Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Для использования модели на практике можно выполнить рекомендованное сетью действие, применить его к конфигурации и взять новую конфигурацию за основу для следующего шага (извлечение признаков, предсказание действия и его выполнение). Этот процесс показан на рис. 7.10.
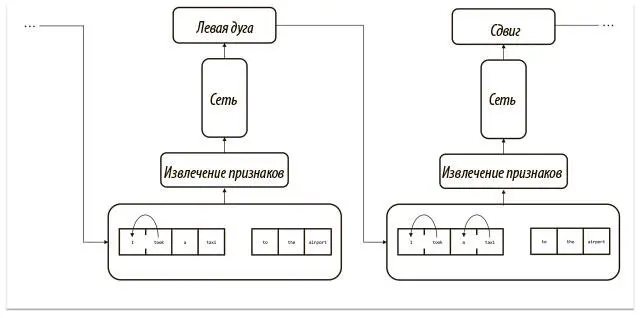
Рис. 7.10. Нейронная схема разбора зависимостей с помощью метода стандартных дуг
Все эти идеи лежат в основе SyntaxNet от Google, выдающейся открытой реализации разбора зависимостей. Вдаваться в подробности мы не будем, детали есть в открытом репозитории [86], который содержит реализацию Parsey McParseface — самого точного из публично описанных парсеров английского языка на момент публикации этой книги.
Лучевой поиск и глобальная нормализация
В предыдущем разделе мы описали наивную стратегию практического применения SyntaxNet. Она была жадной : мы выбирали самые вероятные предсказания, не заботясь о том, что можем загнать себя в угол, сделав ошибку на раннем этапе. В примере с частями речи неверное предсказание по сути не влекло никаких последствий. В этом случае его можно считать независимой проблемой, поскольку его результаты не влияют на входные данные на следующем шаге. Но это предположение в SyntaxNet не подтверждается, поскольку наше предсказание на шаге n влияет на входные данные, которые используются на шаге n + 1. Отсюда следует, что любая ошибка повлияет на все дальнейшие решения. Более того, нет простого способа «вернуться» и исправить огрехи, когда они станут очевидными. Крайний случай — предложения с подвохом . Рассмотрим такое предложение: The complex houses married and single soldiers and their families [ «Комплекс обеспечивает жильем женатых и одиноких солдат и их семьи»]. На первый взгляд выглядит странно: большинство людей решат, что complex — прилагательное, houses — существительное, а married — глагол прошедшего времени. Смысла мало [дословно «сложные дома женились»], и мы в недоумении, когда добираемся до конца предложения. Тут нам становится ясно, что complex — существительное (военный комплекс), а houses — глагол («обеспечивает жильем»). Иными словами, предложение сообщает, что военный комплекс дает жилье солдатам (как одиноким, так и женатым) и их семьям. Жадная версия SyntaxNet не сможет исправить первичную ошибку восприятия complex houses как «сложных домов» и создать верную трактовку предложения. Для устранения этого недостатка используется стратегия лучевого поиска, показанная на рис. 7.11.
Рис. 7.11. Пример использования лучевого поиска (с размером луча 2) при разворачивании обученной модели SyntaxNet
Обычно она применяется как раз в ситуациях вроде SyntaxNet, когда выводы сети на определенном шаге влияют на входные данные, используемые на следующих шагах. Основная идея — не быстро выбирать самое вероятное предсказание на каждом шаге, а определять луч наиболее вероятной гипотезы ( фиксированного размера b ) для последовательности первых k действий и связанных с ними возможностей. Лучевой поиск можно разбить на две основные стадии: расширение и отсечение.
Во время расширения мы анализируем каждую гипотезу, рассматривая ее как возможный ввод в SyntaxNet. Допустим, SyntaxNet выдает распределение вероятностей по количеству действий | A |. Затем мы вычисляем вероятность b | A | возможных гипотез для последовательности первых ( k + 1) действий. А во время отсечения мы оставляем только b гипотез с наибольшей вероятностью из b | A | вариантов.
Как показывает рис. 7.11, лучевой поиск позволяет SyntaxNet постфактум исправлять неверные предположения, задействуя с самого начала и менее вероятные гипотезы, которые, однако, могут впоследствии оказаться более плодотворными. Если углубляться в пример на рисунке, можно отметить, что жадный алгоритм предположил бы, будто верная последовательность шагов — СДВИГ плюс ЛЕВАЯ ДУГА. На самом деле лучшим (наиболее вероятным) вариантом будет использовать ЛЕВУЮ ДУГУ и за ней ПРАВУЮ ДУГУ.
Лучевой поиск с размером луча 2 отражает этот результат.
Полная версия с открытыми исходными кодами делает шаг вперед и пытается внедрить лучевой поиск в процесс обучения сети. В 2016 году Дэниел Андор и его коллеги [87]описали этот процесс глобальной нормализации . Он дает как хорошие теоретические результаты, так и очевидные практические преимущества перед локальной нормализацией . Во втором случае сеть получает задачу выбора лучшего действия в зависимости от конфигурации. Она выдает результат, который нормализуется слоем функции мягкого максимума. Так моделируется распределение вероятностей по всем возможным действиям, если они уже совершены. Функция потерь пытается довести распределение вероятностей до идеального выходного результата (например, вероятности 1 для правильного действия и 0 для всех остальных). И функция потерь — перекрестная энтропия — прекрасно с этим справляется.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.