammenhänge aufzustellen (vgl. Behrens, 1997). Die im Weiteren beschriebenen Funktionen beziehen sich auf die deskriptive Statistik als Methode .
■ Datenreduktion: Die grundlegende Funktion der deskriptiven Statistik als Methode ist die Datenreduktion , also die Reduktion von unüberschaubaren Mengen an Daten auf wenige, aber überschaubare Kennzahlen, Tabellen oder z.B. Graphiken, und damit auch die Beschreibung durch sie (vgl. auch Ehrenberg, 1986). Das Ziel der deskriptiven Statistik ist nicht der inferentielle Schluss auf eine nicht-verfügbare, hypothetische Grundgesamtheit.
■ Zusammenfassen: Zahlreiche Einzelwerte können in einem einzelnen Wert zusammengefasst werden. Die Anzahl aller Einwohner eines Landes kann z.B. in einem einzigen Summenwert ausgedrückt werden. Auf diese Weise kann eine unübersehbare Menge an Daten übersichtlich aufbereitet werden.
■ Beschreiben: Die Information zahlreicher Einzelwerte kann durch einen einzelnen Wert beschrieben werden. Das durchschnittliche Alter aller Einwohner eines Landes kann z.B. durch einen einzelnen Mittelwert beschrieben werden.
■ Strukturieren: Für das Strukturieren zahlreicher Einzel werte gibt es verschiedene Möglichkeiten: z.B. über Häufigkeitstabellen, Streudiagramme oder Maßzahlen, ggf. zusätzlich unterteilt (aggregiert) nach einer sog. Gruppierungsvariablen. All diese Möglichkeiten können Strukturmerkmale von Daten (also ihrer Verteilung) deutlich machen. Je nach Datenmenge und -verteilung können bestimmte Ansätze geeigneter sein als andere. Bei sehr großen Datenmengen sieht man z.B. bei Graphiken u.U. nur noch „schwarz“. Häufigkeitstabellen geraten oft unübersichtlich. Letztlich verbleiben oft nur (gruppierte) Maßzahlen in Kombination mit Grafiken.
■ Herausheben: Die wesentliche Information soll hervorgehoben werden. Gegebenenfalls erforderliche Vereinfachungen sollen den Informationsgehalt der deskriptiven Statistik so wenig als möglich einschränken. Ein klassisches Beispiel ist z.B., dass bei der Angabe eines Mittelwerts immer auch eine Standardabweichung angegeben werden sollte, um anzuzeigen, ob der Mittelwert tatsächlich die einzelnen Daten angemessen repräsentiert oder ob sie substantiell von ihm abweichen (was eben die mit angegebene Standardabweichung zu beurteilen erlaubt).
■ Grundlegen: Die deskriptive Statistik ist oft die Wirklichkeit hinter innovativ klingenden Verfahren. Googles MapReduce ist z.B. aus der Sicht der deskriptiven Statistik nichts anderes als umfangreiche Freitexte in einzelne Elemente (z.B. Worte) zu zerlegen, diese zu sortieren und abschließend ihre Häufigkeit zu ermitteln. Das Umwandeln des Freitexts in die Wortliste wird als Erzeugen der „Map“ bezeichnet, und das Auszählen und Ersetzen vieler gleicher Worte durch einen Repräsentanten und die dazugehörige Häufigkeit als das „Reduce“. „MapReduce“ mag interessanter klingen als „Auszählen von Zeichenketten“ (vgl. z.B. Schendera, 2005, 133–136 zur Analyse von Text mit SPSS v13). Zentral für das verteilte Text Mining auch sehr großer Datenmengen sind jedoch die Prinzipien der deskriptiven Statistik und die erscheint spätestens jetzt so richtig spannend. Wer weiß, welche Geheimnisse andere Data-Mining-Verfahren verbergen…
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Deskriptive Statistik verstehen»
Представляем Вашему вниманию похожие книги на «Deskriptive Statistik verstehen» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Deskriptive Statistik verstehen» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.