Computational Statistics in Data Science
Здесь есть возможность читать онлайн «Computational Statistics in Data Science» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Computational Statistics in Data Science
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Computational Statistics in Data Science: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Computational Statistics in Data Science»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Computational Statistics in Data Science
Computational Statistics in Data Science
Wiley StatsRef: Statistics Reference Online
Computational Statistics in Data Science
Computational Statistics in Data Science — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Computational Statistics in Data Science», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
(7) 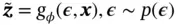
where 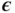 is an auxiliary variable with independent marginal
is an auxiliary variable with independent marginal 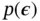 , and
, and 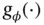 is some vector‐valued function parameterized by
is some vector‐valued function parameterized by 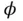 . With this reparameterization trick, the variational lower bound can be estimated by sampling a batch of
. With this reparameterization trick, the variational lower bound can be estimated by sampling a batch of 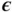 from
from 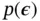 :
:
(8) 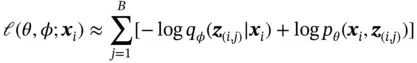
where 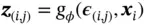 and
and 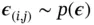 . The selections of
. The selections of 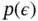 and
and 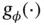 are discussed in detail in Kingma and Welling [17].
are discussed in detail in Kingma and Welling [17].
6 Recurrent Neural Networks
6.1 Introduction
The previously introduced models have the same assumptions on the data, that is, the independence among the samples and the fixed input size. However, these assumptions may not be true in some cases, thus limiting the application of these models. For example, videos can have different lengths, and frames of the same video are not independent, and sentences of an chapter can have different lengths and are not independent.
A RNN is another modified DNN that is used primarily to handle sequential and time series data. In a RNN, the hidden layer of each input is a function of not just the input layer but also the previous hidden layers of the inputs before it. Therefore, it addresses the issues of dependence among samples and does not have any restriction on the input size. RNNs are used primarily in natural language processing applications, such as document modeling and speech recognition.
6.2 Architecture
As illustrated in Figure 7, a general neural network 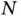 takes in input
takes in input 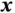 and outputs
and outputs 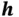 . The output of one sample will not influence the output of another sample. To capture the dependence between inputs, RNN adds a loop to connect the previous information with the current state. The graph on the left side of Figure 8shows the structure of RNN, which has a loop connection to leverage previous information.
. The output of one sample will not influence the output of another sample. To capture the dependence between inputs, RNN adds a loop to connect the previous information with the current state. The graph on the left side of Figure 8shows the structure of RNN, which has a loop connection to leverage previous information.
