Savo G. Glisic - Artificial Intelligence and Quantum Computing for Advanced Wireless Networks
Здесь есть возможность читать онлайн «Savo G. Glisic - Artificial Intelligence and Quantum Computing for Advanced Wireless Networks» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Artificial Intelligence and Quantum Computing for Advanced Wireless Networks
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Artificial Intelligence and Quantum Computing for Advanced Wireless Networks: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Artificial Intelligence and Quantum Computing for Advanced Wireless Networks»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
A practical overview of the implementation of artificial intelligence and quantum computing technology in large-scale communication networks Artificial Intelligence and Quantum Computing for Advanced Wireless Networks
Artificial Intelligence and Quantum Computing for Advanced Wireless Networks
Artificial Intelligence and Quantum Computing for Advanced Wireless Networks — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Artificial Intelligence and Quantum Computing for Advanced Wireless Networks», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Multi‐layer neural networks: A neural network is built up by incorporating the basic neuron model into different configurations. One example is the Hopfield network, where the output of each neuron can have a connection to the input of all neurons in the network, including a self‐feedback connection. Another option is the multi ‐ layer feedforward network illustrated in Figure 3.2. Here, we have layers of neurons where the output of a neuron in a given layer is input to all the neurons in the next layer. We may also have sparse connections or direct connections that may bypass layers. In these networks, no feedback loops exist within the structure. These network are sometimes referred to as backpropagation networks .
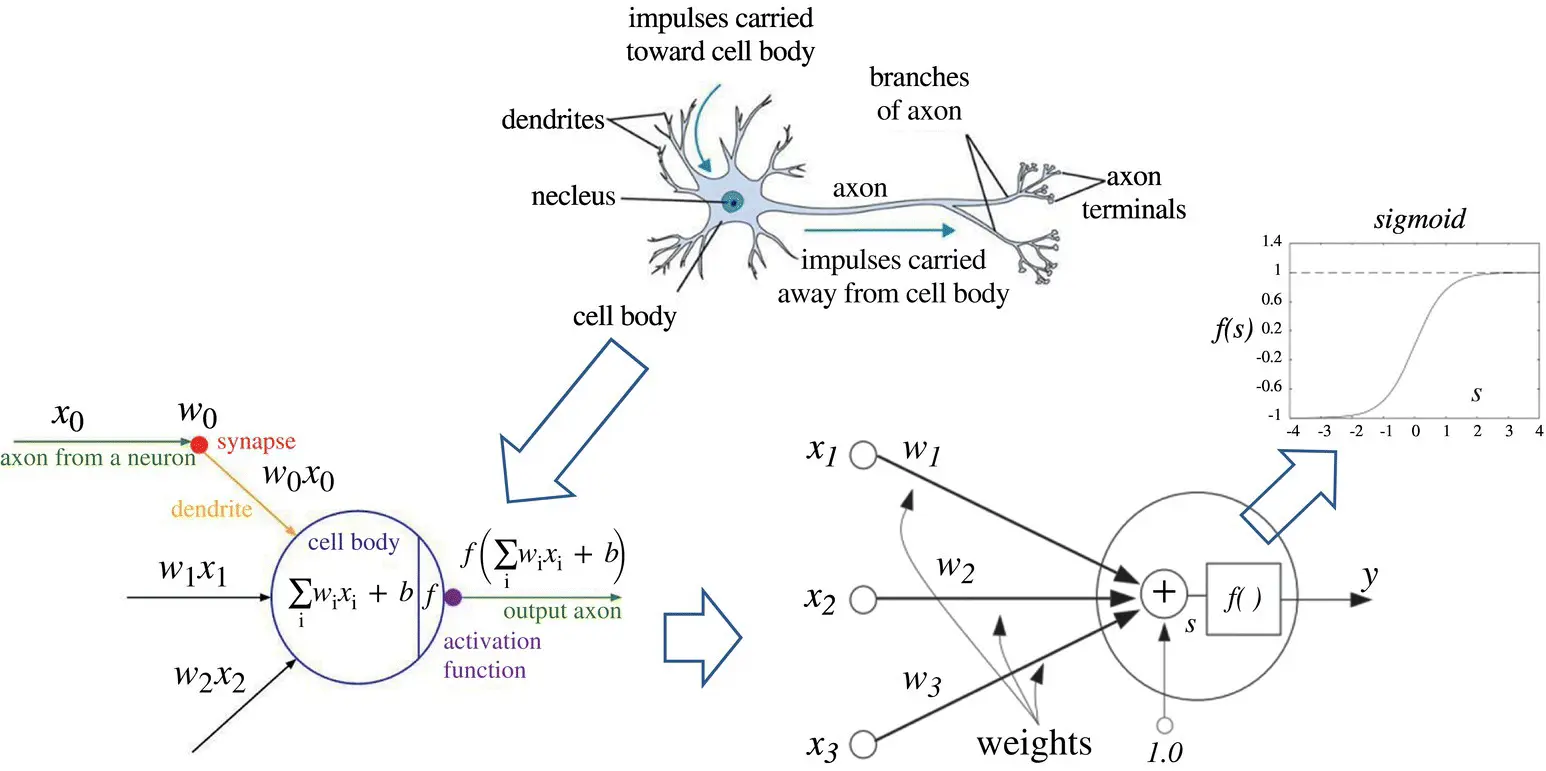
Figure 3.1 From biological to mathematical simplified model of a neuron.
Source: CS231n Convolutional Neural Networks for Visual Recognition [1].
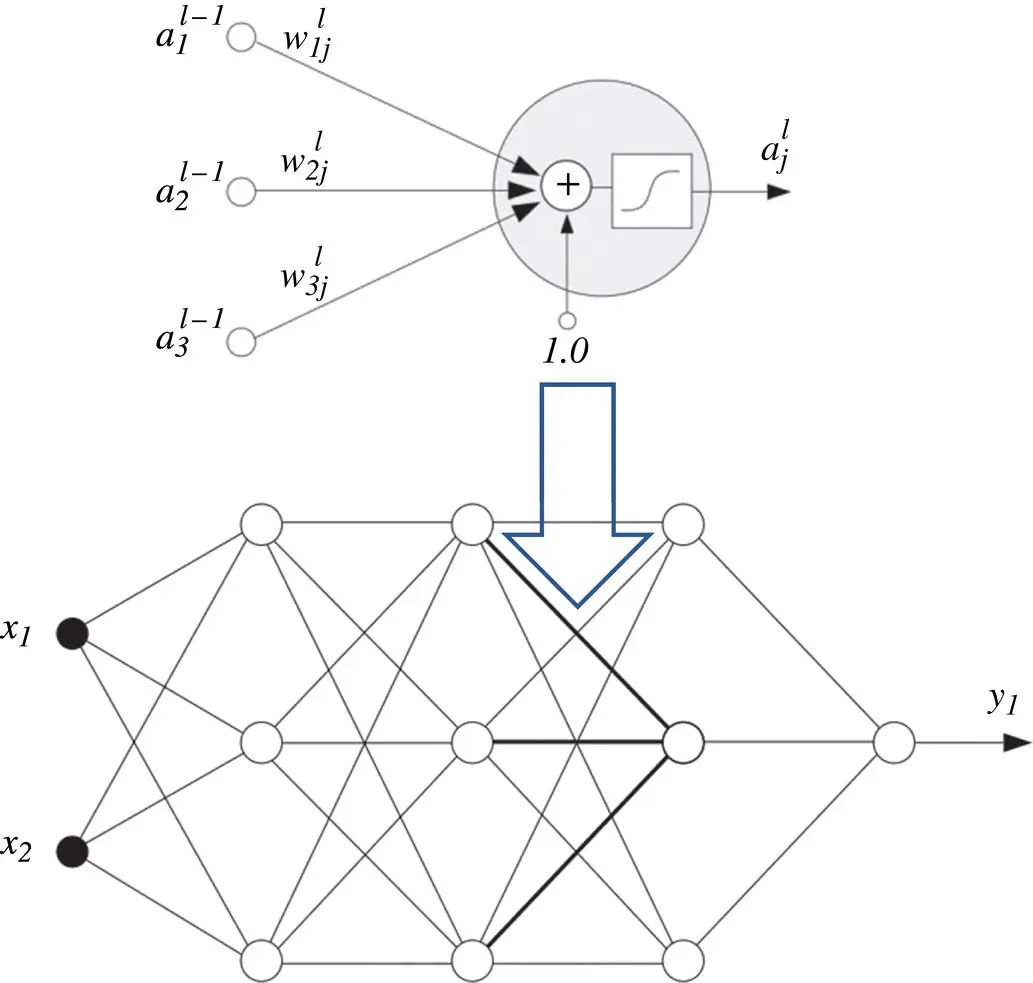
Figure 3.2 Block diagram of feedforward network.
