Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
def training(cost, global_step):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
train_op = optimizer.minimize(cost, global_step=global_step)
return train_op
Наконец, мы можем создать простой вычислительный подграф для оценки модели на проверочных или тестовых данных:
def evaluate(output, y):
correct_prediction = tf.equal(tf.argmax(output, 1) tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
return accuracy
На этом настройка графа в TensorFlow для модели логистической регрессии завершена.
Журналирование и обучение модели логистической регрессии
У нас есть все компоненты, можно сводить их воедино. Чтобы сохранять важную информацию в процессе обучения модели, мы записываем в журнал несколько сводок статистики. Например, мы используем команды tf.scalar_summary [35]и tf.histogram_summary [36]для записи ошибки в каждом мини-пакете, ошибки на проверочном множестве и распределения параметров. Для примера приведем скалярную сводку статистик для функции потерь:
def training(cost, global_step):
tf.scalar_summary("cost", cost)
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
train_op = optimizer.minimize(cost, global_step=global_step)
return train_op
На каждой эпохе мы запускаем tf.merge_all_summaries [37], чтобы собрать все записанные сводки, и с помощью tf.train.SummaryWriter сохраняем журнал на диске. В следующем разделе мы расскажем, как визуализировать эти журналы при помощи встроенного инструмента TensorBoard.
Помимо сводок статистики, мы сохраняем параметры модели с помощью tf.train.Saver. По умолчанию это средство поддерживает пять последних контрольных точек, которые мы можем восстанавливать для дальнейшего использования. В результате получаем следующий скрипт на Python:
# Parameters
learning_rate = 0.01
training_epochs = 1000
batch_size = 100
display_step = 1
with tf.Graph(). as_default():
# mnist data image of shape 28*28=784
x = tf.placeholder("float", [None, 784])
# 0–9 digits recognition => 10 classes
y = tf.placeholder("float", [None, 10])
output = inference(x)
cost = loss(output, y)
global_step = tf.Variable(0, name='global_step', trainable=False)
train_op = training(cost, global_step)
eval_op = evaluate(output, y)
summary_op = tf.merge_all_summaries()
saver = tf.train.Saver()
sess = tf.Session()
summary_writer = tf.train.SummaryWriter("logistic_logs/", graph_def=sess.graph_def)
init_op = tf.initialize_all_variables()
sess.run(init_op)
# Training cycle
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(mnist.train.num_examples/batch_size)
# Loop over all batches
for i in range(total_batch):
mbatch_x, mbatch_y = mnist.train.next_batch(batch_size)
# Fit training using batch data
feed_dict = {x: mbatch_x, y: mbatch_y}
sess.run(train_op, feed_dict=feed_dict)
# Compute average loss
minibatch_cost = sess.run(cost, feed_dict=feed_dict)
avg_cost += minibatch_cost/total_batch
# Display logs per epoch step
if epoch % display_step == 0:
val_feed_dict = {
x: mnist.validation.images,
y: mnist.validation.labels
}
accuracy = sess.run(eval_op, feed_dict=val_feed_dict)
print "Validation Error: ", (1 — accuracy)
summary_str = sess.run(summary_op, feed_dict=feed_dict)
summary_writer.add_summary(summary_str, sess.run(global_step))
saver.save(sess, "logistic_logs/model-checkpoint", global_step=global_step)
print "Optimization Finished!"
test_feed_dict = {
x: mnist.test.images,
y: mnist.test.labels
}
accuracy = sess.run(eval_op, feed_dict=test_feed_dict)
print "Test Accuracy: ", accuracy
Запуск этого скрипта обеспечивает нам аккуратность [38]в 91,9% по тестовому набору из 100 эпох обучения. Уже неплохо, но в последнем разделе главы мы постараемся улучшить этот результат при помощи нейросети с прямым распространением сигнала.
Применение TensorBoard для визуализации вычислительного графа и обучения
Настроив журналирование сводок статистики так, как показано в предыдущем разделе, мы можем визуализировать собранные данные. В TensorFlow предусмотрен инструмент, который обеспечивает простой в использовании интерфейс навигации по сводкам [39]. Запуск TensorBoard несложен:
tensorboard — logdir=
Параметр logdir должен быть установлен на каталог, в котором tf.train.SummaryWriter фиксировал сводки статистики. Нужно прописывать абсолютный, а не относительный путь, иначе TensorBoard может не найти журналы. Если мы успешно запустили TensorBoard, этот инструмент будет предоставлять доступ к данным через http://localhost:6006/ — этот адрес можно открыть в браузере.
Как показано на рис. 3.5, первая вкладка содержит информацию о скалярных сводках, которые мы собирали. Как вы видите, потери и на мини-пакетах, и на проверочном множестве уменьшаются.
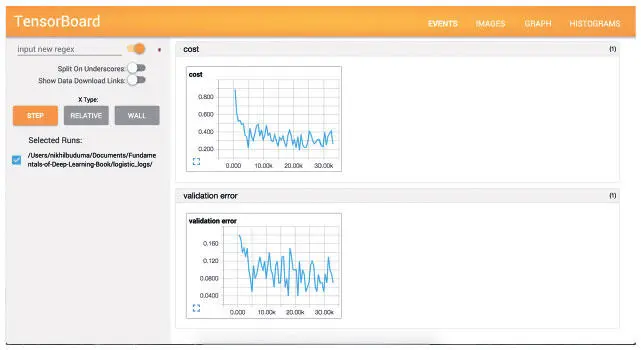
Рис. 3.5. Представление событий в TensorBoard
На рис. 3.6 показана другая вкладка, которая позволяет визуализировать весь построенный граф вычислений. Интерпретировать его не очень просто, но если мы столкнемся с непредсказуемым поведением, то представление графа будет полезным при отладке.
Рис. 3.6. Графическое представление в TensorBoard
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.