Claus Braunecker - How to do empirische Sozialforschung
Здесь есть возможность читать онлайн «Claus Braunecker - How to do empirische Sozialforschung» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на немецком языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:How to do empirische Sozialforschung
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
How to do empirische Sozialforschung: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «How to do empirische Sozialforschung»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Was unterscheidet empirische Forschungsfragen von Hypothesen? Wie erstelle ich dazu passend einen Fragebogen, ein Codebuch, einen Gesprächsleitfaden? Wie definiere ich eine Grundgesamtheit? Wie ziehe ich eine gute Stichprobe, ohne den Datenschutz zu verletzen? Was sind Schwankungsbreiten? Und welches Auswertungsverfahren passt zu welchem Messniveau?
Dieses Buch erläutert Schritt für Schritt die Planung und Durchführung von empirischen Erhebungen sowie die Grundlagen von Datenanalyseverfahren. Neben vielen Beispielen enthält die praxisnahe Gebrauchsanleitung 40 Abbildungen, zahlreiche farblich hervorgehobene Querverweise, ein schlagwortoptimiertes Stichwortverzeichnis sowie frei zugängliche Downloads: einen Demo-Fragebogen, Best-Practice-Beispiele, frei (um)gestaltbare Foliensätze für Dozent*innen (howtodo.at bzw. utb-shop.de).
Die Zielgruppe sind Studierende der Publizistik-, Medien- und Kommunikationswissenschaft, der Sozial- und
Wirtschaftswissenschaften sowie Praktiker*innen der Markt- und Meinungsforschung.
How to do empirische Sozialforschung — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «How to do empirische Sozialforschung», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Eine Bildungseinrichtung untersucht - über ein Jahr - die Klickraten auf ihre unterschiedlich gestalteten werblichen und redaktionellen Beiträge im Internet. Die Zahlen sollen eine Entscheidungsgrundlage liefern, wo und in welcher Form Inhalte positioniert werden müssen, um größtmögliche Reichweiten zu erzielen.
Ein Unternehmen leitet aus der Anzahl der mit konkreten Detailaspekten (sehr) zufriedenen Kundinnen und Kunden wertvolle Qualitätskennzahlen ab.
Eine Studierende spricht im Rahmen ihrer Masterarbeit mit vielen Expertinnen und Experten. Sie geht aber nicht auf inhaltliche Details des „Expertentums‟ ein. Sie quantifiziert ausschließlich, wie viele sich mit welchen konkreten Themendetails auseinandersetzen.
Das Ziel ist erreicht, wenn das quantitativ produzierte meist umfangreiche Datenmaterial übersichtlich und anschaulich analysiert werden konnte: Wie oft treten Meinungen, Verhaltensweisen, Aussagen, Zustände (in welchen graduellen Ausprägungen) auf? 15
Quantitative Analysen erfolgen meist mit spezifischer Software: Mit dem sehr gebräuchlichen Auswertungsprogramm SPSS (Version 27) beschäftigt sich im Detail Braunecker 2021.
Abbildung 2 auf Seite 25gibt einen zusammenfassenden überblick über das Wesen der „inhaltlichen‟ gegenüber der „zählenden‟ Forschungswelt. [24]

Abbildung 2: Qualitative und quantitative Methoden
In den folgenden Abschnitten dieses Kapitels werden die gebräuchlichsten Arten und Anwendungsfälle qualitativer und quantitativer Forschungsmethoden überblicksmäßig skizziert. Die Reihenfolge der Darstellung erfolgt aufgrund mannigfaltiger Kombinations- und Anwendungsmöglichkeiten der einzelnen Methoden willkürlich.
2.3 | Inhaltsanalyse
Inhaltsanalysen erforschen Kommunikationsinhalte, indem sie Aussagen und Bedeutungen untersuchen. Gegenstand einer Inhaltsanalyse können (Zeitungs-)Texte, Bilder, Radio- und Fernsehsendungen, Webseiten, Social Media, Bücher, Filme, Plakate, Firmenlogos, Firmenauftritte usw. sein. Die Basis der Analyse stellen von Personen geäußerte oder in Medien publizierte schriftliche, bildliche oder akustische Inhalte dar.
Inhaltsanalysen vereinen oft qualitative und quantitative Elemente: Neben dem Zählen des Auftretens von Aussagen, Bildern, Artikellängen, Artikelthemen etc. (quantitative Inhaltsanalyse) erfolgt oft auch eine bedeutungsmäßige Analyse der gezählten Wortinhalte (qualitative Inhaltsanalyse).
So könnte eine Inhaltsanalyse Artikel (aller Tageszeitungen eines Landes in der ersten Januarwoche eines bestimmten Jahres) zum Thema „Klimaveränderung‟ untersuchen. Sie könnte das Vorkommen des Wortes „Klimawandel‟ zählen und zwischen Boulevard- und Qualitätspresse vergleichen (quantitative Inhaltsanalyse). Wenn in weiterer Folge aus dem Artikelkontext heraus zusätzlich auch noch eine Bewertung erfolgt, ob der Beitrag [25] verharmlosend, sachlich neutral oder alarmierend verfasst wurde, wird damit auch eine qualitative Inhaltsanalyse durchgeführt.
Ein sehr wichtiges Element jeder Inhaltsanalyse ist ein gutes Codierschema. Darin müssen alle zu analysierenden Dimensionen und deren Ausprägungen klar definiert werden.
