Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
На рис. 7.1 мы демонстрируем неудачи нейронной сети с прямым распространением сигнала при анализе последовательностей. Если она имеет тот же размер, что и входной слой, модель будет работать как ожидается. Можно даже работать с входными данными меньшего размера, дополнив их нулями до нужной длины. Но когда входные данные начинают превышать размер входного слоя, примитивное использование сети с прямым распространением сигнала становится невозможным.
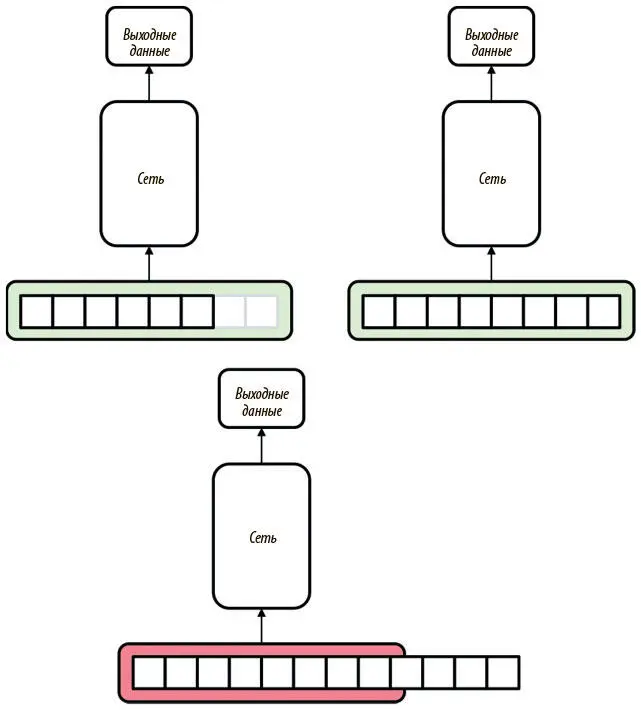
Рис. 7.1. Сети с прямым распространением сигнала прекрасно решают проблемы с входными данными фиксированного размера. Дополнение нулями позволяет работать с данными меньшего размера, но при прямом использовании эти модели отказывают, когда входные данные начинают превышать фиксированный размер
Не все потеряно. В следующих двух разделах мы расскажем о нескольких стратегиях, которые можно применить, чтобы научить сети с прямым распространением сигнала обрабатывать последовательности. Далее мы рассмотрим ограничения этих методов и расскажем о новых архитектурах, призванных их устранить. Наконец, закончим повествованием о самых совершенных на данный момент архитектурах, позволяющих решать наиболее сложные проблемы в воссоздании человеческого логического мышления при работе с последовательностями.
seq2seq и нейронные N-граммные модели
Рассмотрим архитектуру сети с прямым распространением сигнала, которая может обрабатывать текст и выдавать последовательность меток частей речи (part-of-speech, POS). Мы хотим присвоить ярлык каждому слову исходного текста, пометив его как существительное, глагол, предлог и т. д. Пример приведен на рис. 7.2. Это не так сложно, как создать искусственный интеллект, который сможет, изучив текст, ответить на вопросы о нем, но это серьезный первый шаг к разработке алгоритма, который способен понять значение использованных в предложении слов. Задача интересна еще и тем, что представляет собой частный случай класса, именуемого seq2seq , где основная цель — трансформация входной последовательности в соответствующую выходную. Среди других знаменитых задач seq2seq — перевод текста с одного языка на другой (о чем мы поговорим позже), составление аннотации текста и распознавание устной речи.

Рис. 7.2. Пример точного определения частей речи для английского предложения
Как мы уже говорили, не вполне понятно, как взять текст и сразу получить полную последовательность меток частей речи. Здесь используется хитрость, напоминающая способ разработки распределенных векторных представлений слов (см. главу 6).
Ключевое наблюдение: чтобы определить часть речи любого слова, не обязательно учитывать долгосрочные зависимости .
Вывод таков: вместо того чтобы брать все предложение для определения всех меток частей речи одновременно, можно присваивать метки поочередно, используя последовательности фиксированной длины. Так, мы берем подпоследовательность, начинающуюся с интересующего нас слова и распространяющуюся на n предыдущих. Эта нейронная N-грамм стратегия изображена на рис. 7.3.
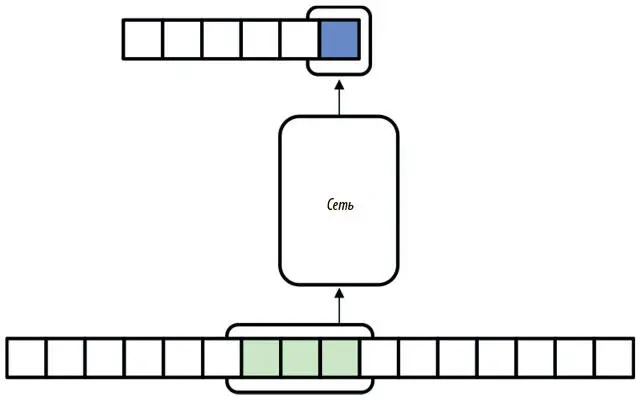
Рис. 7.3. Использование сети с прямым распространением сигнала для seq2seq, когда можно игнорировать долгосрочные зависимости
Так, когда мы определяем метку части речи для i -го слова во входных данных, мы используем в качестве этих данных слова i − n + 1 -е, i − n + 2 -е , …, i-е . Эту подпоследовательность мы называем контекстным окном . Для обработки всего текста мы сначала устанавливаем сеть в самом его начале. Затем мы перемещаем контекстное окно по слову за раз, определяя метку части речи для самого правого слова, пока не достигаем конца текста.
Применяя стратегию плотных векторных представлений слов из предыдущей главы, мы используем также плотные представления вместо прямых унитарных векторов. Это позволит нам сократить число параметров модели и ускорить процесс обучения.
Реализация разметки частей речи
Теперь, владея знаниями об архитектуре POS-сети, можно перейти к реализации. Сеть состоит из входного слоя, который использует контекстное окно 3-грамм. Мы применим 300-мерные векторные представления слов, что даст нам контекстное окно размерностью 900. Сеть с прямым распространением сигнала будет иметь два скрытых слоя, из 512 и 256 нейронов соответственно.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.