Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]
Здесь есть возможность читать онлайн «Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Санкт-Петербург, Год выпуска: 2021, ISBN: 2021, Издательство: Издательство Питер, Жанр: Базы данных, popular_business, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
![Роман Зыков Роман с Data Science. Как монетизировать большие данные [litres] обложка книги](/books/438007/roman-zykov-roman-s-data-science-kak-monetizirova.webp)
- Название:Роман с Data Science. Как монетизировать большие данные [litres]
- Автор:
- Издательство:Издательство Питер
- Жанр:
- Год:2021
- Город:Санкт-Петербург
- ISBN:978-5-4461-1879-3
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Роман с Data Science. Как монетизировать большие данные [litres]: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Роман с Data Science. Как монетизировать большие данные [litres]»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Эта книга предназначена для думающих читателей, которые хотят попробовать свои силы в области анализа данных и создавать сервисы на их основе. Она будет вам полезна, если вы менеджер, который хочет ставить задачи аналитике и управлять ею. Если вы инвестор, с ней вам будет легче понять потенциал стартапа. Те, кто «пилит» свой стартап, найдут здесь рекомендации, как выбрать подходящие технологии и набрать команду. А начинающим специалистам книга поможет расширить кругозор и начать применять практики, о которых они раньше не задумывались, и это выделит их среди профессионалов такой непростой и изменчивой области. Книга не содержит примеров программного кода, в ней почти нет математики.
В формате PDF A4 сохранен издательский макет.
Роман с Data Science. Как монетизировать большие данные [litres] — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Роман с Data Science. Как монетизировать большие данные [litres]», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Бороться с мультиколлинеарностью можно несколькими способами: удаление зависимых фич, сжатие пространства с помощью анализа главных компонент (Principal Component Analysis), гребневая регрессия (Ridge Regression). Для первого способа – используется пошаговое включение или пошаговое исключение фич. При пошаговом включении первым шагом выбирается фича, которая имеет наименьшую ошибку, если построить регрессию только на ней. Для этого нужно перебрать все фичи и выбрать только одну, вторым шагом выбрать следующую фичу и так далее. Остановиться нужно тогда, когда ошибка модели на тестовом датасете не уменьшается на приемлемую для вас величину. Аналогично работает пошаговое исключение.
Метод главных компонент (PCA) – это линейный метод сжатия пространства, один из методов машинного обучения без учителя (unsupervised learning), работает только для линейных зависимостей. Сам метод звучит сложно: уменьшение числа фич с минимальной потерей информации путем проекции в ортогональное пространство меньшей размерности. Понять его нам поможет геометрическая интерпретация. Изобразим зависимость числа заказов от потраченных средств в виде диаграммы рассеяния. На графике видно вытянутое облако (рис. 8.9). Теперь изобразим на нем другую систему координат с осями X1 и X2:
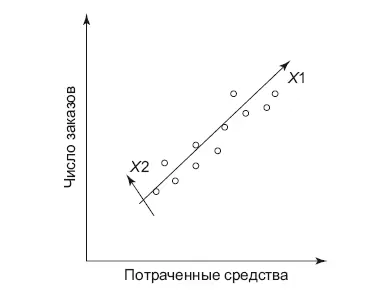
Рис. 8.9.Метод главных компонент (PCA)
X1 проведем вдоль облака, X2 перпендикулярно ему. Теперь значение каждой точки мы можем взять в этой новой системе координат, и скажу больше – мы можем оставить только значение по оси X1 и получить только одну фичу X1 вместо двух коррелирующих между собой. X2 мы можем выбросить, так как разброс (вариативность) значений по этой оси намного меньше, чем по X2. Таким образом, мы нашли совершенно новую фичу X1, которая несет информацию о прошлых покупках пользователя и хорошо заменяет две старые фичи. Примерно так и работает PCA, этому методу передается нужное число фич (размерность пространства), метод производит все необходимые операции и сообщает, сколько информации мы потеряли из-за этого преобразования (доля объясненной дисперсии). Подобрать размерность пространства можно по этому показателю.
Четвертый способ борьбы с переобучением – остановить обучение раньше (рис. 8.10).
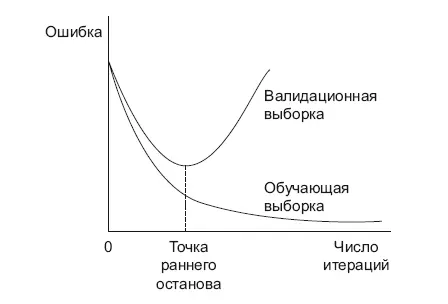
Рис. 8.10.Досрочная остановка обучения
Для этого на каждом шаге итерации нужно считать ошибки на обучающем и тестовом датасете. Остановку сделать в момент «перелома» тестовой ошибки в сторону увеличения.
Пятый вариант – регуляризация. Регуляризация представляет собой сумму коэффициентов модели, умноженную на коэффициент регуляризации. Регуляризация добавляется к функции ошибки, которую оптимизирует ML-модель. Есть несколько типов регуляризаций: L1 – сумма модулей коэффициентов, L2 – сумма квадратов коэффициентов, Elastic Net – сумма L1 и L2 регуляризаций с отдельными коэффициентами. Задачей регуляризации является пессимизация коэффициентов с большими значениями, чтобы какая-то одна фича не перетянула одеяло на себя. Коэффициенты регуляризации являются так называемыми гиперпараметрами модели, их тоже нужно подбирать таким образом, чтобы получить меньшую ошибку. На практике регуляризация L2 используется чаще.
И наконец, шестой способ – использовать ансамбли алгоритмов.
Ансамбли
Теорема No Free Lunch (или по-нашему – халявы не бывает) гласит, что не существует единственного алгоритма, который будет самым точным для любых задач. Аналитики могут заниматься ручным трудом, подбирая все новые и новые модели, которые наилучшим образом решают проблему. Но что если попытаться объединить разные модели в одну большую, каким-либо образом аккумулируя результат? Тогда мы получим новый алгоритм – ансамбль алгоритмов, точность которого может быть очень высокой, даже если использовать внутри «слабые» алгоритмы, чья точность чуть выше обычного подбрасывания монетки. Развитие вычислительных мощностей (больше памяти, мощные процессоры) с легкостью позволило сделать это.
Способов объединения простых алгоритмов в ансамбли придумано много, но мы рассмотрим два наиболее известных типа – бэггинг (bagging) и бустинг (boosting). Бэггинг (Bagging = Bootstrap aggregating) был предложен Лео Брейманом в 1994 году. Суть метода заключается в создании множества тренировочных датасетов, слегка отличающихся от исходного. Делать это можно двумя способами – случайно выбирая (сэмплируя) записи из датасета и случайно выбирая подмножество фич из датасета. Обычно эти два способа совмещают: случайно выбираются и записи, и фичи. Само сэмплирование данных осуществляется с замещением – мы не удаляем строки из исходного датасета, а значит, какие-то данные попадут в новый датасет несколько раз, а какие-то вообще не попадут.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Роман с Data Science. Как монетизировать большие данные [litres]»
Представляем Вашему вниманию похожие книги на «Роман с Data Science. Как монетизировать большие данные [litres]» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Роман с Data Science. Как монетизировать большие данные [litres]» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.