Notation: A single neuron extracted from the l ‐th layer of an L ‐layer network is also depicted in Figure 3.2. Parameters 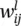 denote the weights on the links between neuron i in the previous layer and neuron j in layer l . The output of the j ‐th neuron in layer l is represented by the variable
denote the weights on the links between neuron i in the previous layer and neuron j in layer l . The output of the j ‐th neuron in layer l is represented by the variable 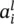 . The outputs
. The outputs 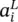 in the last L ‐th layer represent the overall outputs of the network. Here, we use notation y ifor the outputs as
in the last L ‐th layer represent the overall outputs of the network. Here, we use notation y ifor the outputs as 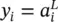 . Parameters x i, defined as inputs to the network, may be viewed as a 0‐th layer with notation
. Parameters x i, defined as inputs to the network, may be viewed as a 0‐th layer with notation 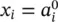 . These definitions are summarized in Table 3.1.
. These definitions are summarized in Table 3.1.
Table 3.1 Multi‐layer network notation.
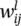 |
Weight connecting neuron i in layer l − 1 to neuron j in layer l |
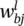 |
Bias weight for neuron j in layer l |
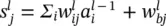 |
Summing junction for neuron j in layer l |
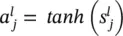 |
Activation (output) value for neuron j in layer l |
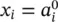 |
i ‐th external input to network |
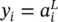 |
i ‐th output to network |
Define an input vector x = [ x 0, x 1, x 2, … x N] and output vector y = [ y 0, y 1, y 2, … y M]. The network maps, y = N ( w , x ), the input x to the outputs y using the weights w. Since fixed weights are used, this mapping is static ; there are no internal dynamics. Still, this network is a powerful tool for computation.
It has been shown that with two or more layers and a sufficient number of internal neurons, any uniformly continuous function can be represented with acceptable accuracy. The performance rests on the ways in which this “universal function approximator” is utilized.
3.1.2 Weights Optimization
The specific mapping with a network is obtained by an appropriate choice of weight values. Optimizing a set of weights is referred to as network training. An example of supervised learning scheme is shown in Figure 3.3. A training set of input vectors associated with the desired output vector, {(x 1, d 1), … (x P, d P)}, is provided. The difference between the desired output and the actual output of the network, for a given input sequence x, is defined as the error
(3.3) 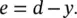
The overall objective function to be minimized over the training set is the given squared error
(3.4) 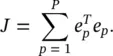
The training should find the set of weights w that minimizes the cost J subject to the constraint of the network topology. We see that training a neural network represent a standard optimization problem.
A stochastic gradient descent (SGD) algorithm is an option as an optimization method. For each sample from the training set, the weights are adapted as
(3.5) 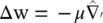
where 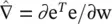 is the error gradient for the current input pattern, and μ is the learning rate.
is the error gradient for the current input pattern, and μ is the learning rate.
Backpropagation: This is a standard way to find 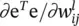 in Eq. (3.5). Here we provide a formal derivation.
in Eq. (3.5). Here we provide a formal derivation.
