Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Мы хотим, чтобы наши агенты были оптимизированы в отношении будущей выгоды . Для этого им стоит учитывать отдаленные последствия своих действий. Например, в пинг-понге агент получает вознаграждение, когда соперник не может отбить его удар. Но действия, ведущие к этому (входные данные, которые обусловили положение ракетки, позволяющее нанести решающий удар), происходят за много шагов до получения вознаграждения, и его стоит считать отложенным.
Мы можем включить отложенные вознаграждения в общий сигнал, создав выгоду для каждого шага, которая будет учитывать как немедленные, так и будущие вознаграждения. Наивный подход к вычислению будущей выгоды на данном шаге — простая сумма вроде следующей:
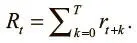
Мы можем вычислить все выгоды, R , где R = { R 0, R 1,… R i ,… R n }, с помощью следующего кода:
def calculate_naive_returns(rewards):
""" Calculates a list of naive returns given a
list of rewards.""" (Вычисляет список наивных выгод на основании списка вознаграждений)
total_returns = np.zeros(len(rewards))
total_return = 0.0
for t in range(len(rewards), 0):
total_return = total_return + reward
total_returns[t] = total_return
return total_returns
Этот подход включает будущие выгоды, и агент может научиться оптимальной общей стратегии. Здесь будущие выгоды ценятся так же, как и немедленные. Но это-то и беспокоит. При бесконечном числе шагов это выражение может свестись к бесконечности, так что нужно установить для него предел. Более того, если на каждом этапе все выгоды расценивать одинаково, агент может оптимизировать действия для очень отдаленной выгоды, и получится стратегия, в которой не учитываются срочность или иной вариант зависимости вознаграждения от времени.
Поэтому следует оценивать будущие вознаграждения чуть ниже, чтобы наши агенты могли научиться получать их быстрее. Этого можно достичь с помощью дисконтирования будущих выгод .
Дисконтирование будущих выгод
Для реализации этого подхода мы умножаем вознаграждение текущего состояния на коэффициент дисконтирования γ в степени текущего шага. Тем самым мы штрафуем агентов, которые совершают много действий до получения положительного вознаграждения. Благодаря дисконтированию наш агент будет выбирать вознаграждения в недалеком будущем, что позволит развить хорошую стратегию. Это вознаграждение можно выразить так:
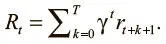
Коэффициент дисконтирования γ отражает уровень снижения, которого мы хотим достичь, и может принимать значение от 0 до 1. Высокий γ соответствует небольшому дисконтированию, низкий — значительному. Типичное значение гиперпараметра γ — между 0,99 и 0,97.
Реализовать дисконтирование выгоды можно так:
def discount_rewards(rewards, gamma=0.98):
discounted_returns = [0 for _ in rewards]
discounted_returns[-1] = rewards[-1]
for t in range(len(rewards)-2, -1, -1): # iterate backwards
discounted_returns[t] = rewards[t] +
discounted_returns[t+1]*gamma
return discounted_returns
Исследование и использование
* * *
Обучение с подкреплением — по сути, метод проб и ошибок. В таких условиях агент, опасающийся провала, будет не очень-то эффективен. Рассмотрим такой сценарий. Мышь помещают в лабиринт, показанный на рис. 9.5. Агент должен управлять ею для получения максимального вознаграждения. Если мышь находит воду, она получает +1; если контейнер с ядом (красный), то –10; за нахождение сыра дается +100. После вознаграждения эпизод заканчивается. Оптимальная стратегия должна помочь мыши успешно добраться до сыра и съесть его.
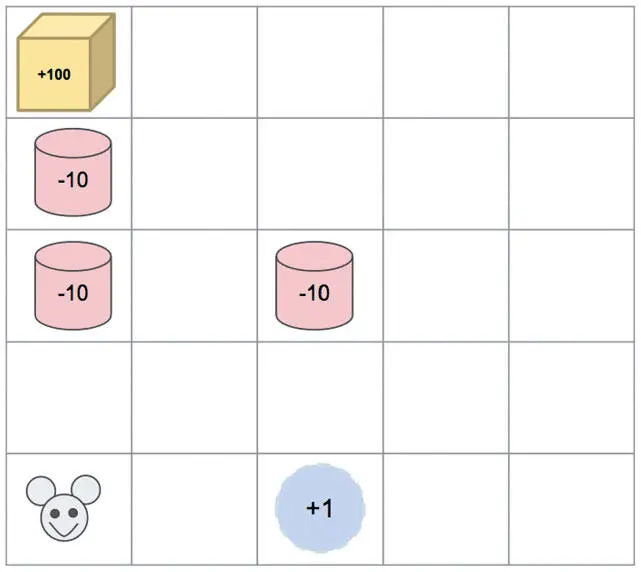
Рис. 9.5. Ситуация, в которой оказываются многие мыши
В первом эпизоде мышь идет влево, попадает в ловушку и получает –10. Во втором она избегает движения налево, поскольку результат оказался отрицательным, сразу выпивает воду, находящуюся справа, и получает +1.
После двух эпизодов может показаться, что мышь нашла хорошую стратегию. Животное продолжает и дальше следовать ей и получает скромную, но гарантированную награду +1. Поскольку агент следует жадной стратегии, всегда выбирая лучшее действие в модели, он оказывается в ловушке локального максимума .
Чтобы предотвратить такие ситуации, агенту полезно отклониться от рекомендации модели и выбрать неоптимальное действие, чтобы лучше исследовать среду.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.