RNN can work with sequence data, which has input as sequence or target as sequence or both. An input sequence data can be denoted as 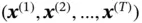 , where each data point
, where each data point 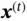 is a real‐valued vector. Similarly, the target sequence can be denoted as
is a real‐valued vector. Similarly, the target sequence can be denoted as 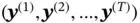 . A sample from the sequence dataset is typically a pair of one input sequence and one target sequence. The right side of Figure 8shows the information passing process. At
. A sample from the sequence dataset is typically a pair of one input sequence and one target sequence. The right side of Figure 8shows the information passing process. At 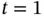 , network
, network 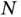 takes in a random initialed vector
takes in a random initialed vector 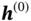 together with
together with 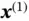 and outputs
and outputs  , and then at
, and then at 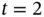 ,
, 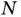 takes in both
takes in both 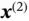 and
and 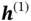 and outputs
and outputs 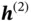 . This process is repeated over all data points in the input sequence.
. This process is repeated over all data points in the input sequence.
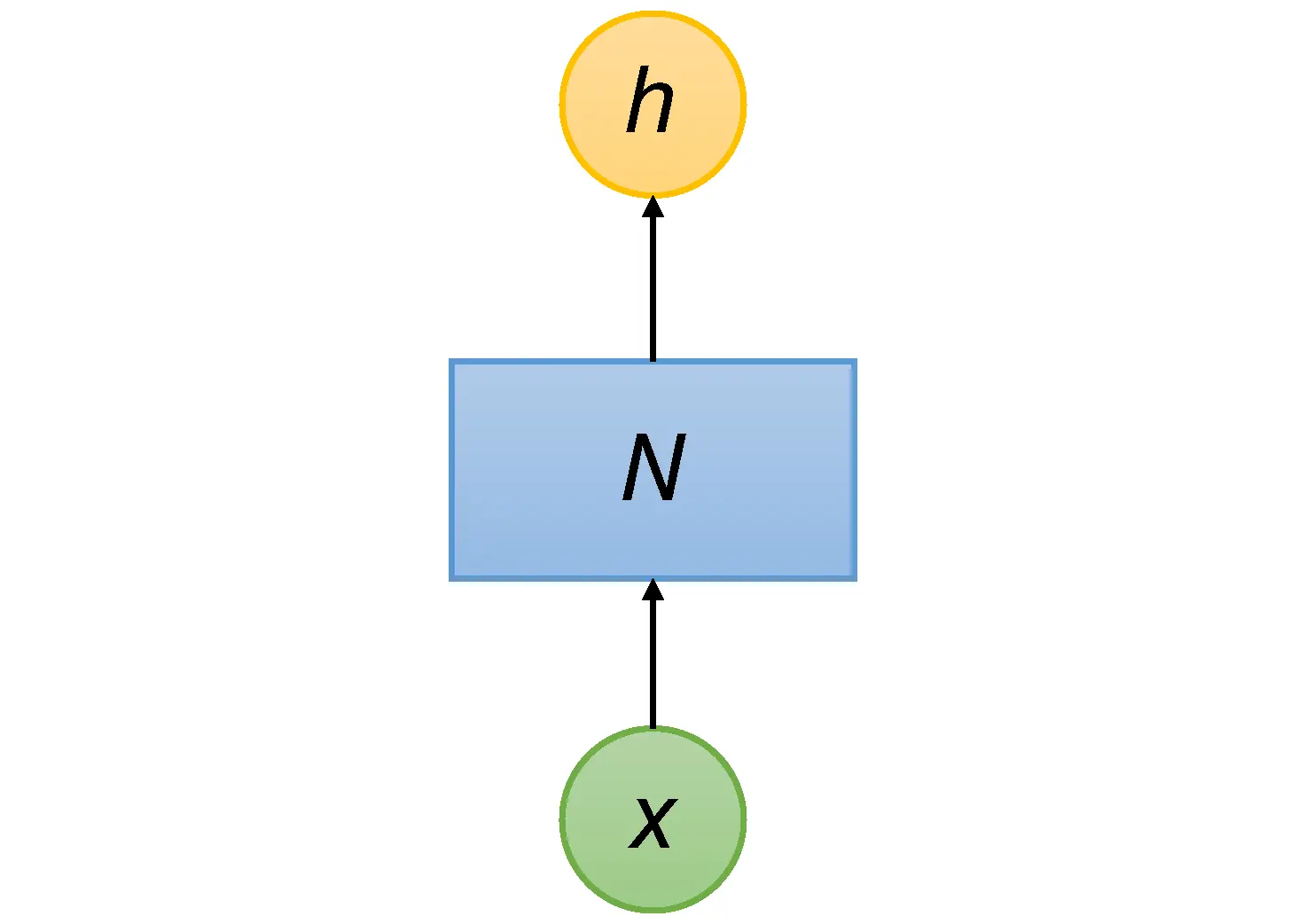
Figure 7 Feedforward network.
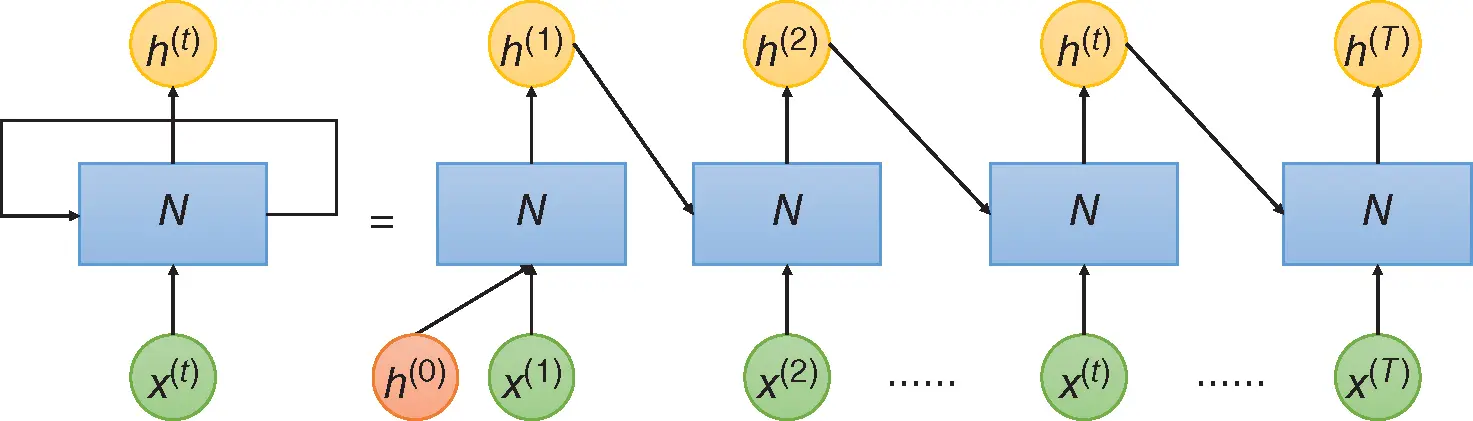
Figure 8 Architecture of recurrent neural network (RNN).
Though multiple network blocks are shown on the right side of Figure 8, they share the same structure and weights. A simple example of the process can be written as
(9) 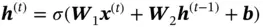
where 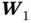 and
and 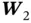 are weight matrices of network
are weight matrices of network 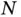 ,
, 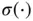 is an activation function, and
is an activation function, and 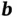 is the bias vector. Depending on the task, the loss function is evaluated, and the gradient is backpropagated through the network to update its weights. For the classification task, the final output
is the bias vector. Depending on the task, the loss function is evaluated, and the gradient is backpropagated through the network to update its weights. For the classification task, the final output 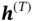 can be passed into another network to make prediction. For a sequence‐to‐sequence model,
can be passed into another network to make prediction. For a sequence‐to‐sequence model,  can be generated based on
can be generated based on 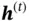 and then compared with
and then compared with 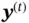 .
.
Интервал:
Закладка:
Похожие книги на «Computational Statistics in Data Science»
Представляем Вашему вниманию похожие книги на «Computational Statistics in Data Science» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.
![Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]](/books/438007/roman-zykov-roman-s-data-science-kak-monetizirova-thumb.webp)











Обсуждение, отзывы о книге «Computational Statistics in Data Science» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.