Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Резюме
В этой главе мы поговорили о ряде проблем при попытках обучать глубокие сети со сложными поверхностями ошибок. Мы рассказали, что проблемы сомнительных локальных минимумов, возможно, преувеличены, а седловые точки и плохая обусловленность действительно могут серьезно мешать успеху обычного мини-пакетного градиентного спуска. Мы описали, как использовать импульс для борьбы с плохой обусловленностью, и дали краткий обзор последних исследований методов второго порядка, направленных на аппроксимацию матрицы Гессе. Мы рассказали об эволюции алгоритмов оптимизации с адаптацией темпа обучения, которые настраивают темп в процессе для улучшения сходимости.
В следующей главе мы начнем разговор о более широкой проблеме архитектуры и проектирования сетей. Начнем мы с анализа компьютерного зрения и того, как создавать глубокие сети, эффективно обучающиеся на сложных изображениях.
Глава 5. Сверточные нейросети
Нейроны и зрение человека
Человеческое зрение развито очень хорошо. За доли секунды мы можем распознавать видимые объекты без особых умственных усилий или задержек. Мы не только способны назвать то, на что смотрим, но и ощутить его глубину, четко определить контуры и отделить от фона. Каким-то образом наши глаза получают необработанные воксели [53]информации о цвете, но в мозге они перерабатываются в более значимые единицы — линии, кривые и формы, которые могут, например, подсказать, что мы смотрим на домашнюю кошку [54].
Человеческое зрение основано на нейронах. Последние отвечают за доставку световой информации в глаз [55]. Эта информация проходит здесь предварительную обработку, препровождается в зрительную кору мозга и только там анализируется. За все эти функции и отвечают нейроны. Поэтому интуитивно кажется, что стоило бы обобщить наши модели нейронных сетей для создания более эффективных систем компьютерного зрения. В этой главе мы воспользуемся нашим пониманием человеческого зрения для создания эффективных моделей глубокого обучения анализу изображений. Но для начала рассмотрим более традиционные подходы к вопросу и отметим их недостатки.
Недостатки выбора признаков
Начнем с простой проблемы компьютерного зрения. Я дам вам случайно выбранное изображение — например, с рис. 5.1. Ваша задача — ответить, есть ли здесь человеческое лицо. Именно эту проблему затрагивали Пол Виола и Майкл Джонс в своей основополагающей работе в 2001 году [56].

Рис. 5.1. Гипотетический алгоритм распознавания лиц должен найти на этой фотографии лицо экс-президента Барака Обамы
Для людей это тривиальная задача. А вот для компьютера она очень сложна. Как научить его тому, что на изображении есть лицо? Можно использовать традиционный алгоритм машинного обучения (вроде того, что был описан в главе 1), подавая на вход значения пикселов в надежде на то, что найдется подходящий классификатор. Но работает это плохо, поскольку отношение сигнала к шуму слишком низкое, чтобы удалось хоть чему-то обучиться. Нужна альтернатива.
Со временем появился компромиссный вариант — по сути, нечто среднее между традиционной компьютерной программой, логика которой определяется человеком, и чистым подходом машинного обучения, где все бремя ложится на компьютер. Человек выбирает признаки (возможно, сотни или тысячи), которые, по его мнению, важны для принятия решений по классификации. Так он создает представление той же проблемы, но меньшей размерности. Алгоритм машинного обучения использует новые векторы признаков для принятия решений по классификации. Поскольку процесс извлечения признаков улучшает соотношение сигнала и шума (если выделены действительно важные аспекты), этот подход имел большой успех по сравнению с имевшимися на тот момент. Виола и Джонс отметили, что лица характеризуются определенным соотношением светлых и темных пятен, которое и можно здесь использовать. Например, есть разница в интенсивности света между областью глаз и скулами, переносицей и глазами по обе стороны от нее. Эти показатели приведены на рис. 5.2.
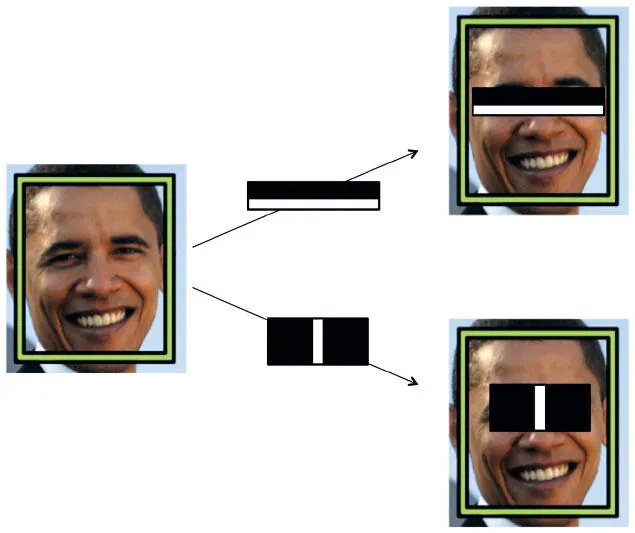
Рис. 5.2. Показатели интенсивности Виолы — Джонса
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.