Computational Statistics in Data Science
Здесь есть возможность читать онлайн «Computational Statistics in Data Science» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Computational Statistics in Data Science
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Computational Statistics in Data Science: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Computational Statistics in Data Science»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Computational Statistics in Data Science
Computational Statistics in Data Science
Wiley StatsRef: Statistics Reference Online
Computational Statistics in Data Science
Computational Statistics in Data Science — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Computational Statistics in Data Science», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
However, a drawback of RNN is that it has problem “remembering” remote information. In RNN, long‐term memory is reflected in the weights of the network, which memorizes remote information via shared weights. Short‐term memory is in the form of information flow, where the output from the previous state is passed into the current state. However, when the sequence length 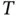 is large, the optimization of RNN suffers from vanishing gradient problem. For example, if the loss
is large, the optimization of RNN suffers from vanishing gradient problem. For example, if the loss  is evaluated at
is evaluated at 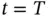 , the gradient w.r.t.
, the gradient w.r.t. 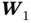 calculated via backpropagation can be written as
calculated via backpropagation can be written as
(10) 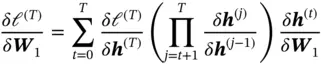
where 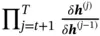 is the reason for the vanishing gradient. In RNN, the tanh function is commonly used as the activation function, so
is the reason for the vanishing gradient. In RNN, the tanh function is commonly used as the activation function, so
(11) 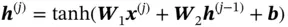
Therefore, 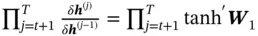 , and
, and  is always smaller than 1. When
is always smaller than 1. When 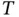 becomes larger, the gradient will get closer to zero, making it hard to train the network and update the weights with remote information. However, it is possible that relevant information is far apart in the sequence, so how to leverage remote information of a long sequence is important.
becomes larger, the gradient will get closer to zero, making it hard to train the network and update the weights with remote information. However, it is possible that relevant information is far apart in the sequence, so how to leverage remote information of a long sequence is important.
6.3 Long Short‐Term Memory Networks
To solve the problem of losing remote information, researchers proposed long short‐term memory (LSTM) networks. The idea of LSTM was introduced in Hochreiter and Schmidhuber [19], but it was applied to recurrent networks much later. The basic structure of LSTM is shown in Figure 9. It solves the problem of the vanishing gradient by introducing another hidden state 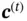 , which is called the cell state.
, which is called the cell state.
Since the original LSTM model was introduced, many variants have been proposed. Forget gate was introduced in Gers et al . [20]. It has been proven effective and is standard in most LSTM architectures. The forwarding process of LSTM with a forget gate can be divided into two steps. In the first step, the following values are calculated:
(12) 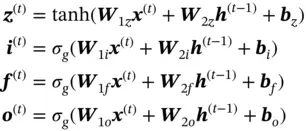
where 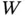 and
and  are weight matrix and bias, and
are weight matrix and bias, and 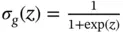 is the sigmoid function.
is the sigmoid function.
The two hidden states 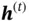 and
and 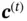 are calculated by
are calculated by
(13) 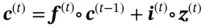
(14) 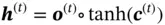
where 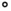 represents elementwise product between matrices. In Equation ( 13), the first term multiplies
represents elementwise product between matrices. In Equation ( 13), the first term multiplies 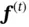 with
with 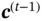 , controlling what information in the previous cell state can be passed to the current cell state. As for the second term,
, controlling what information in the previous cell state can be passed to the current cell state. As for the second term, 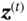 stores the information passed from
stores the information passed from 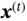 and
and 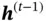 , and
, and  controls how much information from the current state is preserved in the cell state. The hidden state
controls how much information from the current state is preserved in the cell state. The hidden state 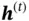 depends on the current cell state and
depends on the current cell state and 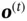 , which decides how much information from the current cell state will be passed to the hidden state
, which decides how much information from the current cell state will be passed to the hidden state 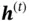 .
.
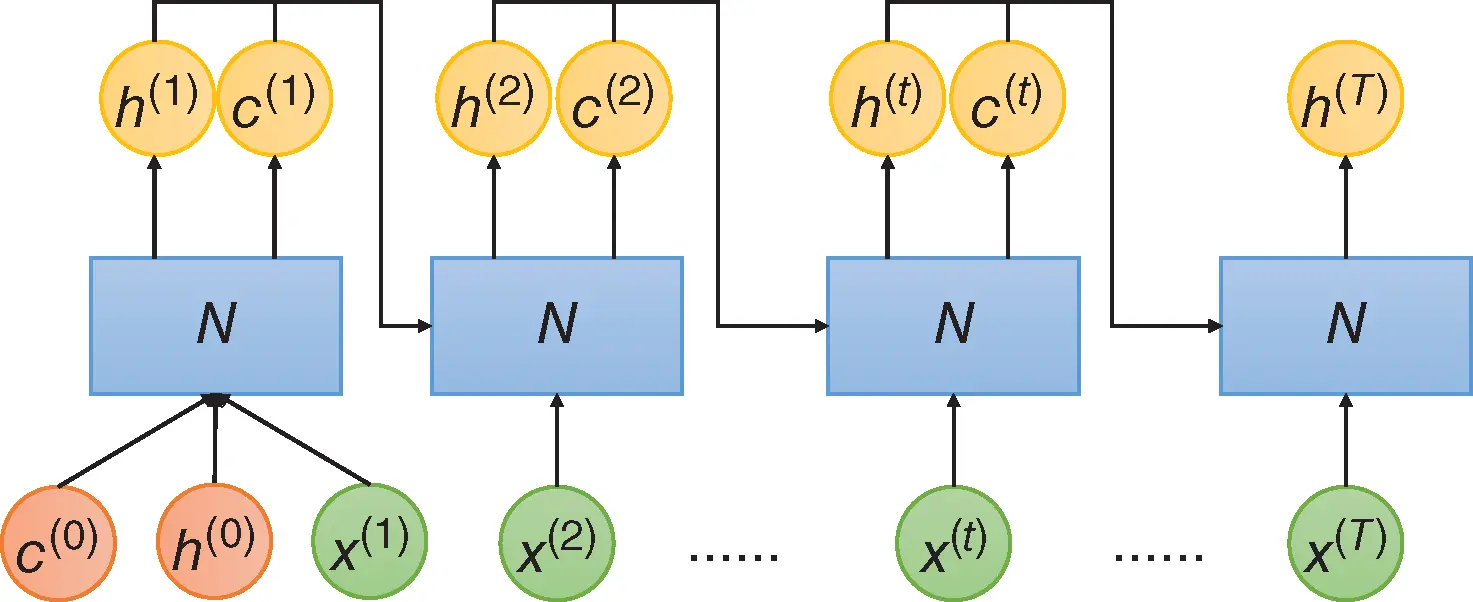
Figure 9 Architecture of long short‐term memory network (LSTM).
In LSTM, if the loss 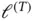 is evaluated at
is evaluated at  , the gradient w.r.t.
, the gradient w.r.t. 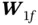 calculated via backpropagation can be written as
calculated via backpropagation can be written as
(15) 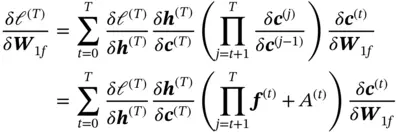
Интервал:
Закладка:
Похожие книги на «Computational Statistics in Data Science»
Представляем Вашему вниманию похожие книги на «Computational Statistics in Data Science» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.
![Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]](/books/438007/roman-zykov-roman-s-data-science-kak-monetizirova-thumb.webp)











Обсуждение, отзывы о книге «Computational Statistics in Data Science» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.