Philippe J. S. De Brouwer - The Big R-Book
Здесь есть возможность читать онлайн «Philippe J. S. De Brouwer - The Big R-Book» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:The Big R-Book
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
The Big R-Book: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «The Big R-Book»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
The Big R-Book for Professionals: From Data Science to Learning Machines and Reporting with R Provides a practical guide for non-experts with a focus on business users Contains a unique combination of topics including an introduction to R, machine learning, mathematical models, data wrangling, and reporting Uses a practical tone and integrates multiple topics in a coherent framework Demystifies the hype around machine learning and AI by enabling readers to understand the provided models and program them in R Shows readers how to visualize results in static and interactive reports Supplementary materials includes PDF slides based on the book’s content, as well as all the extracted R-code and is available to everyone on a Wiley Book Companion Site
is an excellent guide for science technology, engineering, or mathematics students who wish to make a successful transition from the academic world to the professional. It will also appeal to all young data scientists, quantitative analysts, and analytics professionals, as well as those who make mathematical models.
The Big R-Book — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «The Big R-Book», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
mean()
This is a dispatcher function 1 and it will work in a meaningful way for a variety of objects, such as vectors, matrices, etc.
# The mean of a vector:x <- c(1,2,3,4,5,60) mean(x) ## [1] 12.5 # Missing values will block the override the result:x <- c(1,2,3,4,5,60,NA) mean(x) ## [1] NA # Missing values can be ignored with na.rm = TRUE: mean(x, na.rm = TRUE) ## [1] 12.5 # This works also for a matrix:M <- matrix( c(1,2,3,4,5,60), nrow=3) mean(M) ## [1] 12.5
 Hint – Outliers
Hint – Outliers
The mean is highly influenced by the outliers. To mitigate this to some extend the parameter trimallows to remove the tails. It will sort all values and then remove the x% smallest and x% largest observations.
v <- c(1,2,3,4,5,6000) mean(v) ## [1] 1002.5 mean(v, trim = 0.2) ## [1] 3.5
8.1.1.2 Generalised Means
mean – generalized
More generally, a mean can be defined as follows:
Definition: f-mean
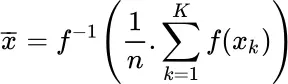
Popular choices for f()are:
f ( x ) = x : arithmetic mean,
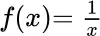 : harmonic mean,
: harmonic mean,
f ( x ) = x m: power mean,
f ( x ) = ln x : geometric mean, 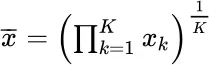
arithmetic mean
mean – harmonic
harmonic mean
mean – power
power mean
mean – geometric
geometric mean
The Power Mean
One particular generalized mean is the power mean or Hölder mean. It is defined for a set of K positive numbers x kby
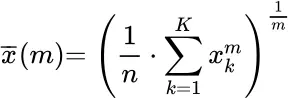
holder mean
mean – holder
by choosing particular values for m one can get the quadratic, arithmetic, geometric and harmonic means.
mean – quadratic
m → ∞: maximum of x k
m = 2: quadratic mean
m = 1: arithmetic mean
m → 0: geometric mean
m = 1: harmonic mean
m → −∞: minimum of x k
Example: Whichmeanmakes most sense?
What is the average return when you know that the share price had the following returns: −50%, +50%,−50%, +50%. Try the arithmetic mean and the mean of the log-returns.
returns <- c(0.5, -0.5,0.5, -0.5) # Arithmetic mean:aritmean <- mean(returns) # The ln-mean:log_returns <-returns for(k in1 :length(returns)) { log_returns[k] <- log( returns[k] +1) } logmean <- mean(log_returns) exp(logmean) -1 ## [1] -0.1339746 # What is the value of the investment after these returns:V_0 <-1 V_T <-V_0 for(k in1 :length(returns)) { V_T <-V_T *(returns[k] +1) } V_T ## [1] 0.5625 # Compare this to our predictions: ## mean of log-returnsV_0 *( exp(logmean) -1) ## [1] -0.1339746 ## mean of returnsV_0 *(aritmean +1) ## [1] 1
8.1.2 The Median
median
While the mean (and the average in particular) is widely used, it is actually quite vulnerable to outliers. It would therefore, make sense to have a measure that is less influenced by the outliers and rather answers the question: what would a typical observation look like. The median is such measure.
central tendency – median
The median is the middle-value so that 50% of the observations are lower and 50% are higher.
x <- c(1 :5,5e10,NA) x ## [1] 1e+00 2e+00 3e+00 4e+00 5e+00 5e+10 NA median(x) # no meaningful result with NAs## [1] NA median(x,na.rm = TRUE) # ignore the NA## [1] 3.5 # Note how the median is not impacted by the outlier, # but the outlier dominates the mean: mean(x, na.rm = TRUE) ## [1] 8333333336
8.1.3 The Mode
mode
central tendency – mode
The mode is the value that has highest probability to occur. For a series of observations, this should be the one that occurs most often. Note that the mode is also defined for variables that have no order-relation (even labels such as “green,” “yellow,” etc. have amode, but not a mean or median—without further abstraction or a numerical representation).
In R, the function mode()or storage.mode()returns a character string describing how a variable is stored. In fact, R does not have a standard function to calculate mode, so let us create our own:
mode()
storage.mode()
# my_mode # Finds the first mode (only one) # Arguments: # v -- numeric vector or factor # Returns: # the first modemy_mode <- function(v) { uniqv <- unique(v) tabv <- tabulate( match(v, uniqv)) uniqv[ which.max(tabv)] } # now test this functionx <- c(1,2,3,3,4,5,60,NA) my_mode(x) ## [1] 3 x1 <- c(“relevant”, “N/A”, “undesired”, “great”, “N/A”, “undesired”, “great”, “great”) my_mode(x1) ## [1] “great” # text from https://www.r-project.org/about.htmlt <-“R is available as Free Software under the terms of the Free Software Foundation’s GNU General Public License in source code form. It compiles and runs on a wide variety of UNIX platforms and similar systems (including FreeBSD and Linux), Windows and MacOS.” v <- unlist( strsplit(t,split=” “)) my_mode(v) ## [1] “and”
unique()
Linux
FreeBSD
tabulate()
uniqv()
While this function works fine on the examples provided, it only returns the first mode encountered. In general, however, the mode is not necessarily unique and it might make sense to return them all. This can be done by modifying the code as follows:
Читать дальшеИнтервал:
Закладка:
Похожие книги на «The Big R-Book»
Представляем Вашему вниманию похожие книги на «The Big R-Book» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «The Big R-Book» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.