Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Интерпретируемость можно повысить, исследуя характеристики выходных данных автокодера. В целом его представления достаточно плотные, и это влияет на то, как они изменяются при внесении поправок во входные данные. Рассмотрим ситуацию на рис. 6.15.
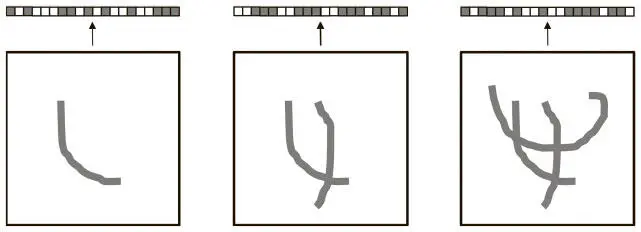
Рис. 6.15. Активации плотного векторного представления сочетаются и перекрываются, информацию о разных признаках трудно интерпретировать
Автокодер выдает плотное векторное представление, то есть такое, в котором исходное изображение сильно сжато.
Поскольку мы можем работать только с измерениями, содержащимися в представлении, его активации содержат информацию из многих источников, и распутать результат крайне сложно. При добавлении или удалении компонентов представление меняется непредсказуемо. Почти невозможно интерпретировать то, как и почему оно получается именно таким.
Идеальным исходом для нас была бы возможность создания представления с четким соответствием 1 к 1 (или близко к этому) между высокоуровневыми признаками и индивидуальными компонентами кода. Сумев этого добиться, мы близко подойдем к системе, описанной на рис. 6.16. На рис. А показано, как меняется представление при добавлении и вычитании компонентов, а на В цветом выделена связь между штрихами и компонентами кода. Здесь понятно, как и почему меняется представление: фактически это сумма отдельных штрихов в изображении.
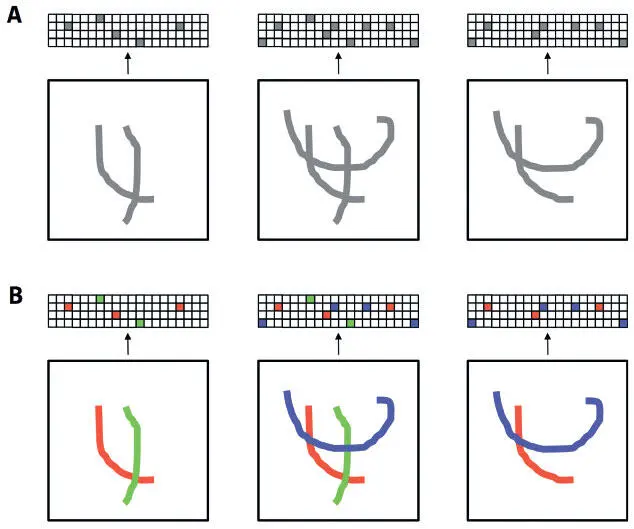
Рис. 6.16. При грамотном сочетании пространства и разреженности представление лучше поддается интерпретации. На рис. А мы показываем, как активации представления меняются с добавлением и вычитанием штрихов. На рис. В мы кодируем цветом активации, которые соответствуют каждому штриху, чтобы показать возможность интерпретации воздействия конкретного штриха на представление
Это идеальный вариант, но нужно тщательно продумать, какие механизмы использовать, чтобы добиться такой интерпретируемости изображения. Проблема, очевидно, в том, что слой кода — узкое место сети. К сожалению, простое повышение количества нейронов в слое не поможет. Мы можем увеличить размер слоя кода, но обычно нет механизма, который не позволяет каждому признаку, выбранному автокодером, незначительно влиять на множество компонентов. В крайнем случае, когда выбранные признаки сложнее и, следовательно, полезнее, размер слоя кода может быть даже больше, чем входных данных. Тогда модель способна в буквальном смысле выполнять операции «копирования», при которых слой кода не учится никаким полезным представлениям.
Нам нужно заставить автокодер использовать как можно меньше компонентов вектора плотного представления без ущерба для эффективности воссоздания входных данных. Это очень похоже на регуляризацию во избежание переобучения в простых нейронных сетях (см. главу 2), но на этот раз нужно, чтобы как можно больше компонентов векторного представления имели нулевое значение или близкое к нему.
Как и в главе 2, достичь этого можно, введя в целевую функцию модификатор разреженности (SparsityPenalty), который повышает стоимость любого представления, где многие компоненты не равны 0:
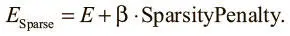
Значение β определяет, насколько мы стремимся к разреженности в ущерб качеству реконструкций. Математически подкованные читатели могут рассматривать значения каждого компонента всех отображений как результат случайной переменной с неизвестным средним. Затем мы задействуем меру расстояния, сравнивая распределение наблюдений этой случайной переменной (значений каждого компонента) и случайной переменной, среднее значение которой известно и равно 0. В данном случае часто используется расстояние Кулльбака — Лейблера (KL). Дальнейшее рассмотрение разреженности в автокодере выходит за рамки этой книги, но приводится в работах Маркаурелио Ранзато (2007 и 2008) [76]. Теоретические свойства и эмпирическая эффективность введения функции-посредника до слоя кода, которая обнуляет все активации в представлении, кроме k , были исследованы в работе Алирезы Макзани и Брендана Фрея (2014) [77]. k-Разреженные автокодеры оказались столь же эффективны, как и остальные механизмы разрежения, несмотря на поразительную простоту реализации и понимания (а в плане вычислений их эффективность даже выше).
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.