Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Вместо того чтобы сразу сделать шаг направо и использовать среду, получив воду и гарантированные +1, агент может однажды шагнуть налево и отправиться в более опасные области в поисках лучшей стратегии. Однако чрезмерное исследование приведет к отсутствию награды. Недостаточные же приведут в ловушку локального максимума. Такой баланс исследования и использования необходим для обучения успешной стратегии.
ϵ-жадность
Стратегия уравновешивания дилеммы исследования и использования называется ϵ- жадностью . Это простая стратегия, связанная с выбором на каждом шаге между наиболее рекомендуемым действием и каким-нибудь случайным.
Вероятность того, что агент предпочтет случайное действие, определяется значением ϵ.
Реализовать стратегию ϵ-жадности можно так:
def epsilon_greedy_action(action_distribution, epsilon=1e-1):
if random.random() < epsilon:
return np.argmax(np.random.random(
action_distribution.shape))
else:
return np.argmax(action_distribution)
Нормализованный алгоритм ϵ-жадности
При обучении модели с подкреплением вначале мы часто хотим выбрать исследование, поскольку наша модель мало знает мир. Потом, когда она хорошо познакомится со средой и научится хорошей стратегии, нам будет желательно, чтобы агент больше доверял себе, — это приведет к дальнейшей оптимизации стратегии. И мы отказываемся от идеи фиксированного ϵ и периодически нормализуем его со временем, начиная с небольшого значения и после каждого эпизода обучения увеличивая его на какой-то коэффициент. Типичные условия нормализованных сценариев ϵ-жадности включают нормализацию с 0,99 до 0,1 за 10 тысяч подходов. Реализовать нормализацию можно так:
def epsilon_greedy_action_annealed(action_distribution,
percentage,
epsilon_start=1.0,
epsilon_end=1e-2):
annealed_epsilon = epsilon_start*(1.0-percentage) + epsilon_end*percentage
if random.random() < annealed_epsilon:
return np.argmax(np.random.random(
action_distribution.shape))
else:
return np.argmax(action_distribution)
Изучение стратегии и ценности
* * *
Мы определили архитектуру обучения с подкреплением, поговорили о дисконтировании будущей выгоды и рассмотрели компромиссы использования и исследования. Но пока мы не упоминали о том, как собираемся научить агента максимизировать выгоду.
Подходы к вопросу делятся на две большие категории: изучение стратегии и изучение ценности. В первом случае мы непосредственно обучаем стратегии, которая доводит выгоду до максимума. Во втором мы изучаем ценность каждой пары «состояние + действие». Для осваивающего велосипед изучение стратегии соответствует мыслям о том, как нажатие на правую педаль при падении влево восстановит равновесие. Если же действовать методом изучения ценности, нужно определять ценности для различных положений машины и действий, которые вы можете предпринять в этих условиях. Мы поговорим об обоих подходах, а начнем с изучения стратегии.
Изучение стратегии при помощи градиента по стратегиям
В обычном освоении навыков с учителем можно использовать стохастический градиентный спуск для обновления параметров и минимизации потерь, вычисленных на основе выходных данных сети и правильной метки. Оптимизируем выражение:
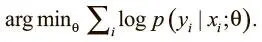
В обучении с подкреплением правильной метки нет — только сигналы вознаграждения. Но и здесь можно применить стохастический градиентный спуск для оптимизации весов, использовав градиенты по стратегиям [105]. Мы можем воспользоваться действиями, которые совершает агент, и выгодами, связанными с ними, чтобы веса модели принимали действия, которые приводят к высоким наградам, и отвергали ведущие к негативному подкреплению. Оптимизируем выражение:
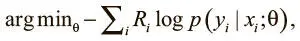
где y i — действие агента на шаге t , а R i — дисконтированная будущая выгода. Мы умножаем потери на значение выгоды, так что, если модель выбирает действие, ведущее к отрицательному результату, то потери возрастают. Если модель продолжает упорствовать, она получит еще больший штраф, ведь мы учитываем вероятность того, что она выберет это действие. Определив функцию потерь, мы можем применить стохастический градиентный спуск для их минимизации и обучения грамотной стратегии.
Тележка с шестом и градиенты по стратегиям
* * *
Сейчас мы реализуем агент градиента по стратегиям для решения проблемы тележки с шестом — классической задачи в обучении с подкреплением. Мы воспользуемся средой из OpenAi Gym, созданной как раз для этого задания.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.