Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]
Здесь есть возможность читать онлайн «Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Санкт-Петербург, Год выпуска: 2021, ISBN: 2021, Издательство: Издательство Питер, Жанр: Базы данных, popular_business, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
![Роман Зыков Роман с Data Science. Как монетизировать большие данные [litres] обложка книги](/books/438007/roman-zykov-roman-s-data-science-kak-monetizirova.webp)
- Название:Роман с Data Science. Как монетизировать большие данные [litres]
- Автор:
- Издательство:Издательство Питер
- Жанр:
- Год:2021
- Город:Санкт-Петербург
- ISBN:978-5-4461-1879-3
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Роман с Data Science. Как монетизировать большие данные [litres]: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Роман с Data Science. Как монетизировать большие данные [litres]»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Эта книга предназначена для думающих читателей, которые хотят попробовать свои силы в области анализа данных и создавать сервисы на их основе. Она будет вам полезна, если вы менеджер, который хочет ставить задачи аналитике и управлять ею. Если вы инвестор, с ней вам будет легче понять потенциал стартапа. Те, кто «пилит» свой стартап, найдут здесь рекомендации, как выбрать подходящие технологии и набрать команду. А начинающим специалистам книга поможет расширить кругозор и начать применять практики, о которых они раньше не задумывались, и это выделит их среди профессионалов такой непростой и изменчивой области. Книга не содержит примеров программного кода, в ней почти нет математики.
В формате PDF A4 сохранен издательский макет.
Роман с Data Science. Как монетизировать большие данные [litres] — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Роман с Data Science. Как монетизировать большие данные [litres]», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
История их появления очень интересна как минимум тем, что к этому приложил руку наш бывший соотечественник – Михаил (Моша) Пасуманский. Михаил переехал в Израиль из Санкт-Петербурга в 1990 году. Там он написал аналитическое приложение «Панорама». В 1995 году они выпустили первую версию. В 1996 году компанию купила Microsoft, которой нужно было подобное решение для новой версии SQL Server. После интеграции системы в софт Microsoft появился язык программирования для работы с OLAP-кубами, который называется MDX (Multidimensional Expressions), чьим автором является Михаил Пасуманский. Этот язык является стандартом для работы с OLAP-кубами, и его поддерживают очень многие вендоры. Сервис OLAP-кубов теперь называется Analysis Services.
Мы уже рассмотрели, как работают сводные таблицы. Теперь посмотрим, как проблема производительности решается в OLAP-кубах, которые эти сводные таблицы умеют очень быстро рассчитывать. Я много работал с технологиями Microsoft по OLAP-кубам, поэтому буду опираться на свой опыт. Центральным звеном любого OLAP-куба является таблица фактов, которую мы рассмотрели на примерах построения сводных таблиц чуть ранее. Однако есть небольшое, но важное отличие: таблица фактов, как правило, не соединяется со справочниками, она загружается в кубы отдельно от них.
Для этого в хранилище данные готовятся по схеме «звезда» (рис. 7.4): таблица фактов соединяется по полям, содержащим ID (ключи), со справочниками, как показано на рисунке. Существует правило – все измерения лучше держать в отдельных справочниках. Это сделано для того, чтобы можно было их обновлять независимо от таблицы фактов. После подготовки нужных данных в программе-дизайнере нужно отметить, какие таблицы являются таблицами измерений, а какие – таблицами фактов. Там же в настройках указывается, какие показатели необходимо рассчитать. Первичная обработка куба заключается в чтении всех данных из хранилища и помещении их в специальные структуры, которые очень быстро работают с расчетом сводных таблиц. Сначала читаются и обрабатываются все измерения, и только после этого таблица фактов. Но самое интересное происходит потом, когда нужно добавить в куб новые данные.
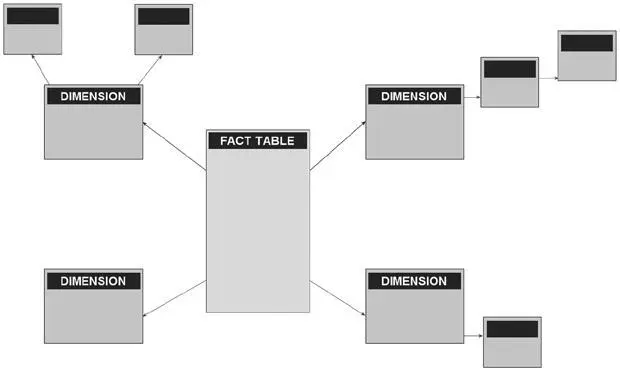
Рис. 7.4.Соединение таблиц по схеме «звезда»
Но что делать, если появились новые данные? Нужно обновить данные в нашей «звезде» – хранилище – и обновить куб на их основе. Обновление данных для уже обработанного рабочего куба заключается в полном прочтении всех измерений (справочников): если появляются новые элементы или они переименовываются – все обновится. Поэтому справочники измерений для OLAP-кубов нужно сохранять и обновлять в первозданном виде – данные оттуда удалять нельзя. Обновление таблицы фактов интереснее – можно выбрать полное обновление и пересчет куба, а можно стереть старые данные из таблицы фактов и залить туда новые, которых нет в кубе, и только после этого обновить куб. Схема с инкрементальным обновлением выгоднее с точки зрения времени обработки куба. В Ozon.ru полный процессинг куба мог занимать у меня четыре дня, а инкрементальное обновление всего двадцать минут.
Существует несколько популярных вариантов хранения и обработки данных в OLAP-кубах:
• MOLAP – та схема хранения, которую я описал выше. Данные хранятся в специальных структурах, которые очень быстро вычисляют сводные таблицы.
• ROLAP – данные никуда не помещаются, они находятся в хранилище. OLAP-куб транслирует запросы из сводных таблиц в запросы к хранилищу и отдает результат.
• HOLAP – данные частично находятся в MOLAP-, частично в ROLAP-схемах. Например, это может быть полезно для уменьшения времени отставания куба от реального времени. Куб обновляется раз в день по схеме MOLAP, а новые данные, которых там пока нет, существуют в схеме ROLAP.
Я всегда предпочитал пользоваться MOLAP-схемой, как наиболее быстрой. Хотя в связи с развитием быстрых колоночных баз данных ROLAP могут оказаться проще. Ведь ROLAP-схема не требует тщательного дизайна куба, как MOLAP, что сильно упрощает техническую поддержку OLAP-куба.
Самый идеальный клиент для OLAP-кубов – это электронные таблицы Microsoft Excel, где работа с кубами от Microsoft реализована очень удобно. Любые тонкие клиенты не обеспечивают того удобства и гибкости, которые предлагает Excel: возможность использования MDX, гибких формул, построения отчетов из отчетов. К сожалению, эта функциональность поддерживается только в операционной системе Windows. Версия Excel для OS X (Apple) не поддерживает ее. Вы даже не представляете себе, сколько руководителей и специалистов шлют проклятья разработчикам MS за это. Ведь им приходится держать отдельные ноутбуки с Windows или удаленные машины в облаке только для того, чтобы работать с кубами Microsoft. Я считаю, что это самая большая ошибка Microsoft в нашей области.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Роман с Data Science. Как монетизировать большие данные [litres]»
Представляем Вашему вниманию похожие книги на «Роман с Data Science. Как монетизировать большие данные [litres]» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Роман с Data Science. Как монетизировать большие данные [litres]» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.