Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]
Здесь есть возможность читать онлайн «Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Санкт-Петербург, Год выпуска: 2021, ISBN: 2021, Издательство: Издательство Питер, Жанр: Базы данных, popular_business, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
![Роман Зыков Роман с Data Science. Как монетизировать большие данные [litres] обложка книги](/books/438007/roman-zykov-roman-s-data-science-kak-monetizirova.webp)
- Название:Роман с Data Science. Как монетизировать большие данные [litres]
- Автор:
- Издательство:Издательство Питер
- Жанр:
- Год:2021
- Город:Санкт-Петербург
- ISBN:978-5-4461-1879-3
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Роман с Data Science. Как монетизировать большие данные [litres]: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Роман с Data Science. Как монетизировать большие данные [litres]»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Эта книга предназначена для думающих читателей, которые хотят попробовать свои силы в области анализа данных и создавать сервисы на их основе. Она будет вам полезна, если вы менеджер, который хочет ставить задачи аналитике и управлять ею. Если вы инвестор, с ней вам будет легче понять потенциал стартапа. Те, кто «пилит» свой стартап, найдут здесь рекомендации, как выбрать подходящие технологии и набрать команду. А начинающим специалистам книга поможет расширить кругозор и начать применять практики, о которых они раньше не задумывались, и это выделит их среди профессионалов такой непростой и изменчивой области. Книга не содержит примеров программного кода, в ней почти нет математики.
В формате PDF A4 сохранен издательский макет.
Роман с Data Science. Как монетизировать большие данные [litres] — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Роман с Data Science. Как монетизировать большие данные [litres]», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Польза ML заключается в автоматизации принятия решений, за счет этого данные обрабатываются гораздо быстрее. Мы, люди, обладаем настоящим универсальным интеллектом, но из-за этой универсальности количество задач, которые мы можем решить за единицу времени, очень ограниченно. Чего не скажешь о ML, типовой алгоритм которого заточен на очень узкую задачу, но его можно масштабировать неограниченно. Хотите один миллион прогнозов в секунду – пожалуйста, предоставьте только необходимые ресурсы.
Моя книга – не учебник по ML. В этой главе я проговорю только основы, которые нам понадобятся в дальнейшем. Они покрывают 80 % того, что понадобится на практике работы со структурированными данными – правило Парето работает и здесь. Сами алгоритмы я выбрал из своей практики применения: линейная регрессия, логистическая регрессия, деревья решений и ансамбли (random forest, xgboost, catboost). Это самые популярные алгоритмы решения задач для структурированных данных. Что подтверждается исследованием, которое провел Kaggle в 2019 году [53]. На 18-й странице этого исследования есть график популярности методов машинного обучения (рис. 8.1). И в исследовании написан вывод: «Участники опроса – фанаты простоты. Самые популярные методы – линейная и логистическая регрессии, за которыми идут деревья решений. Они не настолько мощные, как более сложные методы, но достаточно эффективны и их легко интерпретировать».
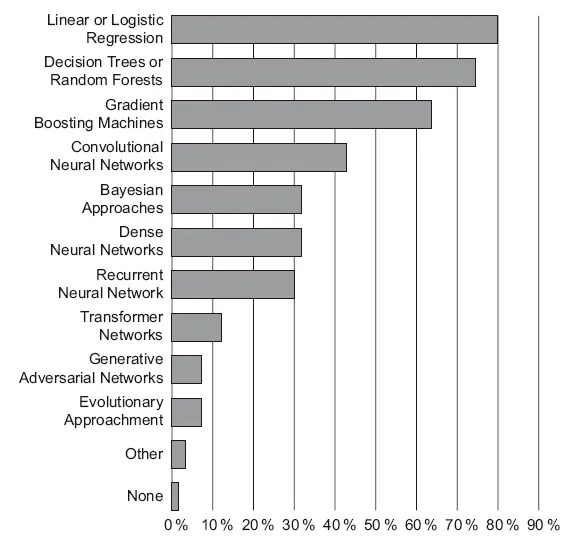
Рис. 8.1.Простые линейные методы – самые популярные
С нейронными сетями я впервые познакомился в 2002 году, когда стал работать в компании StatSoft. Тогда они не произвели на меня впечатления. Да, алгоритм красивый и интересный, но те задачи, которые ими решались, можно было решить более простыми методами. Золотой век нейронных сетей начался примерно 10 лет назад, когда стали применять сверточные нейронные сети (convolutional neural networks). Они стали идеальным инструментом для работы с изображениями, звуком и прочей неструктурированной информацией. Есть попытки их использовать и в рекомендательных сервисах, но пока нет существенного прогресса [52]. Мы в Retail Rocket тоже пытались их использовать. В рекомендациях одежды существенной выгоды [25] не получили. А вот для удаления «плохих» рекомендаций они пригодились и используются прямо сейчас. Сама область довольно молодая, вычислительные чипы GPU, которые предназначены для ускорения вычислений на нейронных сетях глубокого обучения, становятся все мощнее и дешевле. Я ожидаю более широкого применения этих методов в течение ближайших 10 лет. Теоретически они будут способны заменить алгоритмы на универсальные даже для структурированных данных, что сильно упростит решение ML-задач. Сами нейронные сети – тема для отдельной книги.
