Computational Statistics in Data Science
Здесь есть возможность читать онлайн «Computational Statistics in Data Science» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Computational Statistics in Data Science
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Computational Statistics in Data Science: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Computational Statistics in Data Science»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Computational Statistics in Data Science
Computational Statistics in Data Science
Wiley StatsRef: Statistics Reference Online
Computational Statistics in Data Science
Computational Statistics in Data Science — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Computational Statistics in Data Science», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
where 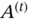 represents other terms in the partial derivative calculation. Since the sigmoid function is used when calculating the values of
represents other terms in the partial derivative calculation. Since the sigmoid function is used when calculating the values of 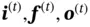 , this implies that they will be close to either 0 or 1. When
, this implies that they will be close to either 0 or 1. When 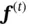 is close to 1, the gradient does not vanish, and when it is close to 0, it means that the previous information is not useful for the current state and should be forgotten.
is close to 1, the gradient does not vanish, and when it is close to 0, it means that the previous information is not useful for the current state and should be forgotten.
7 Conclusion
We discussed the architectures of four types of neural networks and their extensions in this chapter. There have been many other neural networks proposed in the past years, but the ones discussed in this chapter are the classical ones that served as foundations for many other works. Though DNNs have achieved breakthroughs in many fields, the performances in many fields are far from perfect. Developing new architectures that can improve the performances on various tasks or solve new problems is an important research direction. Analyzing the properties and problems of existing architectures is also of great interest to the community.
References
1 1 Larochelle, H., Bengio, Y., Louradour, J., and Lamblin, P. (2009) Exploring strategies for training deep neural networks. J. Mach. Learn. Res., 1, 1–40.
2 2 Hinton, G.E. and Salakhutdinov, R.R. (2006) Reducing the dimensionality of data with neural networks. Science, 313, 504–507.
3 3 Hastie, T., Tibshirani, R., and Friedman, J. (2002) The Elements of Statistical Learning, Springer, New York.
4 4 Boyd, S., Boyd, S.P., and Vandenberghe, L. (2004) Convex Optimization, Cambridge university press.
5 5 Nocedal, J. and Wright, S. (2006) Numerical Optimization, Springer Science & Business Media.
6 6 Izenman, A.J. (2008) Modern multivariate statistical techniques. Regression Classif. Manifold Learn., 10, 978–980.
7 7 Gori, M. and Tesi, A. (1992) On the problem of local minima in backpropagation. IEEE Trans. Pattern Anal. Mach. Intell., 14, 76–86.
8 8 LeCun, Y., Bottou, L., Bengio, Y., and Haffner, P. (1998) Gradient‐based learning applied to document recognition. Proc. IEEE, 86, 2278–2324.
9 9 LeCun, Y. (1998) The MNIST Database of Handwritten Digits, http://yann.lecun.com/exdb/mnist/(accessed 20 April 2021).
10 10 Krizhevsky, A., Sutskever, I., and Hinton, G.E. (2012) Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst., 25, 1097–1105.
11 11 Simonyan, K. and Zisserman, A. (2014) Very deep convolutional networks for large‐scale image recognition. arXiv preprint arXiv:1409.1556.
12 12 He, K., Zhang, X., Ren, S., and Sun, J. (2016) Deep Residual Learning for Image Recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778.
13 13 Goodfellow, I., Bengio, Y., and Courville, A. (2016) Deep Learning, MIT Press.
14 14 Krizhevsky, A. (2009) Learning multiple layers of features from tiny images.
15 15 Bickel, P.J., Li, B., Tsybakov, A.B. et al. (2006) Regularization in statistics. Test, 15, 271–344.
16 16 Rumelhart, D.E., Hinton, G.E., and Williams, R.J. (1986) Learning Internal Representations by Error Propagation. Tech. report. California Univ San Diego La Jolla Inst for Cognitive Science.
17 17 Kingma, D.P. and Welling, M. (2014) Auto‐Encoding Variational Bayes. International Conference on Learning Representations.
