Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Это аппроксимация так называемого первого импульса градиента, или E[ g i ]. Как и в RMSProp, можно сохранять экспоненциально взвешенное скользящее среднее исторических градиентов. Это оценка того, что называется вторым импульсом градиента, или E[ g i  g i]:
g i]:
v i = β 2 v i − 1 + (1 − β 2) g i g i .
Но оказывается, что эти приближения не соответствуют реальным импульсам, поскольку мы инициализируем оба вектора нулями. Чтобы устранить несоответствие, мы выводим поправочный коэффициент для обоих случаев. Здесь мы описываем вывод определения для второго импульса. Вывод первого импульса аналогичен, и мы оставим его в качестве упражнения для любителей математики.
Начнем с выражения определения второго импульса через все предыдущие градиенты. Для этого достаточно расширить рекуррентное соотношение:
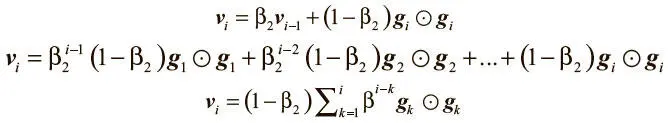
Возьмем ожидаемое значение обеих частей и определим, как наша оценка E[ v i ] соотносится с истинным значением E[ g i g i ]:
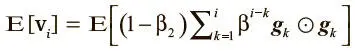
Можно принять, что E[ g k g k ] ≈E[ g i ≈ g i ], поскольку, даже если второй импульс градиента поменял значение по сравнению с историческим, β 2 должно быть выбрано так, чтобы прежние вторые импульсы градиентов утратили релевантность. В результате становится возможным такое упрощение:
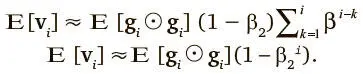
Последнее упрощение сделано с помощью элементарного алгебраического тождества 1 − x n = (1 − x ) (1 + x + … + x n — 1). В результате вывода второго импульса и аналогичного ему вывода первого мы получаем следующие поправочные схемы для борьбы с ошибкой инициализации:
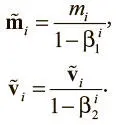
Теперь можно с помощью скорректированных импульсов обновить вектор параметров, что приведет к окончательному обновлению Adam:
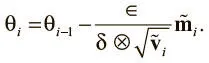
В последнее время Adam набрал популярность благодаря возможности исправлять ошибку нулевой инициализации (в RMSProp это слабое место) и способности эффективно сочетать ключевые идеи RMSProp и импульсного метода. В TensorFlow оптимизатор Adam создается с помощью следующего конструктора:
tf.train.AdamOptimizer(learning_rate=0.001, beta1=0.9,
beta2=0.999, epsilon=1e-08,
use_locking=False, name='Adam')
Настройки по умолчанию гиперпараметров для Adam в TensorFlow обычно работают удовлетворительно, но Adam хорошо справляется и с изменениями в них. Единственное исключение: иногда может понадобиться изменить темп обучения (по умолчанию задана величина 0,001).
Философия при выборе метода оптимизации
В этой главе мы обсудили ряд стратегий для упрощения навигации по сложным поверхностям ошибок глубоких сетей. Они нашли свое высшее выражение в нескольких алгоритмах оптимизации, каждый из которых имеет свои достоинства и недостатки. Было бы замечательно заранее знать, когда какой алгоритм использовать, но практикующие эксперты пока не достигли здесь консенсуса. Сейчас самые популярные варианты — мини-пакетный градиентный спуск, мини-пакетный градиент в сочетании с импульсом, RMSProp, RMSProp в сочетании с импульсом, Adam и AdaDelta (об этом алгоритме мы здесь не говорили, а TensorFlow его пока не поддерживает). Мы включили в репозитории этой книги на Github скрипт TensorFlow, чтобы любознательный читатель мог поэкспериментировать с алгоритмами оптимизации на примере построенной модели сети с прямым распространением сигнала:
$ python optimzer_mlp.py
Важно отметить, однако, что для большинства практиков глубокого обучения лучший способ достичь вершин в своем деле состоит не в создании более совершенных оптимизаторов. Большинство прорывов в этой области за последние несколько десятилетий связаны с нахождением архитектур, которые проще обучать, а не попытками разобраться с неприятными поверхностями ошибок. Далее мы сосредоточимся на использовании архитектур для более эффективного обучения нейросетей.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.