Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
if len(element.split()) > 0]
counter = 0
for pair in train_dataset + test_dataset:
dataset_vocab[pair[0]] = 1
if pair[1] not in tags_to_index:
tags_to_index[pair[1]] = counter
index_to_tags[counter] = pair[1]
counter += 1
Наконец, мы создаем объекты как для обучающего, так и для тестового наборов данных, чтобы на их основе разработать мини-пакеты для обучения и тестирования. Создание объекта набора данных требует доступа к дескриптору базы LevelDB db, самому набору данных dataset, словарю tags_to_index для сопоставления меток частей речи с индексами входного вектора и логическому флагу get_all, который определяет, будет ли вызов метода для создания мини-пакета возвращать полный набор по умолчанию:
class POSDataset():
def __init__(self, db, dataset, tags_to_index,
get_all=False):
self.db = db
self.inputs = []
self.tags = []
self.ptr = 0
self.n = 0
self.get_all = get_all
for pair in dataset:
self.inputs.append(np.fromstring(db.Get(pair[0]), dtype=np.float32))
self.tags.append(tags_to_index[pair[1]])
self.inputs = np.array(self.inputs, dtype=np.float32)
self.tags = np.eye(len(tags_to_index.keys()))
[self.tags]
def prepare_n_gram(self, n):
self.n = n
def minibatch(self, size):
batch_inputs = []
batch_tags = []
if self.get_all:
counter = 0
while counter < len(self.inputs) — self.n + 1:
batch_inputs.append(self.inputs[
counter: counter+self.n].flatten())
batch_tags.append(self.tags[counter + self.n — 1])
counter += 1
elif self.ptr + size < len(self.inputs) — self.n:
counter = self.ptr
while counter < self.ptr + size:
batch_inputs.append(self.inputs
[counter: counter+self.n].flatten())
batch_tags.append(self.tags[counter + self.n — 1])
counter += 1
else:
counter = self.ptr
while counter < len(self.inputs) — self.n + 1:
batch_inputs.append(self.inputs[counter: counter+self.n].flatten())
batch_tags.append(self.tags[counter + self.n — 1])
counter += 1
counter2 = 0
while counter2 < size — counter + self.ptr:
batch_inputs.append(self.inputs[
counter2:counter2+self.n].flatten())
batch_tags.append(self.tags[
counter2 + self.n — 1])
counter2 += 1
self.ptr = (self.ptr + size) % (len(self.inputs) — self.n)
return np.array(batch_inputs, dtype=np.float32),
np.array
(batch_tags)
train = POSDataset(db, train_dataset, tags_to_index)
test = POSDataset(db, test_dataset, tags_to_index,
get_all=True)
Наконец, мы строим сеть с прямым распространением сигнала так же, как и в других главах. Обсуждение кода опустим, детали можно узнать из прилагаемого к книге репозитория, файл feedforward_pos.py. Чтобы запустить модель с входными векторами 3-грамм, выполняем следующую команду:
$ python feedforward_pos.py 3
LOADING PRETRAINED WORD2VEC MODEL…
Using a 3-gram model
Epoch: 0001 cost = 3.149141798
Validation Error: 0.336273431778
Then»
the DT
woman NN
, RP
after UH
grabbing VBG
her PRP
umbrella NN
, RP
went UH
to TO
the PDT
bank NN
to TO
deposit PDT
her PRP
cash NN
SYM
Epoch: 0002 cost = 2.971566474
Validation Error: 0.300647974014
Then»
the DT
woman NN
, RP
after UH
grabbing RBS
her PRP$
umbrella NN
, RP
went UH
to TO
the PDT
bank NN
to TO
deposit)
her PRP$
cash NN
SYM
…
Во время каждой эпохи мы вручную проверяем модель, запуская разбор предложения The woman, after grabbing her umbrella, went to the bank to deposit her cash («Женщина, взяв свой зонт, пошла в банк внести свои наличные»). За 100 эпох обучения алгоритм достигает точности более 96% и почти идеально разбирает проверочное предложение (делая только одну объяснимую ошибку: путая метки притяжательного и личного местоимений при первом появлении слова her («ее»)). Визуализация работы нашей модели с помощью TensorBoard показана на рис. 7.4.
