Computational Statistics in Data Science
Здесь есть возможность читать онлайн «Computational Statistics in Data Science» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Computational Statistics in Data Science
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Computational Statistics in Data Science: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Computational Statistics in Data Science»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Computational Statistics in Data Science
Computational Statistics in Data Science
Wiley StatsRef: Statistics Reference Online
Computational Statistics in Data Science
Computational Statistics in Data Science — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Computational Statistics in Data Science», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Table 1 Streaming data versus static data [9, 10]
| Dimension | Streaming data | Static data |
|---|---|---|
| Hardware | Typical single constrained measure of memory | Multiple CPUs |
| Input | Data streams or updates | Data chunks |
| Time | A few moments or even milliseconds | Much longer |
| Data size | Infinite or unknown in advance | Known and finite |
| Processing | A single or few pass over data | Processes in multiple rounds |
| Storage | Not store or store a significant portion in memory | Store |
| Applications | Web mining, traffic monitoring, sensor networks | Widely adopted in many domains |
Source : Tozi, C. (2017). Dummy's guide to batch vs streaming. Retrieved from Trillium Software, Retrieved from http://blog.syncs ort.com/2017/07/bigdata/;Kolajo, T., Daramola, O. & Adebiyi, A. (2019). Big data stream analysis: A systematic literature review, Journal of Big Data 6(47).
The ocean of streaming data continuously generated through various mediums such as sensors, ATM transactions, and the web is tremendously increasing, and recognizing patterns in these mediums is equally challenging [8]. Most methods used for data stream mining are adapted from techniques designed for a finite or static dataset. Data stream mining imposes a high number of constraints on canonical algorithms. To quickly appreciate these constraints, the differences between static and streaming scenarios are presented in Table 1.
In the big data era, data stream mining serves as one of the vital fields. Since streaming data is continuous, unlimited, and with nonuniform distribution, there is the need for efficient data structures and algorithms to mine patterns from this high volume, high traffic, often imbalanced data stream that is also plagued with concept drift [11].
This chapter intends to broaden the existing knowledge in the domain of data science, streaming data, and data streams. To do this, relevant themes including data stream mining issues, streaming data tools and technologies, streaming data pre‐processing, streaming data algorithms, strategies for processing data streams, best practices for managing data streams, and suggestions for the way forward are discussed in this chapter. The structure of the rest of this chapter is as follows. Section 2presents a brief background on data stream computing; Section 3discusses issues in data stream mining, tools, and technologies for data streaming are presented in Sections 4while streaming data pre‐processing is discussed in Section 5. Sections 6and 7present streaming data algorithms and data stream processing strategies, respectively. This is followed by a discussion on best practices for managing data streams in Section 8, while the conclusion and some ideas on the way forward are presented in Section 9.
2 Data Stream Computing
Data stream computing alludes to the real‐time processing of vast measures of data produced at high speed from numerous sources, with different schemas, and different temporal resolutions [12]. It is another required worldview given the new wellsprings of data‐generation situations, which incorporates the cell phones, ubiquity of location services, and sensor universality [13].
The principal presumption of stream computing is that the likelihood estimation of data lies in its newness. Thus, the analysis of data is done the moment they arrive in a stream instead of what obtains in batch processing where data are first stored before they are analyzed. This is a serious requirement for suitable platforms for scalable computing with parallel architectures [14]. With stream computing, it is feasible for organizations to analyze and respond to speedily changing data in real‐time [15]. Integrating streaming data into the decision‐making process brings about a programming concept called stream computing . Stream processing solutions ought to have the option to deal with the high volume of data from different sources in real‐time by giving due consideration to accessibility, versatility, and adaptation to noncritical failure. Datastream analysis includes the ingestion of data as a boundless tuple, analysis, and creation of significant outcomes in a stream [16].
In a stream processor, the representation of an application is done with the data flow graph, which is comprised of operations and interconnected streams. A stream processing workflow consists of programs. Formally, a composition 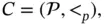 where
where 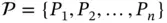 is a set of transaction programs and < pis the program order, also called partial order . The partial order contains the dataflow and control order of the data stream. The composition graph
is a set of transaction programs and < pis the program order, also called partial order . The partial order contains the dataflow and control order of the data stream. The composition graph  is the acyclic graph representing the partial order. Input streams to the composition are called source streams, while the output streams are called derived streams [17]. In a streaming analytics system, the application comes as continuous queries, data are continuously ingested, analyzed, and interrelated to produce results in streaming fashion. Streaming analytics frameworks must be able to recognize new data, build models incrementally, and detect deviation from model predictions [18].
is the acyclic graph representing the partial order. Input streams to the composition are called source streams, while the output streams are called derived streams [17]. In a streaming analytics system, the application comes as continuous queries, data are continuously ingested, analyzed, and interrelated to produce results in streaming fashion. Streaming analytics frameworks must be able to recognize new data, build models incrementally, and detect deviation from model predictions [18].
3 Issues in Data Stream Mining
One of the challenges of data stream mining is concept drift. Concept drift is a phenomenon that bothers on how data stream evolves [19]. The presence of concept drift affects the fundamental characteristics that the learning system seeks to uncover, thus leading to degraded results by the classifier as the change progresses [20].
