Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]
Здесь есть возможность читать онлайн «Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Санкт-Петербург, Год выпуска: 2021, ISBN: 2021, Издательство: Издательство Питер, Жанр: Базы данных, popular_business, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
![Роман Зыков Роман с Data Science. Как монетизировать большие данные [litres] обложка книги](/books/438007/roman-zykov-roman-s-data-science-kak-monetizirova.webp)
- Название:Роман с Data Science. Как монетизировать большие данные [litres]
- Автор:
- Издательство:Издательство Питер
- Жанр:
- Год:2021
- Город:Санкт-Петербург
- ISBN:978-5-4461-1879-3
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Роман с Data Science. Как монетизировать большие данные [litres]: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Роман с Data Science. Как монетизировать большие данные [litres]»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Эта книга предназначена для думающих читателей, которые хотят попробовать свои силы в области анализа данных и создавать сервисы на их основе. Она будет вам полезна, если вы менеджер, который хочет ставить задачи аналитике и управлять ею. Если вы инвестор, с ней вам будет легче понять потенциал стартапа. Те, кто «пилит» свой стартап, найдут здесь рекомендации, как выбрать подходящие технологии и набрать команду. А начинающим специалистам книга поможет расширить кругозор и начать применять практики, о которых они раньше не задумывались, и это выделит их среди профессионалов такой непростой и изменчивой области. Книга не содержит примеров программного кода, в ней почти нет математики.
В формате PDF A4 сохранен издательский макет.
Роман с Data Science. Как монетизировать большие данные [litres] — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Роман с Data Science. Как монетизировать большие данные [litres]», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Деревья решений
Деревья решения (decision tree) дышат в спину линейным методам по популярности. Это очень наглядный метод (рис. 8.8), который может использоваться для задач классификации и регрессии. Самые лучшие алгоритмы классификации (Catboost, XGboost, Random Forest) основываются на нем. Сам метод нелинейный и представляет собой правила «если…, то…». Само дерево состоит из внутренних узлов и листьев. Внутренние узлы – это условия на независимые переменные (правила). Листья – это уже ответ, в котором содержится вероятность принадлежности к тому или иному классу. Чтобы получить ответ, нужно идти от корня дерева, отвечая на вопросы. Цель – добраться до листа и определить нужный класс.
Дерево строится совсем по иным принципам, чем те, которые мы рассмотрели в линейных методах. Мои дети играют в игру «вопрос-ответ». Один человек загадывает слово, а другие игроки должны с помощью вопросов выяснить его. Допустимые ответы на вопрос только да/нет. Выиграет тот, кто меньшим числом вопросов угадает ответ. С деревом аналогично – начиная от корня дерева, правила строятся таким образом, чтобы за меньшее число шагов дойти до листа.
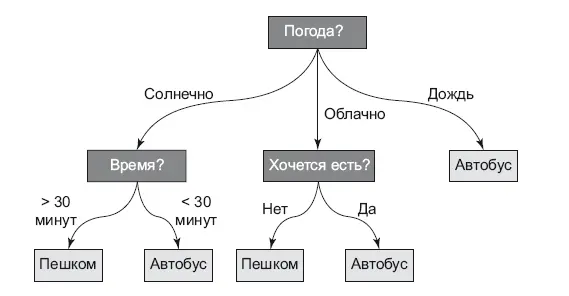
Рис. 8.7.Дерево решений
Для этого вначале выбирается фича. Разделив датасет по ее значению (для непрерывных подбираются пороги), мы получаем наибольшее уменьшение энтропии Шеннона (или наибольший информационный выигрыш). Для этого на каждом шаге происходит полный перебор всех фич и их значений. Этот процесс повторяется много раз, пока мы не достигнем ситуации, когда уже делить нечего, в выборке данных остались только наблюдения одного класса – это и будет листом. Часто это грозит переобучением – полученное дерево слишком сильно подстроилось под выборку, запомнив все данные в листьях. На практике при построении деревьев решений у них ограничивают глубину и максимальное число элементов в листьях. А если ничего не помогает, то проводят «обрезку» дерева (pruning или postpruning). Обрезка идет от листьев к корню. Решение принимается на основе проверки: насколько ухудшится качество дерева, если объединить эти два листа. Для этого используется отдельный небольшой датасет, который не участвовал в обучении [55].
Ошибки обучения
Модель в процессе обучения, если она правильно выбрана, пытается найти закономерности (patterns) и обобщить (generalize) их. Показатели эффективности позволяют сравнивать разные модели или подходы к их обучению путем простого сравнения. Согласитесь, что если у вас будут две модели, ошибка прогнозирования первой равна 15 %, а второй 10 %, то сразу понятно, что следует предпочесть вторую модель. А что будет, если при тестировании в модель попадут данные, которых не было в обучающем датасете? Если при обучении мы получили хорошее качество обобщения модели, то все будет в порядке, ошибка будет небольшой, а если нет, то ошибка может быть очень большой.
Итогом обучения модели могут быть два типа ошибок:
• модель не заметила закономерности (high bias, underfitting – недообучена);
• модель сделала слишком сложную интерпретацию, например, там, где мы видим линейную зависимость, модель увидела квадратичную (high variance, overfitting – переобучена).
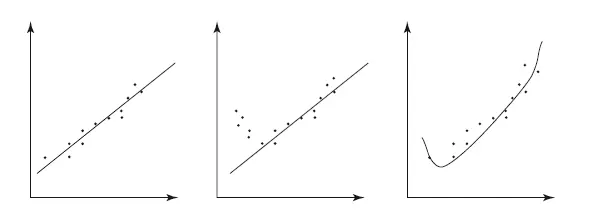
Рис. 8.8.Правильное обучение, недообучение, переобучение
Попробую это продемонстрировать. На картинке (рис. 8.8) изображены результаты экспериментов в виде точек (вспомните лабы по физике в школе). Мы должны найти закономерности – построить линии, их описывающие. На первой картинке все хорошо: прямая линия хорошо описывает данные, расстояния от точек до самой линии небольшие. Модель правильно определила закономерность. На второй – явно у нас зависимость нелинейная, например квадратичная. Значит, линия, проведенная по точкам, неправильная. Мы получили недообученную модель (underfitting), ошиблись порядком функции. На третьей картинке ситуация наоборот, модель выбрана слишком сложной для линейной зависимости, которая наблюдается по точкам. Выбросы данных исказили ее. Здесь налицо переобучение, нужно было выбрать модель попроще – линейную.
Я нарисовал относительно искусственную ситуацию – одна независимая переменная на горизонтальной оси и одна зависимая переменная на вертикальной оси. В таких простых условиях мы можем прямо на графике увидеть проблему. Но что будет, если у нас много независимых переменных, например десяток? Тут на помощь приходит подход для тестирования модели – валидация.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Роман с Data Science. Как монетизировать большие данные [litres]»
Представляем Вашему вниманию похожие книги на «Роман с Data Science. Как монетизировать большие данные [litres]» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Роман с Data Science. Как монетизировать большие данные [litres]» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.