18 18 Kullback, S. and Leibler, R.A. (1951) On information and sufficiency. Ann. Math. Stat., 22, 79–86.
19 19 Hochreiter, S. and Schmidhuber, J. (1997) Long short‐term memory. Neural Comput., 9, 1735–1780.
20 20 Gers, F., Schmidhuber, J., and Cummins, F. (1999) Learning to Forget: Continual Prediction with LSTM. 1999 Ninth International Conference on Artificial Neural Networks ICANN 99. (Conf. Publ. No. 470), vol. 2, pp. 850–855.
4 Streaming Data and Data Streams
Taiwo Kolajo1,2, Olawande Daramola3, and Ayodele Adebiyi4
1Federal University Lokoja, Lokoja, Nigeria
2Covenant University, Ota, Nigeria
3Cape Peninsula University of Technology, Cape Town, South Africa
4Landmark University, Omu‐Aran, Kwara, Nigeria
1 Introduction
As at the dawn of 2020, the amount of the world data generated was estimated to be 44 zettabytes (i.e., 40 times more than the number of stars in the observable universe). The amount of data generated daily is projected to be 463 exabytes globally by 2025 [1]. Not only that, data are growing in volume but also in structure, in complexity, and geometrically [2]. These high‐volume data, generated at a high‐velocity, lead to what is called streaming data . Data streams can originate from IoT devices and sensors, spreadsheets, text files, images, audio and video recordings, chat and instant messaging, email, blogs and social networking sites, web traffic, financial transactions, telephone usage records, customer service records, satellite data, smart devices, GPS data, and network traffic and messages.
There are different schools of thought when it comes to defining streaming data and data stream, and it is difficult to situate a position between these two concepts. One school of thought defined streaming data as the act of sending data bit by bit instead of a whole package while data stream is the actual source of data. That is, streaming data is the act, the verb, the action while data stream is the product. In the field of Engineering, streaming data is the process or art of collecting the streamed data. It is the main activity or operation, while data stream is the pipeline through which streaming is performed. It is the engineering architecture, that is the line‐up of tools that will perform the streaming. In the context of data science, streaming data and data streams are used interchangeably. To better understand the concepts, let us first define what a stream is. A stream S is a possibly infinite bag of elements ( x , t ) where x is a tuple belonging to the schema S and t ∈ T is the timestamp of the elements [3]. Data stream refers to an unbounded and ordered sequence of instances of data arriving over time [4]. Data stream can be formally defined as an infinite sequence of tuples S = ( x 1, t i), ( x 2, t 2),…, ( x n, t n),… where x iis a tuple and t iis a timestamp [5]. Streaming data can be defined as frequently changing, and potentially infinite data flow generated from disparate sources [6]. Formally, streaming data 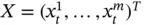 is a set of count values of a variable x of an event that happened at timestamp t (0 < t ≤ T ), where T is the lifetime of the streaming data [7]. Looking at the definitions of both data stream and streaming data in the context of data science, the two concepts are trickily similar. All the different schools of thought slightly agree with these slightly confusing and closely related concepts except for the Engineering school of thought that refers to data stream as an architecture. Although this is still left open for further exploration, we will use them interchangeably in this chapter.
is a set of count values of a variable x of an event that happened at timestamp t (0 < t ≤ T ), where T is the lifetime of the streaming data [7]. Looking at the definitions of both data stream and streaming data in the context of data science, the two concepts are trickily similar. All the different schools of thought slightly agree with these slightly confusing and closely related concepts except for the Engineering school of thought that refers to data stream as an architecture. Although this is still left open for further exploration, we will use them interchangeably in this chapter.
Интервал:
Закладка:
Похожие книги на «Computational Statistics in Data Science»
Представляем Вашему вниманию похожие книги на «Computational Statistics in Data Science» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.
![Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]](/books/438007/roman-zykov-roman-s-data-science-kak-monetizirova-thumb.webp)











Обсуждение, отзывы о книге «Computational Statistics in Data Science» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.