Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
sess = tf.Session()
train_writer = tf.train.SummaryWriter("skipgram_logs/", graph=sess.graph)
init_op = tf.initialize_all_variables()
sess.run(init_op)
step = 0
avg_cost = 0
for epoch in xrange(training_epochs):
for minibatch in xrange(batches_per_epoch): step +=1
mbatch_x, mbatch_y = data.generate_batch(batch_size, num_skips, skip_window)
feed_dict = {x: mbatch_x, y: mbatch_y}
_, new_cost, train_summary = sess.run([train_op, cost, summary_op] feed_dict=feed_dict)
train_writer.add_summary(train_summary, sess.run(global_step))
# Compute average loss
avg_cost += new_cost/display_step
if step % display_step == 0:
print "Elapsed: ", str(step), "batches. Cost =",
"{:.9f}".format(avg_cost)
avg_cost = 0
if step % val_step == 0:
_, similarity = sess.run(val_op)
for i in xrange(val_size):
val_word = data.reverse_dictionary
[val_examples[i]]
neighbors = (-similarity[i,]). argsort()
[1:top_match+1]
print_str = "Nearest neighbor of
%s:"
% val_word
for k in xrange(top_match):
print_str += " %s," %
data.reverse_dictionary[neighbors[k]]
print print_str[:-1]
final_embeddings, _ = sess.run(val_op)
Код начинает работу, а мы наблюдаем за развитием модели во времени. Сначала она плохо создает плотные векторные представления (что очевидно на шаге проверки). Однако к окончанию обучения модель явно находит представления, которые верно отражают значения отдельных слов:
ancient: egyptian, cultures, mythology, civilization, etruscan, greek, classical, preserved
however: but, argued, necessarily, suggest, certainly, nor, believe, believed
type: typical, kind, subset, form, combination, single description, meant
white: yellow, black, red, blue, colors, grey, bright, dark
system: operating, systems, unix, component, variant, versions, version, essentially
energy: kinetic, amount, heat, gravitational, nucleus, radiation, particles, transfer
world: ii, tournament, match, greatest, war, ever, championship, cold
y: z, x, n, p, f, variable, mathrm, sum,
line: lines, ball, straight, circle, facing, edge, goal, yards,
among: amongst, prominent, most, while, famous, particularly, argue, many
image: jpg, jpg, width, images, gallery, aloe, gif, angel
kingdom: states, turkey, britain, nations, islands, namely, ireland, rest
long: short, narrow, thousand, just, extended, span, length, shorter
through: into, passing, behind, capture, across, when, apart, goal
i: you, t, know, really, me, want, myself, we
source: essential, implementation, important, software, content, genetic, alcohol, application
because: thus, while, possibility, consequently, furthermore, but, certainly, moral
eight: six, seven, five, nine, one, four, three, b
french: spanish, jacques, pierre, dutch, italian, du, english, belgian
written: translated, inspired, poetry, alphabet, hebrew, letters, words, read
Хотя результаты не идеальны, некоторые кластеры очень удачны. В одном оказались числа, страны и культурные явления. Местоимение I («я») попало к другим местоимениям. Слово world («мир») забавным образом оказалось рядом с championship («чемпионат») и war («война»). А written («письменный») попало по соседству с translated («переведенный»), poetry («поэзия»), alphabet («алфавит»), letters («буквы») и words («слова»). Закончить раздел мы хотим визуализацией плотных векторных представлений слов на рис. 6.21.
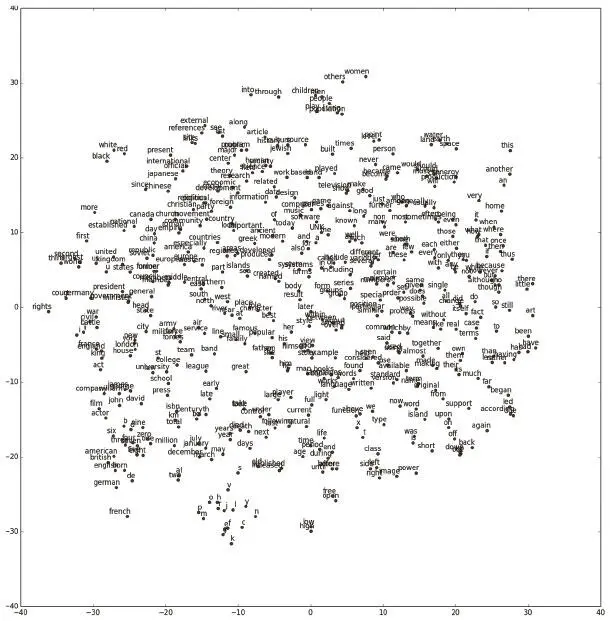
Рис. 6.21. Визуализация наших представлений Skip-Gram при помощи t-SNE. Отмечаем, что близкие понятия действительно расположены ближе, чем разрозненные. Это показывает, что наши представления содержат значимую информацию о функциях и определениях отдельных слов
Чтобы отобразить 128-мерные представления в двумерном пространстве, воспользуемся методом визуализации t-SNE. Если помните, мы использовали t-SNE и в главе 5для визуализации отношений между изображениями в ImageNet. Пользоваться им несложно, этот метод имеет встроенную функцию в общепринятой библиотеке машинного обучения scikitlearn. Визуализацию можно создать при помощи следующего кода:
tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)
plot_embeddings = np.asfarray(final_embeddings[: plot_num,], dtype='float')
low_dim_embs = tsne.fit_transform(plot_embeddings)
labels = [reverse_dictionary[i] for i in xrange(plot_only)]
data.plot_with_labels(low_dim_embs, labels)
Более подробное объяснение свойств плотных векторных представлений слов и интересных шаблонов (времена глаголов, страны и столицы, завершение аналогии и т. д.) любознательный читатель сможет найти в оригинальной работе Миколова и его коллег.
Резюме
В этой главе мы рассмотрели разные методы обучения представлений. Мы узнали, как эффективно снижать размерность при помощи автокодера. Мы познакомились с понятиями шумопонижения и разреженности, которые придают дополнительные полезные свойства автокодерам. Потом мы переключились на обучение представлений, при котором контекст входных данных информативнее, чем они сами. Мы научились порождать плотные векторные представления для английских слов при помощи модели Skip-Gram, что будет полезно при работе с моделями глубокого обучения для понимания языка. В следующей главе мы продолжим анализировать язык и другие последовательности методами глубокого обучения.
Глава 7. Модели анализа последовательностей
* * *
Анализ данных переменной длины
До сих пор мы работали только с данными фиксированного размера — изображениями из MNIST, CIFAR-10 и ImageNet. Эти модели очень хороши, но возникает немало ситуаций, в которых они недостаточны. Подавляющее большинство видов взаимодействия в повседневной жизни требует хорошего понимания последовательностей: это и чтение утренней газеты, и приготовление овсяной каши, и слушание радио, и просмотр презентации, и решение совершить операцию на фондовом рынке. Чтобы адаптироваться к данным переменной длины, нужно проявить чуть больше смекалки при создании моделей глубокого обучения.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.