Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]
Здесь есть возможность читать онлайн «Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Санкт-Петербург, Год выпуска: 2021, ISBN: 2021, Издательство: Издательство Питер, Жанр: Базы данных, popular_business, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
![Роман Зыков Роман с Data Science. Как монетизировать большие данные [litres] обложка книги](/books/438007/roman-zykov-roman-s-data-science-kak-monetizirova.webp)
- Название:Роман с Data Science. Как монетизировать большие данные [litres]
- Автор:
- Издательство:Издательство Питер
- Жанр:
- Год:2021
- Город:Санкт-Петербург
- ISBN:978-5-4461-1879-3
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Роман с Data Science. Как монетизировать большие данные [litres]: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Роман с Data Science. Как монетизировать большие данные [litres]»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Эта книга предназначена для думающих читателей, которые хотят попробовать свои силы в области анализа данных и создавать сервисы на их основе. Она будет вам полезна, если вы менеджер, который хочет ставить задачи аналитике и управлять ею. Если вы инвестор, с ней вам будет легче понять потенциал стартапа. Те, кто «пилит» свой стартап, найдут здесь рекомендации, как выбрать подходящие технологии и набрать команду. А начинающим специалистам книга поможет расширить кругозор и начать применять практики, о которых они раньше не задумывались, и это выделит их среди профессионалов такой непростой и изменчивой области. Книга не содержит примеров программного кода, в ней почти нет математики.
В формате PDF A4 сохранен издательский макет.
Роман с Data Science. Как монетизировать большие данные [litres] — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Роман с Data Science. Как монетизировать большие данные [litres]», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Обучение без учителя (unsupervised learning) подразумевает, что в данных есть закономерность, но вы не знаете какая (нет зависимой переменной). Это может быть задача разделения датасета на кластеры (кластерный анализ), поиск аномалий, автоэнкодеры (например, для уменьшения размерности пространства фич), метод главных компонент (Principal Component Analysis), коллаборативная фильтрация (рекомендательные системы).
Обучение с подкреплением (reinforcement learning) – модель учится через взаимодействие со средой. Это частный случай модели с учителем, где учителем является не датасет, а реакция среды на какое-то действие, которое мы произвели. Часто применяется при разработке ботов для игр (не только стрелялки, но и шахматы), управлении роботами. В отличие от классического машинного обучения, датасета здесь нет. Агент (например, робот) производит какое-либо действие в среде, получает обратную связь, которая транслируется в награду (reward). Агент учится совершать такие действия, которые максимизируют его награду. Так, например, можно научить робота ходить или играть в шахматы.
Для каждого типа задач классического ML есть соответствующий алгоритм. Например шпаргалка (cheat sheet, рис. 8.2) (https://topdatalab.ru/ref?link=117) для очень популярной библиотеки scikit learn выглядит так:
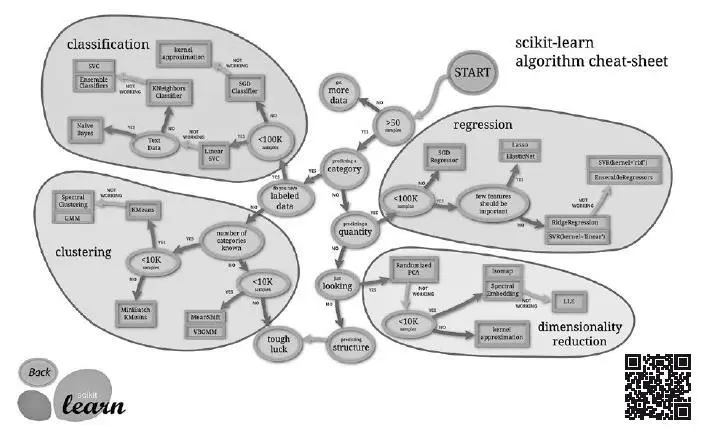
Рис. 8.2.Шпаргалка методов ML (https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html)
В зависимости от задачи и данных, предлагается вариант модели, которая, скорее всего, будет успешной. Именно с этой библиотеки я начал свое изучение ML-моделей в Python, когда участвовал в соревнованиях на Kaggle.
Метрики ML-задач
Если в данных есть неслучайная закономерность, выбрана соответствующая задаче модель и есть достаточный набор данных, то обучение ML-модели не выглядит чем-то сложным. Самый первый шаг – понять, как измерить эффективность модели. Это очень важно: если мы делаем модель, которая будет помогать в реальной жизни, у нее должно быть четкое определение цели. А цель уже выражается метрикой. Например, если нужно, чтобы она прогнозировала спрос на товары, то цель – уменьшить процент расхождения с реальностью (ошибка прогноза). Если по фотографии нужно определить, есть ли там изображение собаки, то цель – увеличить процент правильно угаданных фотографий. В любых задачах на Kaggle есть метрика, по которой выбирают победителя.
Этот шаг новички – и не только они – часто игнорируют или выполняют невнимательно. По опыту работы в Retail Rocket скажу, что ошибка в выборе правильной метрики может стоить очень дорого. Это фундамент всего ML. Сделать это не так просто, как кажется на первый взгляд. К примеру, есть несколько систем тестирования COVID-19 через мазок из горла. Одна из них дает больше ложноположительных результатов (больной на самом деле не болен), вторая – больше ложноотрицательных (пропускает больных, которые заразны). Какую систему выбрать? Если первую, то вы запрете дома много здоровых людей, это повлияет на экономику. Если вторую – то пропущенные больные будут распространять вирус. Такой выбор – это баланс плюсов и минусов. Аналогичные проблемы есть в разработке систем рекомендаций: пусть первый алгоритм выдает более логичные с точки зрения пользователя рекомендации, а второй дает магазину больший доход. (Это означает, что машина обучалась на слабых, но важных сигналах, которые кажутся нам нелогичными, и ее рекомендации приводят к росту продаж, хотя это и невозможно объяснить логикой в силу ограниченности человеческого ума.) Какой алгоритм выбрать? С точки зрения бизнеса – второй, но когда такую систему продают и показывают менеджерам, принимающим решение о покупке, им часто нравится первый вариант. Их можно понять, ведь сайт – это витрина, и она должна выглядеть привлекательно. В итоге приходится трансформировать работающий первый алгоритм, стараясь зафиксировать высокие финансовые показатели, но сделать так, чтобы рекомендации выглядели более логично. Фокус на нескольких метриках сильно усложняет разработку новых алгоритмов.
Любая метрика считается как разность между тем, что прогнозирует модель по входным данным (независимые переменные, или фичи), и тем, что есть на самом деле (зависимая переменная, или outcome). Существует много нюансов расчета метрик, но суть всегда именно в этой разнице. Типовые метрики ML-задач зависят от их класса.
Для регрессии – это среднеквадратичная ошибка (Mean Squared Error, MSE). Считается как сумма квадратов разностей прогнозируемого и действительного значений из датасета, деленное на число примеров в датасете:
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Роман с Data Science. Как монетизировать большие данные [litres]»
Представляем Вашему вниманию похожие книги на «Роман с Data Science. Как монетизировать большие данные [litres]» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Роман с Data Science. Как монетизировать большие данные [litres]» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.