Savo G. Glisic - Artificial Intelligence and Quantum Computing for Advanced Wireless Networks
Здесь есть возможность читать онлайн «Savo G. Glisic - Artificial Intelligence and Quantum Computing for Advanced Wireless Networks» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Artificial Intelligence and Quantum Computing for Advanced Wireless Networks
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Artificial Intelligence and Quantum Computing for Advanced Wireless Networks: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Artificial Intelligence and Quantum Computing for Advanced Wireless Networks»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
A practical overview of the implementation of artificial intelligence and quantum computing technology in large-scale communication networks Artificial Intelligence and Quantum Computing for Advanced Wireless Networks
Artificial Intelligence and Quantum Computing for Advanced Wireless Networks
Artificial Intelligence and Quantum Computing for Advanced Wireless Networks — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Artificial Intelligence and Quantum Computing for Advanced Wireless Networks», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Error ‐ based pruning ( ebp ): This is an evolution of pessimistic pruning. As in pessimistic pruning‚ the error rate is estimated using the upper bound of the statistical confidence interval for proportions:
(2.25) 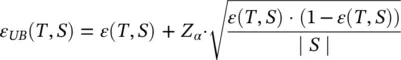
where ε ( T , S ) denotes the misclassification rate of the tree T on the training set S . Z is the inverse of the standard normal cumulative distribution, and α is the desired significance level. Let subtree ( T , t ) denote the subtree rooted by the node t . Let maxchild ( T , t ) denote the most frequent child node of t (namely, most of the instances in S reach this particular child), and let S tdenote all instances in S that reach the node. The procedure performs bottom‐up traversal over all nodes and compares the following values:
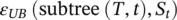
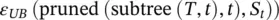
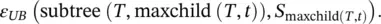
According to the lowest value, the procedure either leaves the tree as is, prunes the node, or replaces the node t with the subtree rooted by maxchild ( T , t ).
Optimal pruning (opt): Bohanec and Bratko [17] introduced an algorithm guaranteeing optimality called optimal pruning ( opt ). This algorithm finds the optimal pruning based on dynamic programming, with a complexity of θ (∣ l ( T )| 2), where T is the initial decision tree. Almuallim [18] introduced an improvement of opt called opt ‐2 , which also performs optimal pruning using dynamic programming. However, the time and space complexities of opt‐2 are both Θ( ∣ l ( T *) ∣ ∣internal ( T ) ∣ ), where T * is the target (pruned) decision tree, and T is the initial decision tree.
Since the pruned tree is usually much smaller than the initial tree and the number of internal nodes is smaller than the number of leaves, opt‐2 is usually more efficient than opt in terms of computational complexity.
Minimum description length ( MDL) pruning : Rissanen [19], Quinlan and Rivest [20], and Mehta et al. [21] used the MDL to evaluate the generalized accuracy of a node. This method measures the size of a decision tree by means of the number of bits required to encode the tree. The MDL method prefers decision trees that can be encoded with fewer bits. Mehta et al. [21] indicate that the cost of a split at a leaf t can be estimated as
(2.26) 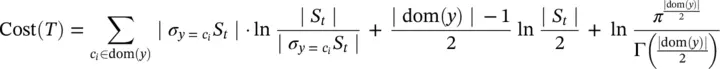
where ∣ S t∣ denote the number of instances that have reached the node.
The splitting cost of an internal node is calculated based on the cost aggregation of its children.
2.2.3 Dimensionality Reduction Techniques
In this section, we provide an overview of the mathematical properties and foundations of the various dimensionality reduction techniques [22–24]
There are several dimensionality reduction techniques specifically designed for time series. These methods specifically exploit the frequential content of the signal and its usual sparseness in the frequency space. The most popular methods are those based on wavelets [25, 26], and a distant second is empirical mode decomposition [27, 28] (the reader is referred to the references above for further details). We do not cover these techniques here since they are not usually applied for the general‐purpose dimensionality reduction of data. From a general point of view, we may say that wavelets project the input time series onto a fixed dictionary (see Section 2.3). This dictionary has the property of making the projection sparse (only a few coefficients are sufficiently large), and the dimensionality reduction is obtained by setting most coefficients (the small ones) to zero. Empirical mode decomposition instead constructs a dictionary specially adapted to each input signal.
To maintain the consistency of this review, we do not cover those dimensionality reduction techniques that take into account the class of observations; that is, there are observations from a class A of objects, observations from a class B, … and the dimensionality reduction technique should maintain, to the extent possible, the separability of the original classes. Fisher’s Linear Discriminant Analysis ) was one of the first techniques to address this issue [29, 30]. Many other works have followed since then; for the most recent works and for a bibliographical review, see [31, 35]. Next, we will focus on vector quantization and mixture models and PCA, which was already introduced to some extent in the previous section.
In the following, we will refer to the observations as input vectors x, whose dimension is M . We will assume that we have N observations, and we will refer to the n th observation as x n. The whole dataset of observations will be X, whereas X will be a M × N matrix with all the observations as columns. Note that non‐bold small letters represent vectors (x), whereas capital, non‐bold letters (X) represent matrices.
The goal of the dimensionality reduction is to find another representation χof a smaller dimension m such that as much information as possible is retained from the original set of observations. This involves some transformation operators from the original vectors onto the new vectors, χ= T (x). These projected vectors are sometimes called feature vectors , and the projection of x nwill be denoted as χ n. There might not be an inverse for this projection, but there must be a way of recovering an approximate value of the original vector, 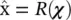 , such that
, such that 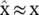 .
.
An interesting property of any dimensionality reduction technique is to consider its stability. In this context, a technique is said to be ε‐stable if for any two input data points, x 1and x 2, the following inequality holds [36]: 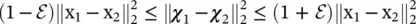 . Intuitively, this equation implies that Euclidean distances in the original input space are relatively conserved in the output feature space.
. Intuitively, this equation implies that Euclidean distances in the original input space are relatively conserved in the output feature space.
Methods based on statistics and information theory: This family of methods reduces the input data according to some statistical or information theory criterion. Somehow, the methods based on information theory can be seen as a generalization of the ones based on statistics in the sense that they can capture nonlinear relationships between variables, can handle interval and categorical variables at the same time, and many of them are invariant to monotonic transformations of the input variables.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Artificial Intelligence and Quantum Computing for Advanced Wireless Networks»
Представляем Вашему вниманию похожие книги на «Artificial Intelligence and Quantum Computing for Advanced Wireless Networks» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Artificial Intelligence and Quantum Computing for Advanced Wireless Networks» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.