Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
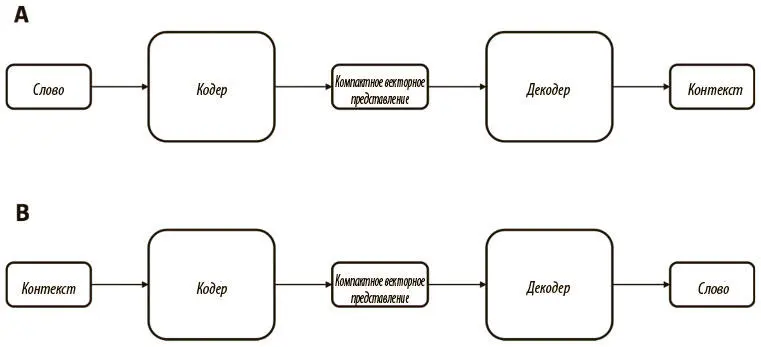
Рис. 6.19. Общие архитектуры разработки кодеров и декодеров, которые генерируют компактные векторные представления, связывая слова с их контекстами (А) или наоборот (В)
В следующем разделе мы расскажем, как применить эту стратегию (с небольшими улучшениями), чтобы получить компактные векторные представления слов на практике.
Технология Word2Vec
Word2Vec, технология генерации компактных векторных представлений слов, разработана Томашем Миколовым и его коллегами. В их работе приводились две стратегии генерации представлений, очень похожие на стратегии кодирования контекста, о которых мы говорили в предыдущем разделе.
Первый алгоритм Word2Vec, который ввели Миколов и коллеги, назывался моделью «непрерывного мешка со словами» ( Continuous Bag of Words (CBOW)) [78]. Эта модель во многом напоминает стратегию В из предыдущего раздела.
CBOW при помощи кодера создает плотное векторное представление из полного контекста (который рассматривается как единица входных данных) и предсказывает целевое слово. Как выяснилось, она лучше всего работает на небольших наборах данных, о чем говорилось в исходной статье.
Второй алгоритм Word2Vec — модель Skip-Gram , тоже предложенная Миколовым и коллегами [79]. Это инвертированный вариант CBOW: используя текущее слово, она пытается предсказать одно из слов контекста. Рассмотрим на примере, как выглядит набор данных для Skip-Gram.
Возьмем предложение The boy went to the bank. Разобьем его на пары (контекст, цель) и получим [([the, went], boy), ([boy, to], went), ([went, the], to), ([to, bank], the)]. Теперь каждую пару (контекст, цель) нужно разбить на пары (вход, выход), где вход — цель, а выход — одно из слов из контекста. Из первой пары ([the, went], boy) получаем (boy, the) и (boy, went). Продолжая применять эти операции к каждой паре (контекст, цель), мы получим набор данных. Наконец, мы меняем каждое слово его уникальным индексом i ∈ {0, 1, …, | V | — 1}, соответствующим индексу в словаре.
Структура кодера удивительно проста. По сути, это таблица соответствия с V рядов, из них i -й — компактное векторное представление, соответствующее i -му слову словаря. Кодеру достаточно взять индекс входящего слова и вернуть соответствующий ряд из таблицы. Это эффективная операция, на GPU она может быть представлена в виде умножения транспонированной таблицы и прямого унитарного вектора, представляющего входное слово. Это легко реализуется в TensorFlow при помощи следующей функции:
tf.nn.embedding_lookup(params, ids, partition_strategy='mod', name=None, validate_indices=True),
где params — матрица плотных векторных представлений, а ids — тензор индексов, которые мы ищем. Подробную информацию о дополнительных параметрах можно найти в документации TensorFlow API [80].
Декодер сложнее, поскольку мы внесем несколько изменений для повышения производительности. Наивный вариант — попытаться воссоздать прямой унитарный кодирующий вектор для выходного значения, который можно реализовать в обычном слое с прямым распространением сигнала, дополненном слоем с функцией мягкого максимума. Но это неэффективно, поскольку придется рассчитывать распределение вероятности по всему пространству словаря.
Чтобы сократить число параметров, Миколов и коллеги воспользовались иной стратегией реализации декодера с названием «шумно-контрастная оценка» (noise-contrastive estimation, NCE). Эта стратегия показана на рис. 6.20.
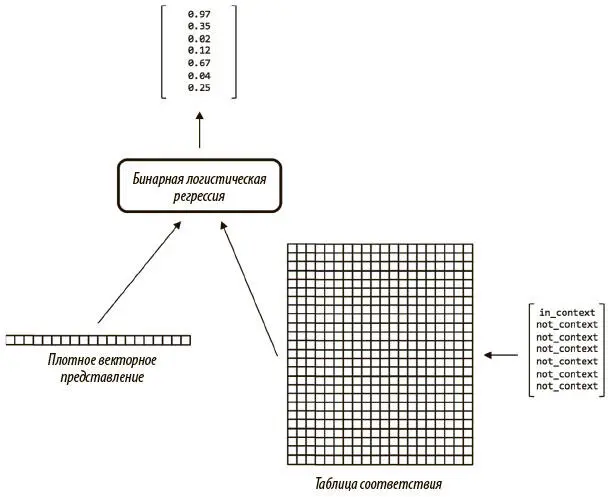
Рис. 6.20. Иллюстрация работы шумно-контрастной оценки. Бинарная логистическая регрессия сравнивает представление целевого слова с представлением слова из контекста и случайным образом выбранных неконтекстных слов. Строим функцию потерь, которая описывает, насколько эффективно векторное представление позволяет распознать слова в контексте целевого по отношению к словам вне контекста
В стратегии NCE таблица соответствия используется для того, чтобы найти плотное векторное представление для выходного слова, а также представлений для случайно выбранных из словаря слов, отсутствующих в контексте входного. Применяем модель бинарной логистической регрессии, которая поочередно берет представление входного слова и выходного либо случайно выбранного и выдает значение от 0 до 1, показывающее вероятность того, что сравниваемое представление относится к слову, присутствующему в контексте входного. Берем сумму вероятностей, соответствующих неконтекстным сравнениям, и вычитаем вероятность, сопоставленную контекстному сравнению.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.