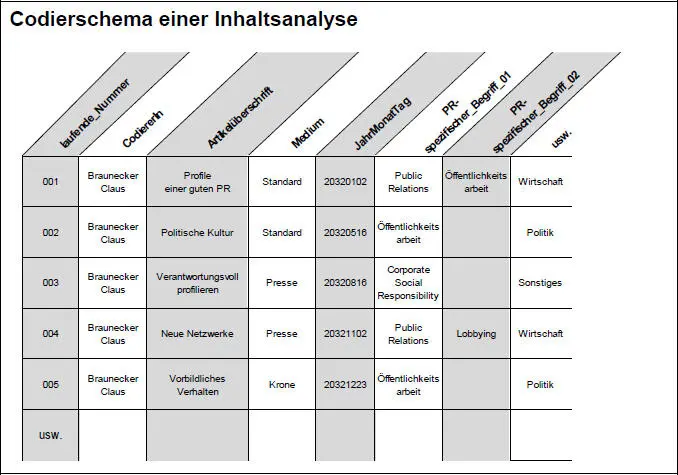
Abbildung 3: Beispielhaftes Codierschema für eine Inhaltsanalyse
Abbildung 3 zeigt als Beispiel einen konstruierten (zur Veranschaulichung dienenden) Auszug aus einem Codierschema einer quantitativen Inhaltsanalyse. Das Codierschema ist konsistent zum Codebuch in Abbildung 4 ab Seite 26 und wurde mit Excel angelegt.
Bevor die Inhaltsanalyse startet, ist es sinnvoll, das Codierschema bei wenigen Analyseelementen „auszuprobieren‟ ( Pretest). Treten dabei noch Probleme (Unklarheiten) auf, sollte das Schema unbedingt nachjustiert werden.
Sehr bedeutsam ist auch, dass alle, die an der Inhaltsanalyse mitarbeiten, die Inhalte nach denselben Grundsätzen im Codierschema erfassen bzw. eintragen: Es muss unbedingt sichergestellt sein, dass verschiedene Menschen die Inhalte in dieselben Kategorien einordnen ( INTER-Coder-Reliabilität). Zur überprüfung der Inter-Coder-Reliabilität gibt es eigene Testverfahren (z.B. der „Holsti-Test‟ auf Seite 107 im Kapitel „6.5.2 | Reliabilität‟). Außerdem muss jede Person, die heute Inhalte klassifiziert, dieselben Inhalte auch morgen oder übermorgen noch ident erfassen ( INTRA-Coder-Reliabilität).
Zur Sicherstellung einer geregelten und reliablen Datenerfassung ist es unbedingt erforderlich, noch vor Beginn der Codierarbeit ein sogenanntes Codebuch zu erstellen.
[26]
Dort werden die Analyseeinheiten 16und Analyseinhalte im Detail definiert und alle Codierungsregeln festgelegt.
Die folgende Abbildung zeigt Auszüge aus einem 20-seitigen(!) Codebuch.
Die Analyse beschäftigte sich mit der Berichterstattung österreichischer Printmedien über Public Relations. Das Codebuch zur Analyse wurde in Anlehnung an Kerl 2007 und Bur- KART/RUßMANN 2010 erstellt.17 Für die hier beispielhafte Abbildung erfolgten geringfügige Adaptierungen. [27]


Abbildung 4: Codebuch einer Inhaltsanalyse (Auszüge, adaptiert) [28]
In heutiger Zeit sind sehr viele Bild- und Textelemente digital verfügbar. Ob es sich dabei um massenmediale Kommunikation oder zwischenmenschliche Interaktionen in Social Media handelt: Analysen gespeicherter, allgemein zugänglicher Inhalte sind weit verbreitet.
Eine Institution möchte z.B. in Erfahrung bringen, wie sich eine neu eingeführte Dienstleistung im Netz verbreitet, wie sie angenommen, wie darüber kommuniziert wird.
Menschen, die das Netz themenbezogen durchsuchen, benötigen Zeit, der monetäre Aufwand ist hoch. Da liegt es nahe, stattdessen Suchsoftware 18einzusetzen. Eine aktuell sehr große Vielfalt an Textanalyse-Tools bietet die Möglichkeit, das Netz (oder Datenbanken) nach definierten Begriffen ( Keywords) zu durchforsten.
Automatisierte Textanalysen können mit wenig Aufwand gesuchte Begriffe, Textstellen usw. (global) auffinden 19und automatisiert Ergebnisberichte mit Häufigkeiten erstellen.
Wie oft z.B. eine neue Marke in den Sozialen Netzwerken diskutiert wird, kann relativ einfach automatisiert gezählt werden.
Wer jedoch (auch) Bilder analysieren bzw. Inhalte regionalisiert betrachten oder gar bewerten möchte, stößt schnell an die Grenzen der Automatisierungen: Vertiefende Forschung ist ohne intensiveres menschliches Zutun nicht derart einfach durchführbar.
Rein technische Sentiment-Analysen zur Bedeutung von Inhalten sind bereits auf syntaktisch „einfachere‟ englische Texte angewandt schwierig umsetzbar. Für die deutsche Sprache sind sie nur schwer realisierbar, weil stark fehlerbehaftet. 20
Softwarealgorithmen versuchen hier, über das gemeinsame Auftreten von Worten „ähnlichkeitscluster‟ zu definieren und Texte nach diesen zu gruppieren. 21Das scheitert aber oft am richtigen Interpretieren von Bedeutungszusammenhängen oder am Bildmaterial.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «How to do empirische Sozialforschung»
Представляем Вашему вниманию похожие книги на «How to do empirische Sozialforschung» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «How to do empirische Sozialforschung» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.