Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Однако полное их обучение сопряжено с разными сложностями, которые требуют множества технологических инноваций, в том числе больших размеченных массивов данных (ImageNet, CIFAR и т. д.), более передового «железа» с ускорителями GPU, а также новинок в области алгоритмов.
Многие годы исследователи прибегали к поуровневому «жадному» предварительному обучению для обработки сложных поверхностей ошибок в моделях глубокого обучения [41]. Эти стратегии требовали больших затрат времени и были направлены на поиск более точных вариантов инициализации параметров модели по слою за раз перед тем, как использовать мини-пакетный градиентный спуск для поиска оптимальных параметров. Но недавние прорывы в методах оптимизации позволяют нам непосредственно обучать модели от начала и до конца. В этой главе речь пойдет именно о них.
Несколько следующих разделов будут в основном посвящены локальным минимумам и тому, как они препятствуют успешному обучению глубоких моделей. Далее мы поговорим о невыпуклых поверхностях ошибок, порожденных глубокими моделями, о том, почему обычный мини-пакетный градиентный спуск часто недостаточен и как современные невыпуклые оптимизаторы преодолевают эти трудности.
Локальные минимумы на поверхности ошибок глубоких сетей
Основные трудности при оптимизации моделей глубокого обучения связаны с тем, что мы вынуждены использовать информацию о локальных минимумах для выводов о глобальной структуре поверхности ошибок. Это серьезная проблема, ведь между локальной и глобальной структурами обычно мало связи. Рассмотрим такую аналогию.
Представьте себе, что вы — муравей, живущий в континентальной части США. Вас выбросили где-то в случайном месте, и ваша задача — найти самую низкую точку на этой поверхности. Как это сделать? Если вы можете видеть только то, что вас непосредственно окружает, задача кажется неразрешимой. Если бы поверхность США имела форму миски (была бы, говоря математически, выпуклой) и мы смогли бы удачно установить темп обучения, можно было бы воспользоваться алгоритмом градиентного спуска и в конце концов добраться до дна. Но рельеф США очень сложный. И даже если мы найдем какую-то долину (локальный минимум), мы не узнаем, действительно ли это самая низкая точка на карте (глобальный минимум). В главе 2 мы говорили о том, как мини-пакетный градиентный спуск помогает в продвижении по сложной поверхности ошибок, на которой есть проблемные районы с нулевым градиентом. Но, как видно из рис. 4.1, даже стохастическая поверхность ошибок не спасает от глубокого локального минимума.
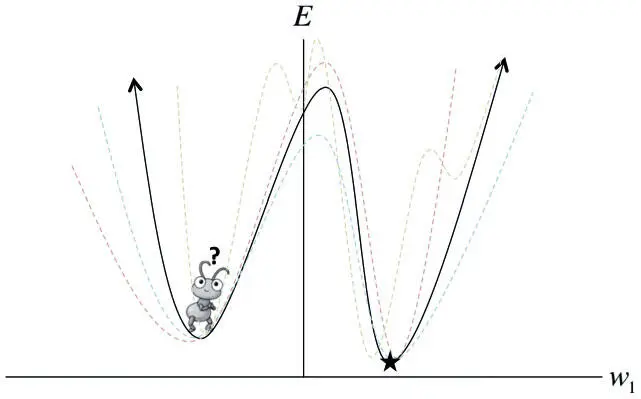
Рис. 4.1. Мини-пакетный градиентный спуск помогает избежать мелкого локального минимума, но редко эффективен при наличии глубокого локального минимума
И тут встает важный вопрос. Теоретически локальные минимумы — серьезная проблема. Но как часто они встречаются на поверхности ошибок глубоких сетей на практике? И при каких сценариях они действительно затрудняют обучение? В двух следующих разделах мы рассмотрим распространенные заблуждения относительно локальных минимумов.
Определимость модели
Первый источник локальных минимумов связан с определимостью модели . Поверхности ошибок глубоких нейросетей гарантированно имеют значительное — иногда бесконечное — число локальных минимумов. И вот почему.
Внутри слоя полносвязной нейросети с прямым распространением сигнала любая перестановка нейронов не изменит данные на выходе. Проиллюстрируем это при помощи простого слоя из трех нейронов на рис. 4.2. Оказывается, что в слое из n нейронов существует n ! способов перестановки параметров. А для глубокой сети с l слоев, каждый из которых состоит из n нейронов, имеется n! l эквивалентных конфигураций.
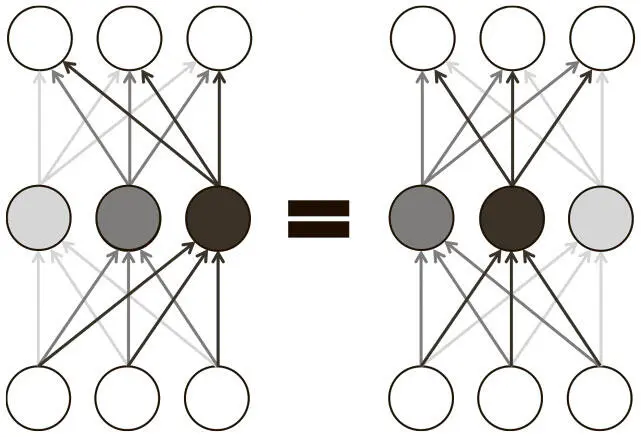
Рис. 4.2. Перестройка нейронов в слое нейросети приводит к эквивалентным конфигурациям в силу симметрии
Помимо симметрии перестроек нейронов, неопределимость присутствует в некоторых видах нейросетей и в других формах. Например, существует бесконечное число эквивалентных конфигураций, которые приводят к эквивалентным сетям для отдельного нейрона ReLU. Поскольку он использует кусочно-линейную функцию, мы можем умножить все веса входов на любую не равную 0 константу k , при этом умножая все веса выходов на 1/ k без изменения поведения сети.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.