Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Мы выяснили, как использовать автокодеры для нахождения хороших представлений точек данных, выбирая основные характеристики их содержания. Такой механизм сокращения размерности эффективен, когда независимые точки данных содержательны — обладают всей релевантной информацией, относящейся к их структуре во входном представлении. Далее мы рассмотрим стратегии, которые можно использовать, когда основной источник информации — контекст точек данных, а не они сами.
Когда контекст информативнее, чем входной вектор данных
В предыдущих разделах мы в основном занимались вопросом сокращения размерности. В этом процессе обычно имеются богатые входные данные, содержащие много шума, который и нужно отделить от ключевой, структурной информации. Нам требуется выделить эту информацию, игнорируя вариации и шум, которые затрудняют фундаментальное понимание данных.
В других ситуациях представления входных данных очень мало говорят о содержании, которое мы пытаемся вычленить. Тогда наша цель — не извлечь информацию, а выбрать ее из контекста для создания полезных представлений.
Возможно, пока эти рассуждения кажутся слишком абстрактными, так что перейдем к конкретике и реальным примерам.
Построение моделей для естественного языка — задача очень сложная. Первая проблема, которую предстоит решить при построении языковых моделей, — как найти хороший способ представления отдельных слов. На первый взгляд не вполне понятно, как же создать хорошее представление. Начнем с наивного подхода, пример которого приведен на рис. 6.17.
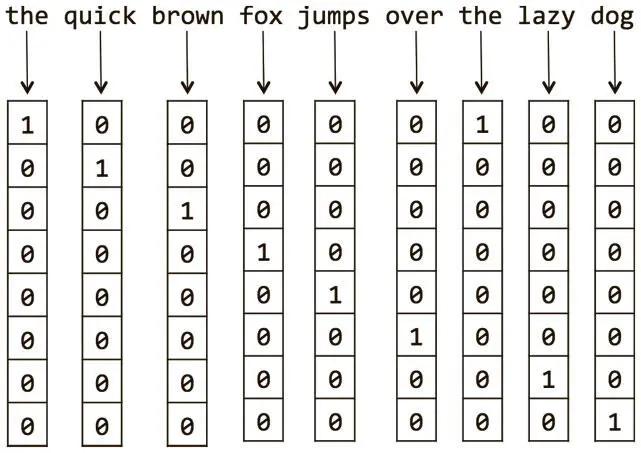
Рис. 6.17. Пример генерации прямых унитарных векторных представлений слов для простого документа
Если словарь документа равен V и насчитывает | V | слов, мы можем представить их в виде прямых унитарных векторов. У нас будут | V |-мерные векторы представления, и каждое слово будет ассоциироваться с индексом в этом векторе. Для представления уникального слова w i мы задаем для i -го компонента вектора значение 1, а для всех остальных — 0.
Но такая схема представления выглядит почти случайной. Векторизация не преобразует похожие слова в похожие векторы. И это проблема, ведь мы хотим, чтобы наши модели понимали, что слова jump и leap («прыгать» и «скакать») очень похожи по значению, и умели различать часть речи: например, глагол, существительное и предлог.
Примитивная прямая унитарная векторная кодировка слов не сохраняет ни одной из этих характеристик. Нужно найти какие-то способы выявления таких отношений и векторного кодирования этой информации.
Оказывается, отношения между словами можно определить с помощью анализа контекста. Например, такие синонимы, как jump и leap, часто взаимозаменяемы в одном и том же контексте. И оба обычно применяются, когда субъект совершает действие над прямым объектом. Этим принципом мы будем руководствоваться всегда, сталкиваясь с новым словом. Например, прочтя предложение «Милитарист спорил с толпой», мы можем сразу сделать кое-какие выводы по поводу слова «милитарист», даже не зная его значения. В этом контексте оно предшествует глаголу; это позволяет предположить, что «милитарист» — существительное и подлежащее в предложении.
Идем дальше. «Милитарист» «спорил», отсюда логично заключить, что это некто агрессивный или скандальный. И мало-помалу, как показано на рис. 6.18, анализ контекста (фиксированного окна слов, окружающего искомое) позволяет быстро установить значение слова.
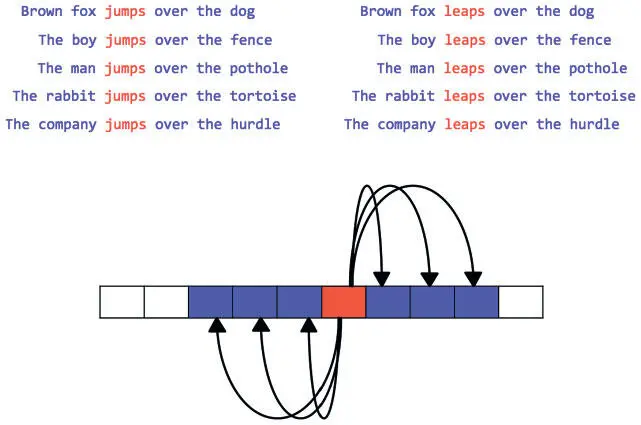
Рис. 6.18. На основе контекста можно определить слова со схожими значениями. Например, jumps и leaps должны иметь сходное векторное представление, поскольку почти взаимозаменяемы. Можно даже сделать выводы об их значениях, просто посмотрев на окружающие их слова
Оказывается, основания, которыми мы руководствовались при создании автокодера, можно применить и здесь, построив сеть, которая создает мощные, распределенные представления. Две основные стратегии показаны на рис. 6.19. Один из возможных методов (рис. А) передает целевое слово по кодирующей сети, которая создает плотное векторное представление. Затем последнее принимается декодирующей сетью, но она не пытается воссоздать исходное значение, как в автокодере, а стремится подобрать слово по контексту. Второй возможный метод (рис. В) строго обратный: кодер берет слово из контекста как входные данные, порождая целевое слово.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.