Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
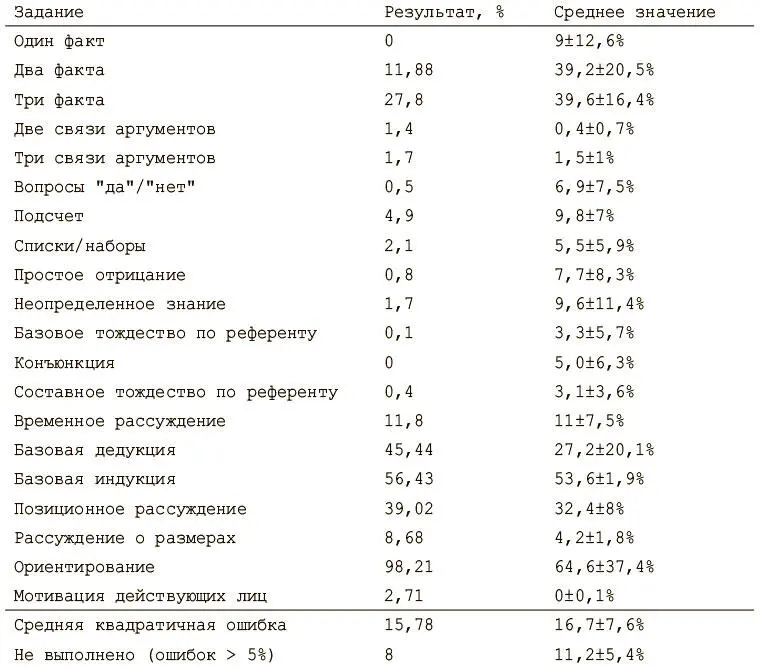
После того как модель обучена, тестируем ее работоспособность на оставшихся тестовых вопросах. Нашей метрикой будет процент вопросов, на которые модель не смогла ответить в рамках каждого задания. Ответ — слово с наибольшим значением функции мягкого максимума на выходе, то есть наиболее вероятное слово. Считается, что ответ верный, если все слова в нем правильные. Если модель не смогла ответить более чем на 5% вопросов в задании, считается, что она не справилась. Процедуру тестирования можно найти в файле test_babi.py .
После обучения модели на примерно 500 тысяч итераций (это может занять очень много времени!) оказывается, что с большинством заданий она справилась очень хорошо. Но она плохо выполняет более сложные задачи, такими как ориентирование , где надо отвечать на вопросы о том, как попасть из одного места в другое. В нижеследующем отчете сравниваются результаты нашей модели со средними значениями из первой работы по DNC.
Резюме
В этой главе мы рассмотрели проблемы переднего края науки о глубоком обучении — работу с NTM и DNC, завершив реализацией модели, которая может решать задачу понимания чтения.
В последней главе мы начнем изучать иную сферу: обучение с подкреплением. Мы познакомимся с новым классом задач и подготовим алгоритмические основы решения при помощи уже созданных нами инструментов глубокого обучения.
Глава 9. Глубокое обучение с подкреплением
* * *
[102]
В этой главе мы рассмотрим обучение с подкреплением — раздел машинного обучения, требующего взаимодействия и обратной связи. Это необходимо для создания агентов, которые будут не просто воспринимать и интерпретировать мир, но и взаимодействовать с ним. Мы расскажем, как внедрить глубокие нейронные сети в структуру обучения с подкреплением, и обсудим последние достижения и улучшения в этой области.
Глубокое обучение с подкреплением и игры Atari
Применение глубоких нейронных сетей к обучению с подкреплением стало важным прорывом в 2014 году, когда лондонский стартап DeepMind поразил специалистов по машинному обучению, представив глубокую нейронную сеть, которая справлялась с играми компании Atari лучше, чем люди. Эта сеть, получившая название Deep Q-Network (DQN), стала первым масштабным успешным применением обучения с подкреплением с глубокими нейронными сетями. Она оказалась особенно примечательной, потому что одна и та же архитектура без изменений смогла освоить 49 разных игр, различающихся правилами, целями и стратегиями. Создатели DeepMind свели воедино многие традиционные идеи обучения с подкреплением, разработав и несколько новаторских методов, которые оказались ключевыми для успеха. В этой главе мы рассмотрим реализацию DQN, как она представлена в публикации в журнале Nature под названием «Управление на уровне человека с помощью глубокого обучения с подкреплением» [103]. Но сначала подробнее рассмотрим суть метода (рис. 9.1).