Single neuron case – Consider first a single linear neuron, which we may describe compactly as
(3.6) 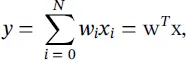
where w = [ w 0, w 1, … w N] and x = [1, x 1, … x N]. In this simple setup
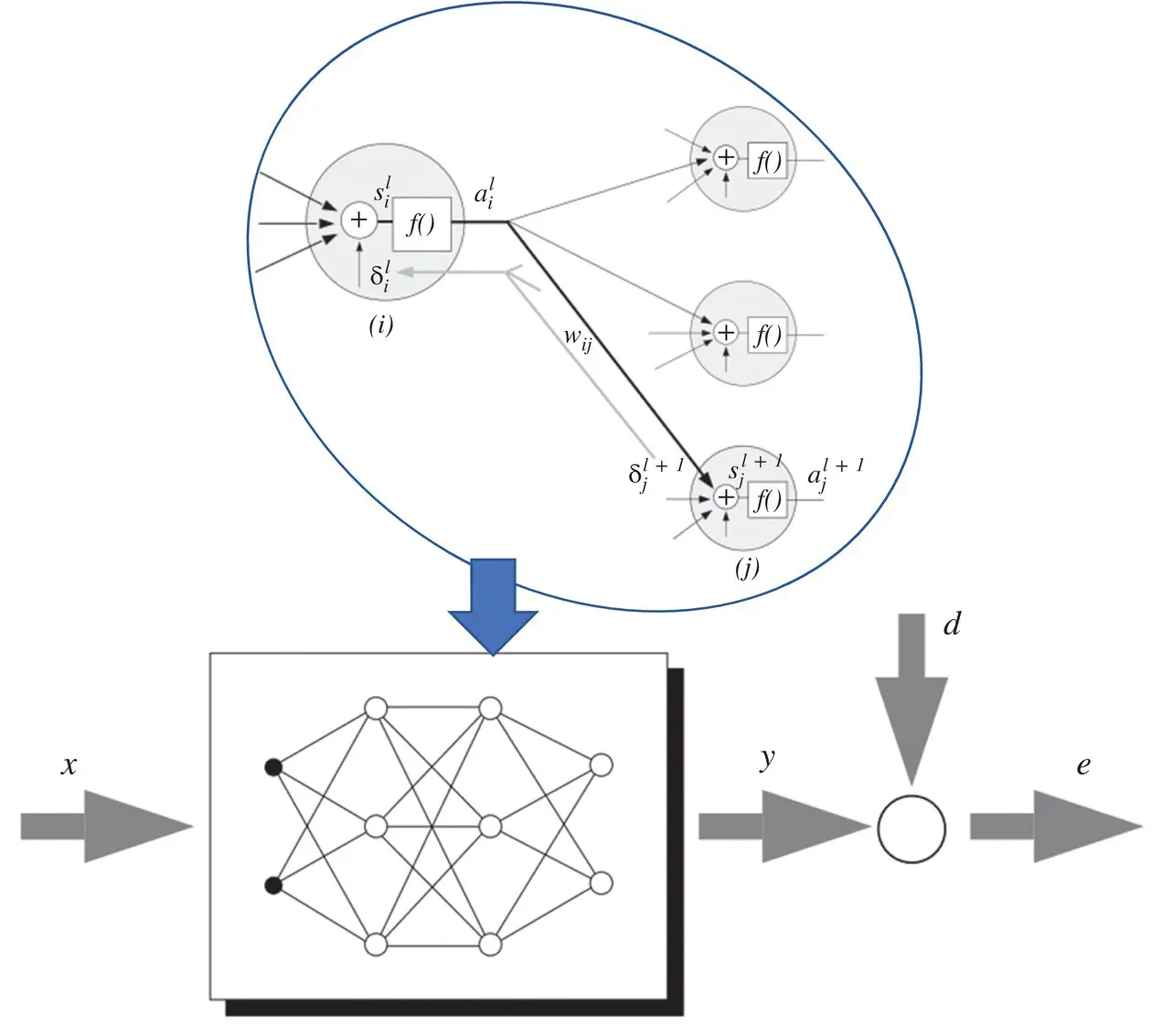
Figure 3.3 Schematic representation of supervised learning.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Artificial Intelligence and Quantum Computing for Advanced Wireless Networks»
Представляем Вашему вниманию похожие книги на «Artificial Intelligence and Quantum Computing for Advanced Wireless Networks» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Artificial Intelligence and Quantum Computing for Advanced Wireless Networks» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.