Computational Statistics in Data Science
Здесь есть возможность читать онлайн «Computational Statistics in Data Science» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Computational Statistics in Data Science
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Computational Statistics in Data Science: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Computational Statistics in Data Science»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Computational Statistics in Data Science
Computational Statistics in Data Science
Wiley StatsRef: Statistics Reference Online
Computational Statistics in Data Science
Computational Statistics in Data Science — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Computational Statistics in Data Science», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
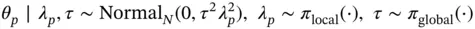
The idea is that the global scale parameter 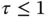 would shrink most
would shrink most 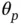 s toward zero, while the local scale
s toward zero, while the local scale 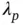 s, with its heavy‐tailed prior
s, with its heavy‐tailed prior  , allow a small number of
, allow a small number of 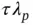 and hence
and hence 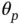 s to be estimated away from zero. While motivated by two different conceptual frameworks, the spike‐and‐slab can be viewed as a subset of global–local priors in which
s to be estimated away from zero. While motivated by two different conceptual frameworks, the spike‐and‐slab can be viewed as a subset of global–local priors in which  is chosen as a mixture of delta masses placed at
is chosen as a mixture of delta masses placed at 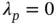 and
and 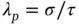 . Continuous shrinkage mitigates the multimodality of spike‐and‐slab by smoothly bridging small and large values of
. Continuous shrinkage mitigates the multimodality of spike‐and‐slab by smoothly bridging small and large values of 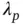 .
.
On the other hand, the use of continuous shrinkage priors does not address the increasing computational burden from growing 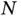 and
and 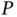 in modern applications. Sparse regression posteriors under global–local priors are amenable to an effective Gibbs sampler, a popular class of MCMC we describe further in Section 4.1. Under the linear and logistic models, the computational bottleneck of this Gibbs sampler stems from the need for repeated updates of
in modern applications. Sparse regression posteriors under global–local priors are amenable to an effective Gibbs sampler, a popular class of MCMC we describe further in Section 4.1. Under the linear and logistic models, the computational bottleneck of this Gibbs sampler stems from the need for repeated updates of 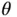 from its conditional distribution
from its conditional distribution
(4) 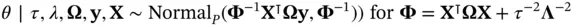
where 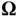 is an additional parameter of diagonal matrix and
is an additional parameter of diagonal matrix and 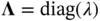 . 5 Sampling from this high‐dimensional Gaussian distribution requires
. 5 Sampling from this high‐dimensional Gaussian distribution requires 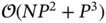 operations with the standard approach [58]:
operations with the standard approach [58]: 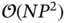 for computing the term
for computing the term 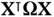 and
and 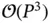 for Cholesky factorization of
for Cholesky factorization of 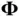 . While an alternative approach by Bhattacharya et al . [48] provides the complexity of
. While an alternative approach by Bhattacharya et al . [48] provides the complexity of 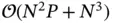 , the computational cost remains problematic in the big
, the computational cost remains problematic in the big 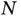 and big
and big 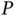 regime at
regime at 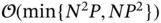 after choosing the faster of the two.
after choosing the faster of the two.
3.1.2 Conjugate gradient sampler for structured high‐dimensional Gaussians
The conjugate gradient (CG) sampler of Nishimura and Suchard [57] combined with their prior‐preconditioning technique overcomes this seemingly inevitable 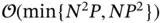 growth of the computational cost. Their algorithm is based on a novel application of the CG method [59, 60], which belongs to a family of iterative methods in numerical linear algebra. Despite its first appearance in 1952, CG received little attention for the next few decades, only making its way into major software packages such as MATLAB in the 1990s [61]. With its ability to solve a large and structured linear system
growth of the computational cost. Their algorithm is based on a novel application of the CG method [59, 60], which belongs to a family of iterative methods in numerical linear algebra. Despite its first appearance in 1952, CG received little attention for the next few decades, only making its way into major software packages such as MATLAB in the 1990s [61]. With its ability to solve a large and structured linear system 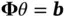 via a small number of matrix–vector multiplications
via a small number of matrix–vector multiplications 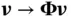 without ever explicitly inverting
without ever explicitly inverting 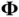 , however, CG has since emerged as an essential and prototypical algorithm for modern scientific computing [62, 63].
, however, CG has since emerged as an essential and prototypical algorithm for modern scientific computing [62, 63].
Despite its earlier rise to prominence in other fields, CG has not found practical applications in Bayesian computation until rather recently [57, 64]. We can offer at least two explanations for this. First, being an algorithm for solving a deterministic linear system, it is not obvious how CG would be relevant to Monte Carlo simulation, such as sampling from 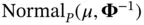 ; ostensively, such a task requires computing a “square root”
; ostensively, such a task requires computing a “square root” 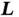 of the precision matrix so that
of the precision matrix so that 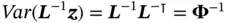 for
for 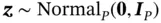 . Secondly, unlike direct linear algebra methods, iterative methods such as CG have a variable computational cost that depends critically on the user's choice of a preconditioner and thus cannot be used as a “black‐box” algorithm. 6 In particular, this novel application of CG to Bayesian computation is a reminder that other powerful ideas in other computationally intensive fields may remain untapped by the statistical computing community; knowledge transfers will likely be facilitated by having more researchers working at intersections of different fields.
. Secondly, unlike direct linear algebra methods, iterative methods such as CG have a variable computational cost that depends critically on the user's choice of a preconditioner and thus cannot be used as a “black‐box” algorithm. 6 In particular, this novel application of CG to Bayesian computation is a reminder that other powerful ideas in other computationally intensive fields may remain untapped by the statistical computing community; knowledge transfers will likely be facilitated by having more researchers working at intersections of different fields.
Интервал:
Закладка:
Похожие книги на «Computational Statistics in Data Science»
Представляем Вашему вниманию похожие книги на «Computational Statistics in Data Science» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.
![Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]](/books/438007/roman-zykov-roman-s-data-science-kak-monetizirova-thumb.webp)











Обсуждение, отзывы о книге «Computational Statistics in Data Science» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.