Типы ML-задач
Классическое ML делится на три типа:
• обучение с учителем (supervised learning);
• обучение без учителя (unsupervised learning);
• обучение с подкреплением (reinforcement learning).
Обучение с учителем подразумевает под собой, что для каждого набора входных данных (независимые переменные или фичи) у вас есть величина (зависимая переменная), которую модель должна предсказать. Примеры таких задач представлены в табл. 8.1 [50].
Таблица 8.1. Типы задач в ML
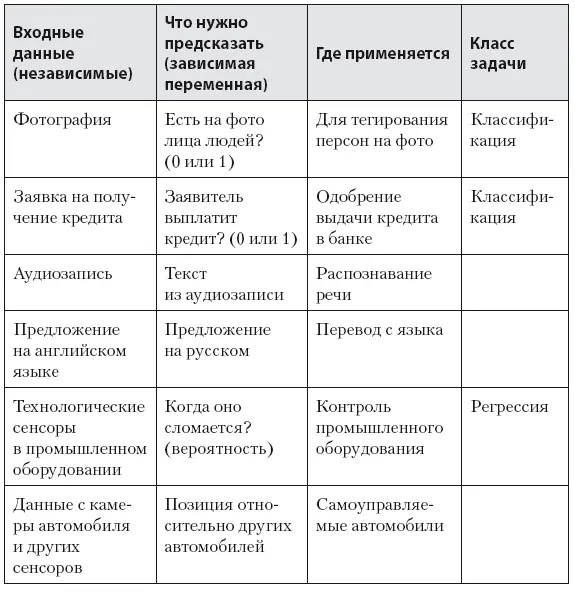
В таком типе задач есть два основных класса задач: задача регрессии, когда нужно прогнозировать показатель с непрерывной шкалой (например, деньги, вероятность); а также задача классификации, когда нужно понять, к какому классу принадлежит объект (есть ли на фотографии люди, человек болен или нет, кто изображен на фотографии). Есть еще ряд задач, связанных с переводом текста, распознаванием речи, геопозиционированием, которые получили большое распространение благодаря глубоким нейронным сетям.
Понятие «регрессия» возникло, когда сэр Френсис Гамильтон познакомился с книгой Дарвина «Происхождение видов». Он решил изучить, как рост детей зависит от роста родителей. В процессе исследования он выяснил, что дети очень высоких и очень низких родителей в среднем имеют менее высокий и, соответственно, менее низкий рост. Это движение роста назад в направлении к среднему Ф. Гамильтон назвал регрессией (to regress – двигаться в обратном направлении) [51]. В 1885 году он издал работу «Регрессия в направлении к общему среднему размеру при наследовании роста», через некоторое время это понятие стало применяться ко всем задачам с односторонней стохастической зависимостью.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Роман с Data Science. Как монетизировать большие данные [litres]»
Представляем Вашему вниманию похожие книги на «Роман с Data Science. Как монетизировать большие данные [litres]» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Роман с Data Science. Как монетизировать большие данные [litres]» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.