Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
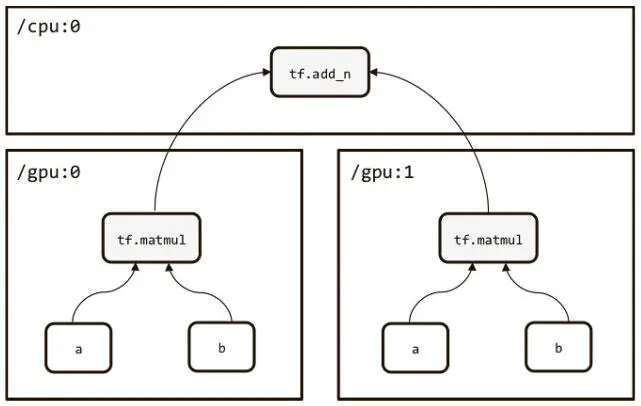
Рис. 3.3. Создание моделей для нескольких GPU в виде башни
Ниже приведен пример кода для нескольких GPU:
c = []
for d in [‘/gpu:0', ‘/gpu:1']:
with tf.device(d):
a = tf.constant([1.0, 2.0, 3.0, 4.0], shape=[2, 2], name='a')
b = tf.constant([1.0, 2.0], shape=[2, 1], name='b')
c. append(tf.matmul(a, b))
with tf.device(‘/cpu:0'):
sum = tf.add_n(c)
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
sess.run(sum)
Создание модели логистической регрессии в TensorFlow
Мы рассмотрели базовые понятия TensorFlow и можем построить простую модель для набора данных MNIST. Как вы, наверное, помните, наша цель — распознать рукописные цифры по черно-белым изображениям 28×28 единиц. Первая сеть, которую мы построим, реализует простой алгоритм машинного обучения — логистическую регрессию [33].
Логистическая регрессия — метод, с помощью которого мы можем вычислить вероятность того, что входные данные относятся к одному из целевых классов. Определим вероятность того, что данное изображение — 0, 1… или 9.
Наша модель использует матрицу W , которая представляет веса соединений в сети, и вектор b , соответствующий смещению, для вычисления того, принадлежит ли входящее значение x классу i , при помощи функции мягкого максимума (softmax), о которой мы уже говорили выше:
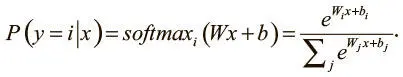
Наша задача — определить значения W и b , которые будут наиболее эффективно и точно классифицировать входящие данные. Сеть логистической регрессии можно выразить в схеме (рис. 3.4). Для простоты мы опустили смещения и их соединения.
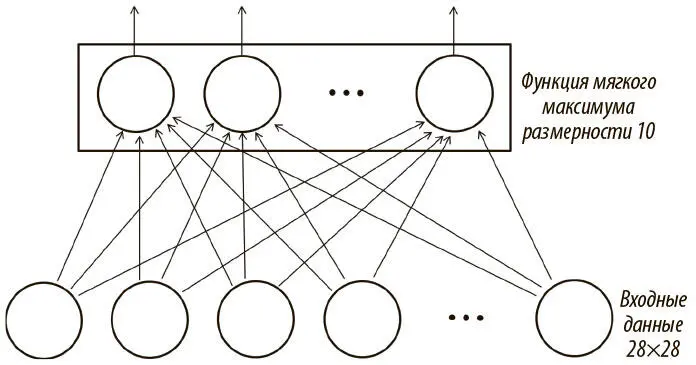
Рис. 3.4. Интерпретация логистической регрессии как примитивной нейросети
Легко заметить, что сеть для интерпретации логистической регрессии довольно примитивна. У нее нет скрытых слоев, а следовательно, ее способность усваивать сложные взаимоотношения ограничена. У нас есть выходная функция мягкого максимума размерности 10, поскольку у нас 10 возможных исходов для каждого входного значения. Более того, есть входной слой размера 784 — один входной нейрон для каждого пиксела изображения! Модель в целом способна корректно классифицировать наш набор данных, но еще есть куда расти. До конца этой главы и в главе 5 мы будем стараться повысить точность нашей работы. Но сначала посмотрим, как реализовать эту логистическую сеть в TensorFlow, чтобы обучить ее на нашем компьютере.
Модель логистической регрессии строится в четыре этапа:
1) inference: создается распределение вероятностей по выходным классам для мини-пакета [34];
2) loss: вычисляется значение функции потерь (в нашем случае перекрестная энтропии);
3) training: отвечает за вычисление градиентов параметров модели и ее обновление;
4) evaluate: определяется эффективность модели.
Для мини-пакета из 784-мерных векторов, соответствующих изображениям MNIST, мы можем выразить логистическую регрессию через функцию мягкого максимума от входных данных, умноженных на матрицу, которая представляет веса соединений входного и выходного слоев.
Каждая строка выходного тензора содержит распределение вероятностей по классам для соответствующего образца данных в мини-выборке:
def inference(x):
tf.constant_initializer(value=0)
W = tf.get_variable("W", [784, 10], initializer=init)
b = tf.get_variable("b", [10], initializer=init)
output = tf.nn.softmax(tf.matmul(x, W) + b)
return output
Теперь, с правильными метками для мини-пакета, мы можем вычислить среднюю ошибку на образец данных. При этом применяется следующий фрагмент кода, который вычисляет перекрестную энтропию по всему мини-пакету:
def loss(output, y):
dot_product = y * tf.log(output)
# Reduction along axis 0 collapses each column into a
# single value, whereas reduction along axis 1 collapses
# each row into a single value. In general, reduction along
# axis i collapses the ith dimension of a tensor to size 1.
xentropy = — tf.reduce_sum(dot_product, reduction_indices=1)
loss = tf.reduce_mean(xentropy)
return loss
Теперь, имея значение потерь, мы вычисляем градиенты и модифицируем наши параметры соответственно. TensorFlow облегчает процесс, обеспечивая доступ к встроенным оптимизаторам, которые выдают специальную операцию обучения. Ее можно запустить в сессии для минимизации ошибок. Отметим, что, создавая операцию обучения, мы передаем переменную, которая отражает количество обрабатываемых мини-выборок. Каждый раз, когда операция запускается, растет эта переменная, и мы можем отслеживать процесс:
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.