Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
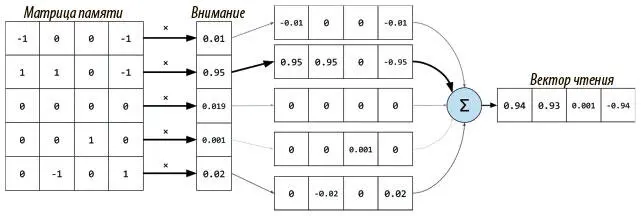
Рис. 8.2. Именно так размытое, основанное на внимании чтение может выдать вектор, содержащий примерно ту же информацию, что и соответствующая ячейка
Тот же метод используется и для головки записи: создается вектор весов w t , который служит для стирания определенной информации из памяти, указанной контроллером вектора стирания e t с W значений от 0 до 1; от этих значений и зависит, что стирать и что хранить. Затем взвешивание проводится для записи в матрицу стертой памяти новой информации, тоже определяемой контроллером в векторе записи v t , которая содержит W значений:
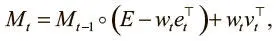
где E — матрица единиц, а ◦ — поэлементное умножение. Как и в случае с чтением, взвешивание w t подсказывает, куда направить операции стирания (первый член уравнения) и записи (второй член).
Механизмы адресации памяти в NTM
Теперь, когда мы понимаем, как NTM способна непрерывно обращаться к памяти при помощи взвешивания внимания, осталось понять, как эти веса порождаются и какие формы обращения к памяти представляют. Для этого стоит проанализировать, что NTM должны делать со своей памятью. Судя по модели, работу которой они имитируют (машина Тьюринга), они должны получать доступ к ячейке по ее значению и уметь двигаться вперед или назад из нее.
Первый способ поведения может быть реализован механизмом доступа, который мы назовем адресацией по содержанию . При такой форме обращения контроллер выдает значение, которое ищет и которое мы будем называть ключом k t , затем определяет степень его сходства с информацией, сохраненной в каждой ячейке, и сосредоточивает внимание на самой похожей из них. Такое взвешивание можно вычислить следующим образом:
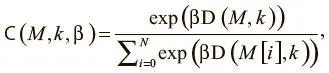
где D — некая мера сходства, например косинусная близость. Это уравнение — нормализованное распределение функции мягкого максимума по результатам сходства. Но здесь есть дополнительный параметр β, призванный при необходимости заставить затухать веса внимания. Мы называем его мощностью ключа. Его основной смысл в том, что для некоторых задач ключ, выданный контроллером, не очень близок к каким-то данным в памяти, что приведет к единообразным с виду весам внимания. На рис. 8.3 показано, как мощность ключа позволяет контроллеру учиться выходить из этой ситуации, чтобы больше сосредоточиваться на одной наиболее вероятной ячейке; затем контроллер учится тому, какое значение мощности выдавать для каждого порождаемого ключа.
Чтобы переходить по памяти вперед-назад, сначала надо понять, где мы сейчас. Эту информацию мы получаем взвешиванием доступа на предыдущем шаге w t−1 . Поэтому, чтобы сохранить информацию о текущем местоположении с новым взвешиванием на основании содержания 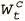 , которое мы только что провели, проводим интерполяцию между двумя взвешиваниями, используя скаляр g t , лежащий между 0 и 1:
, которое мы только что провели, проводим интерполяцию между двумя взвешиваниями, используя скаляр g t , лежащий между 0 и 1:
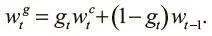
Назовем g tвентилем интерполяции . Он тоже порождается контроллером и контролирует информацию, которую мы хотим использовать на текущем временном шаге. Если значение вентиля близко к 1, мы делаем акцент на обращении по содержанию. Если же оно близко к 0, мы передаем информацию о текущем положении и игнорируем обращение по содержанию. Контроллер учится использовать этот вентиль и, например, может обращать его в 0 при необходимости итерации через последовательные ячейки, когда важнее всего информация о текущем местоположении. Тип информации, которую он пропускает, определяется вентильным взвешиванием 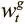 .
.
Рис. 8.3. Нечеткий ключ с похожими результатами, образующими почти единообразный и бесполезный вектор внимания. Увеличение его мощности позволяет сконцентрироваться на наиболее вероятной ячейке
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.