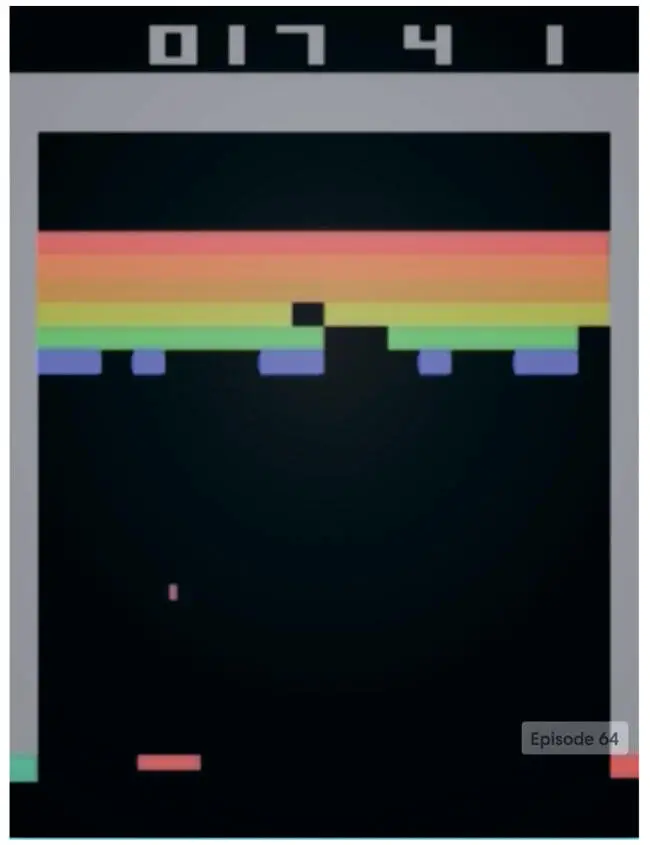
Рис. 9.1. Агент глубокого обучения с подкреплением играет в Breakout. Изображение из агента DQN OpenAI Gym [104], который будет реализован в этой главе
Что такое обучение с подкреплением?
По сути, это обучение путем взаимодействия со средой. Процесс включает агента, среду и сигнал вознаграждения. Агент решает совершить действие в среде и за это получает соответствующее вознаграждение. Способ, которым он выбирает, что совершить, называется стратегией . Агент хочет увеличить вознаграждение, так что он должен научиться оптимальной стратегии взаимодействия со средой (рис. 9.2).
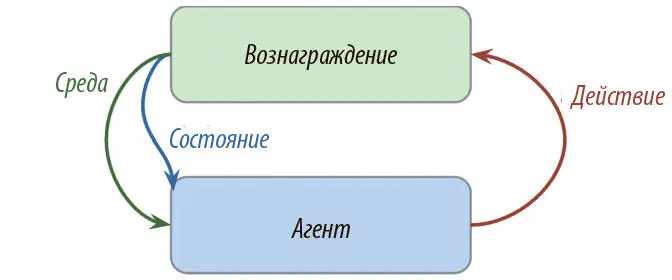
Рис. 9.2. Схема обучения с подкреплением
Обучение с подкреплением отличается от остальных типов, о которых мы говорили ранее. При традиционном подходе с учителем у нас есть данные и метки, а задача — предсказывать последние на основании данных. В освоении навыков без учителя у нас есть только данные, а задача — поиск структур в их основе. В обучении же с подкреплением нет ни данных, ни меток. Сигнал поступает от вознаграждений, получаемых от среды.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.