Concept drift in data stream can be broadly classified into two main categories, which are concept drift based on classification boundaries and concept drift concerning types of change. The former influences the classification boundaries and can be further subdivided into virtual concept drift and real concept drift. Virtual concept drift affects the conditional probability density functions, though the influence on the decision boundary is insignificant on the currently used learning models. On the other hand, real concept drift often impacts the unconditional probability density functions, leading to degraded results of the learning models. Concept drift concerning change is subdivided into sudden, gradual, and incremental concept drift. Other categories based on types of change include blip, noise, mixed, local, global, feature, and adversarial concept drifts [21]. The taxonomy of concept drift is presented in Figure 1.
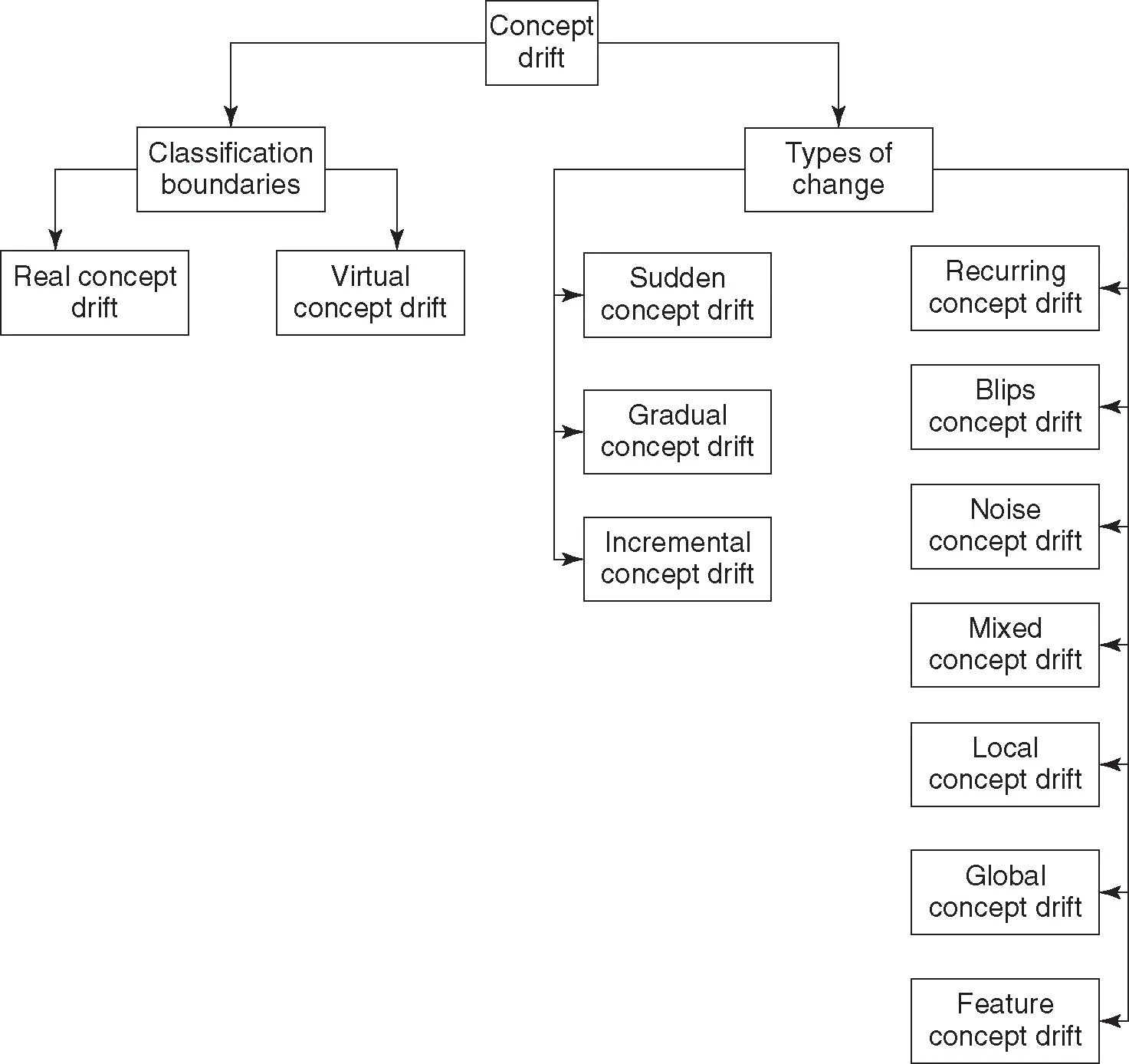
Figure 1 Taxonomy of concept drift in data stream.
Three standard solutions to address concept drift are (i) to detect changes and retrain classifiers when the degree of changes is significantly high, (ii) retraining of the classification model at the arrival of a new chunk or instance, and (iii) the use of adaptive learning methods. However, option number 2 is practically not feasible due to computational cost. The four main approaches for addressing concept drift are (i) concept drift detectors [22], (ii) sliding windows [23], (iii) online learners [24], (iv) and ensemble learners [25]. Other challenges for data stream are briefly highlighted below.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Computational Statistics in Data Science»
Представляем Вашему вниманию похожие книги на «Computational Statistics in Data Science» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.
![Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]](/books/438007/roman-zykov-roman-s-data-science-kak-monetizirova-thumb.webp)











Обсуждение, отзывы о книге «Computational Statistics in Data Science» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.