Savo G. Glisic - Artificial Intelligence and Quantum Computing for Advanced Wireless Networks
Здесь есть возможность читать онлайн «Savo G. Glisic - Artificial Intelligence and Quantum Computing for Advanced Wireless Networks» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Artificial Intelligence and Quantum Computing for Advanced Wireless Networks
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Artificial Intelligence and Quantum Computing for Advanced Wireless Networks: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Artificial Intelligence and Quantum Computing for Advanced Wireless Networks»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
A practical overview of the implementation of artificial intelligence and quantum computing technology in large-scale communication networks Artificial Intelligence and Quantum Computing for Advanced Wireless Networks
Artificial Intelligence and Quantum Computing for Advanced Wireless Networks
Artificial Intelligence and Quantum Computing for Advanced Wireless Networks — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Artificial Intelligence and Quantum Computing for Advanced Wireless Networks», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
(5.26) 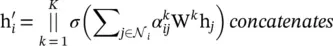
(5.27) 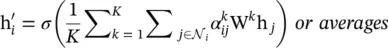
where 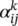 is the normalized attention coefficient computed by the k ‐th attention mechanism. The attention architecture in [35] has several properties: (i) the computation of the node‐neighbor pairs is parallelizable, thus making the operation efficient; (ii) it can be applied to graph nodes with different degrees by specifying arbitrary weights to neighbors; and (iii) it can be easily applied to inductive learning problems.
is the normalized attention coefficient computed by the k ‐th attention mechanism. The attention architecture in [35] has several properties: (i) the computation of the node‐neighbor pairs is parallelizable, thus making the operation efficient; (ii) it can be applied to graph nodes with different degrees by specifying arbitrary weights to neighbors; and (iii) it can be easily applied to inductive learning problems.
Apart from different variants of GNNs, several general frameworks have been proposed that aim to integrate different models into a single framework.
Message passing neural networks ( MPNNs ) [36]: This framework abstracts the commonalities between several of the most popular models for graph‐structured data, such as spectral approaches and non‐spectral approaches in graph convolution, gated GNNs, interaction networks, molecular graph convolutions, and deep tensor neural networks. The model contains two phases, a message passing phase and a readout phase . The message passing phase (namely, the propagation step) runs for T time steps and is defined in terms of th message function M tand the vertex update function U t. Using messages  , the updating functions of the hidden states
, the updating functions of the hidden states 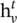 are
are
(5.28) 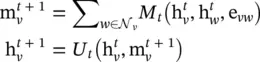
where e vwrepresents features of the edge from node v to w . The readout phase computes a feature vector for the whole graph using the readout function R according to
(5.29) 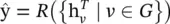
where T denotes the total time steps. The message function M t, vertex update function U t, and readout function R could have different settings. Hence, the MPNN framework could generalize several different models via different function settings. Here, we give an example of generalizing GGNN, and other models’ function settings could be found in Eq. (5.36). The function settings for GGNNs are
(5.30) 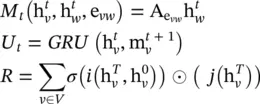
where 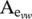 is the adjacency matrix, one for each edge label e . The is the gated recurrent unit introduced in [25]. i and j are neural networks in function R .
is the adjacency matrix, one for each edge label e . The is the gated recurrent unit introduced in [25]. i and j are neural networks in function R .
Non‐local neural networks ( NLNN ) are proposed for capturing long‐range dependencies with deep neural networks by computing the response at a position as a weighted sum of the features at all positions (in space, time, or spacetime). The generic non‐local operation is defined as
(5.31) 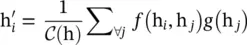
where i is the index of an output position, and j is the index that enumerates all possible positions. f (h i, h j) computes a scalar between i and j representing the relation between them. g (h j) denotes a transformation of the input h j, and a factor 1/ 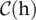 is utilized to normalize the results.
is utilized to normalize the results.
There are several instantiations with different f and g settings. For simplicity, the linear transformation can be used as the function g . That means g (h j) = W gh j, where W gis a learned weight matrix. The Gaussian function is a natural choice for function f , giving 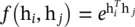 , where
, where 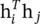 is dot‐product similarity and C (h) =∑ ∀j f (h i, h j). It is straightforward to extend the Gaussian function by computing similarity in the embedding space giving
is dot‐product similarity and C (h) =∑ ∀j f (h i, h j). It is straightforward to extend the Gaussian function by computing similarity in the embedding space giving 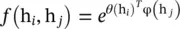 with θ (h i) = W θh i, φ(h j) = W φh j, and
with θ (h i) = W θh i, φ(h j) = W φh j, and 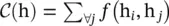 . The function f can also be implemented as a dot‐product similarity f (h i, h j) = θ (h i) Tφ(h j). Here, the factor
. The function f can also be implemented as a dot‐product similarity f (h i, h j) = θ (h i) Tφ(h j). Here, the factor 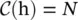 , where N is the number of positions in h. Concatenation can also be used, defined as
, where N is the number of positions in h. Concatenation can also be used, defined as 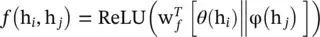 , where w fis a weight vector projecting the vector to a scalar and
, where w fis a weight vector projecting the vector to a scalar and 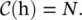
5.1.3 Graph Networks
The Graph Network (GN) framework [37] generalizes and extends various GNN, MPNN, and NLNN approaches. A graph is defined as a 3‐tuple G = (u, H , E ) ( H is used instead of V for notational consistency). u is a global attribute, 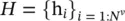 is the set of nodes (of cardinality N v), where each h iis a node’s attribute.
is the set of nodes (of cardinality N v), where each h iis a node’s attribute. 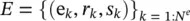 is the set of edges (of cardinality N e), where each e kis the edge’s attribute, r kis the index of the receiver node, and s kis the index of the sender node.
is the set of edges (of cardinality N e), where each e kis the edge’s attribute, r kis the index of the receiver node, and s kis the index of the sender node.
Интервал:
Закладка:
Похожие книги на «Artificial Intelligence and Quantum Computing for Advanced Wireless Networks»
Представляем Вашему вниманию похожие книги на «Artificial Intelligence and Quantum Computing for Advanced Wireless Networks» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Artificial Intelligence and Quantum Computing for Advanced Wireless Networks» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.