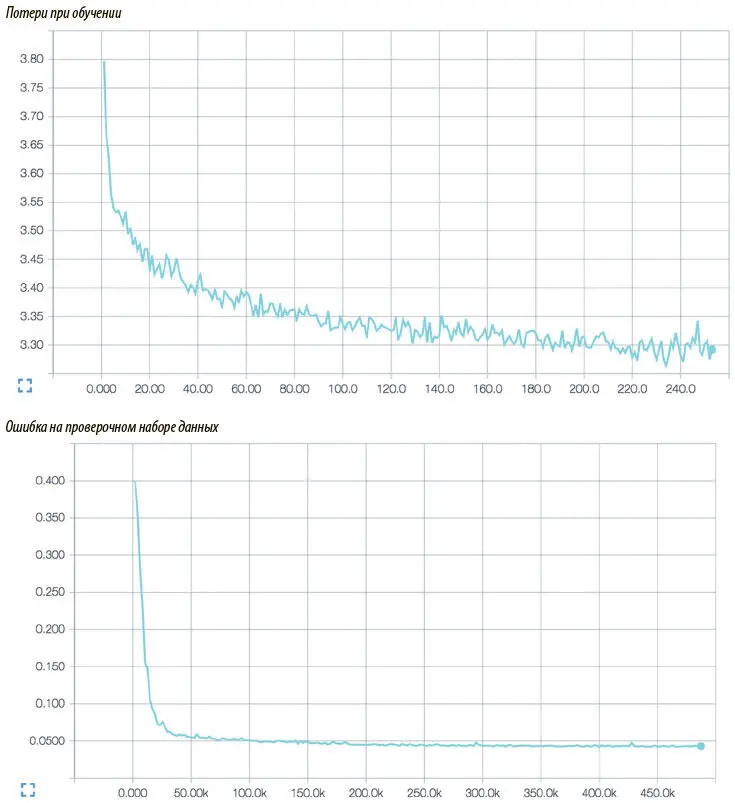
Рис. 7.4. Визуализация в TensorBoard модели с прямым распространением сигнала для определения частей речи
Модель разметки частей речи была отличным упражнением, но в основном на повторение и закрепление идей из предыдущих глав. Сейчас мы начнем работу с гораздо более сложными задачами, связанными с последовательностями. Для этого потребуются новые идеи и архитектуры. Мы выходим на передний край современных работ в области глубокого обучения. Начнем с проблемы определения зависимостей.
Определение зависимостей и SyntaxNet
Подход, который мы использовали для разметки частей речи, был простым. Но часто при решении задач seq2seq нужно применять куда более творческие решения, особенно если сложность проблемы возрастает. Ниже мы рассмотрим стратегии, которые задействуют изощренные структуры данных для решения сложных задач seq2seq. Для иллюстрации возьмем проблему определения зависимостей.
Идея построения дерева определения зависимостей в том, чтобы установить связи между словами в предложении. Возьмем, например, зависимость на рис. 7.5. Слова I («я») и taxi («такси») — дочерние для took («взял»), поскольку это подлежащее и прямое дополнение при глаголе.
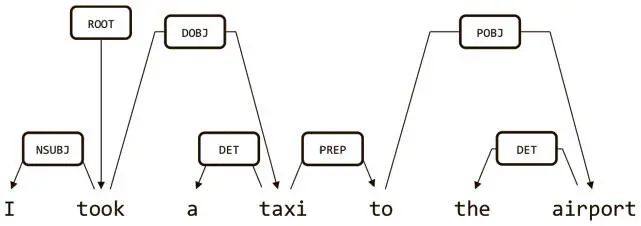
Рис. 7.5. Пример поиска зависимостей, который строит дерево связей между словами в предложении
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.