Savo G. Glisic - Artificial Intelligence and Quantum Computing for Advanced Wireless Networks
Здесь есть возможность читать онлайн «Savo G. Glisic - Artificial Intelligence and Quantum Computing for Advanced Wireless Networks» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Artificial Intelligence and Quantum Computing for Advanced Wireless Networks
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Artificial Intelligence and Quantum Computing for Advanced Wireless Networks: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Artificial Intelligence and Quantum Computing for Advanced Wireless Networks»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
A practical overview of the implementation of artificial intelligence and quantum computing technology in large-scale communication networks Artificial Intelligence and Quantum Computing for Advanced Wireless Networks
Artificial Intelligence and Quantum Computing for Advanced Wireless Networks
Artificial Intelligence and Quantum Computing for Advanced Wireless Networks — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Artificial Intelligence and Quantum Computing for Advanced Wireless Networks», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
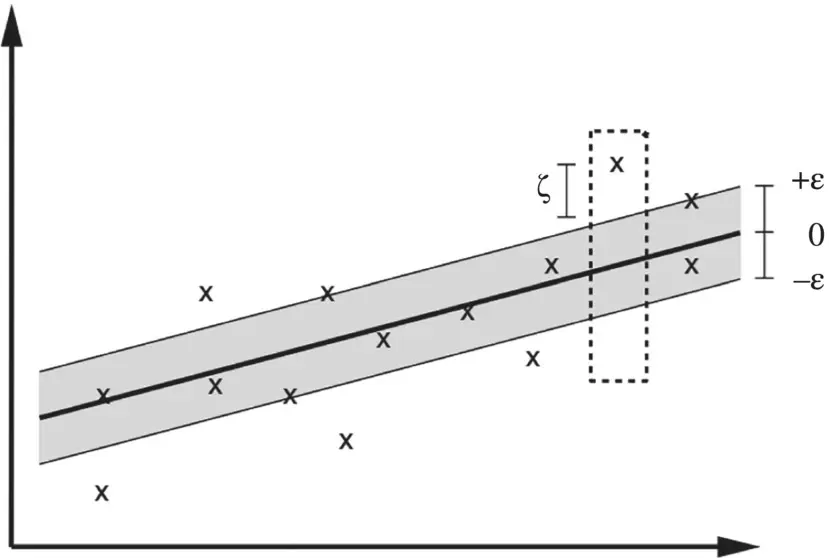
Figure 4.6 Illustration of the soft margin for a linear support vector machine (SVM).
(4.47) 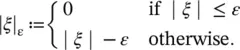
Figure 2.7of Chapter 2is modified to reflect better the definitions introduced in this section and presented as Figure 4.6. Often, the optimization problem, Eq. (4.46), can be solved more easily in its dual formulation. The dual formulation provides also the key for extending SV machine to nonlinear functions.
Lagrange function: The key idea here is to construct a Lagrange function from the objective function ( primal objective function) and the corresponding constraints, by introducing a dual set of variables [95]. It can be shown that this function has a saddle point with respect to the primal and dual variables at the solution. So we have
(4.48) 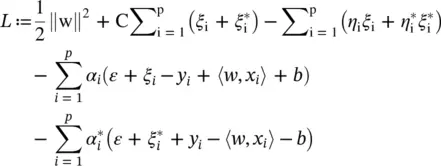
Here, L is the Lagrangian, and η i, 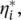 α i,
α i, 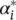 are Lagrange multipliers. Hence, the dual variables in Eq. (4.48)have to satisfy positivity constraints, that is,
are Lagrange multipliers. Hence, the dual variables in Eq. (4.48)have to satisfy positivity constraints, that is, 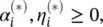 where by
where by 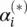 , we jointly refer to α iand
, we jointly refer to α iand 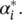 In the saddle point, the partial derivatives of L with respect to the primal variables
In the saddle point, the partial derivatives of L with respect to the primal variables 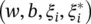 have to vanish; that is,
have to vanish; that is, 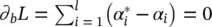 ,
, 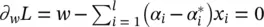 and
and 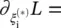
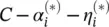 = 0. Substituting these conditions into Eq. (4.48)yields the dual optimization problem:
= 0. Substituting these conditions into Eq. (4.48)yields the dual optimization problem:
(4.49) 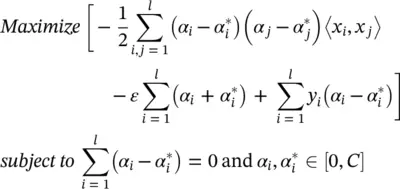
In deriving Eq. (4.49), we already eliminated the dual variables η i, 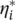 through condition
through condition 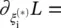
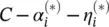 = 0, which can be reformulated as
= 0, which can be reformulated as 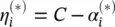 . Equation
. Equation 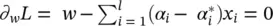 can be rewritten as
can be rewritten as 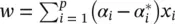 , giving
, giving
(4.50) 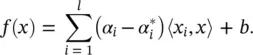
This is the so‐called support vector expansion ; that is, w can be completely described as a linear combination of the training patterns x i. In a sense, the complexity of a function’s representation by SVs is independent of the dimensionality of the input space X , and depends only on the number of SVs. Moreover, note that the complete algorithm can be described in terms of dot products between the data. Even when evaluating f ( x ), we need not compute w explicitly. These observations will come in handy for the formulation of a nonlinear extension.
Computing b : Parameter b can be computed by exploiting the so‐called Karush−Kuhn−Tucker (KKT) conditions stating that at the point of the solution the product between dual variables and constraints has to vanish, giving α i( ε + ξ i− y i+ 〈 w , x i〉 + b ) = 0, 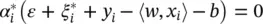 , ( C − α i) ξ i= 0 and
, ( C − α i) ξ i= 0 and 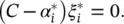 This allows us to draw several useful conclusions:
This allows us to draw several useful conclusions:
1 Only samples (xi, yi) with corresponding lie outside the ε ‐insensitive tube.
2 ; that is, there can never be a set of dual variables αi , that are both simultaneously nonzero. This allows us to conclude that(4.51) (4.52)
In conjunction with an analogous analysis on 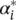 , we have for b
, we have for b
(4.53) 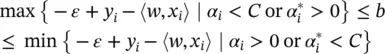
Kernels: We are interested in making the SV algorithm nonlinear. This, for instance, could be achieved by simply preprocessing the training patterns x iby a map Φ : X → F into some feature space F , as already described in Chapter 2, and then applying the standard SV regression algorithm. Let us have a brief look at the example given in Figure 2.8of Chapter 2. We had (quadratic features in ℝ 2) with the map Φ : ℝ 2→ ℝ 3with Φ 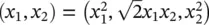 . It is understood that the subscripts in this case refer to the components of x ∈ ℝ 2. Training a linear SV machine on the preprocessed features would yield a quadratic function as indicated in Figure 2.8. Although this approach seems reasonable in the particular example above, it can easily become computationally infeasible for both polynomial features of higher order and higher dimensionality.
. It is understood that the subscripts in this case refer to the components of x ∈ ℝ 2. Training a linear SV machine on the preprocessed features would yield a quadratic function as indicated in Figure 2.8. Although this approach seems reasonable in the particular example above, it can easily become computationally infeasible for both polynomial features of higher order and higher dimensionality.
Интервал:
Закладка:
Похожие книги на «Artificial Intelligence and Quantum Computing for Advanced Wireless Networks»
Представляем Вашему вниманию похожие книги на «Artificial Intelligence and Quantum Computing for Advanced Wireless Networks» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Artificial Intelligence and Quantum Computing for Advanced Wireless Networks» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.