Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
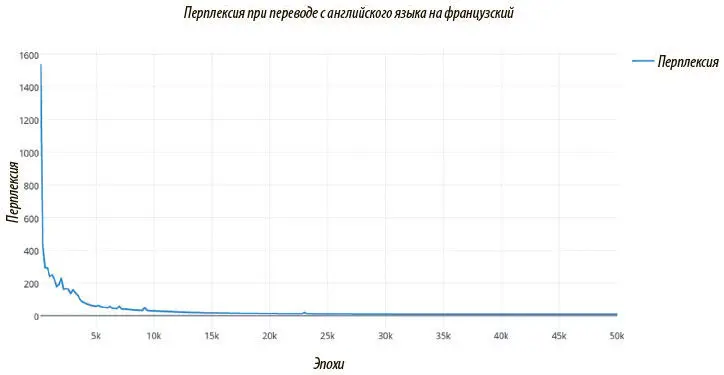
Рис. 7.31. График перплексии по обучающим данным во времени. После 50 тысяч эпох перплексия снижается примерно с 6 до 4 — вполне приличный результат для нейронной системы машинного перевода
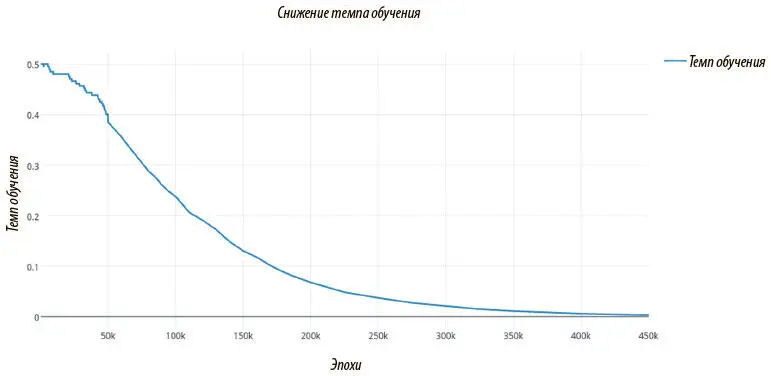
Рис. 7.32. График темпа обучения во времени; в отличие от перплексии, темп почти гладко снижается до 0. Это означает, что к моменту окончания обучения модель достигнет стабильного состояния
Чтобы ярче показать модель с вниманием, можно визуализировать внимание, которое вычисляет декодер LSTM при переводе предложения с английского языка на французский. Так, мы знаем, что, когда кодер LSTM обновляет состояние ячейки, чтобы сжать предложение до непрерывного векторного представления, он также вычисляет скрытые состояния на каждом шаге. Мы знаем, что декодер LSTM вычисляет выпуклую сумму по этим скрытым состояниям, и ее можно считать механизмом внимания: когда определенному скрытому состоянию соответствует больший вес, можно считать, что модель обращает больше внимания на токен, введенный на этом шаге.
Именно такую визуализацию мы и показываем на рис. 7.33. Английское предложение, которое необходимо перевести, приведено в верхней строке, а перевод на французский — в первом столбце.
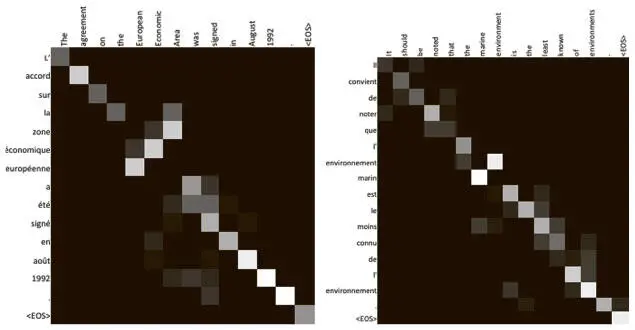
Рис. 7.33. Мы можем непосредственно визуализировать веса, когда декодер наблюдает скрытые состояния кодера. Чем светлее квадрат, тем больше внимания уделяется элементу
Чем светлее квадрат, тем больше внимания декодер уделил столбцу при декодировании этого элемента ряда. Таким образом, (i, j) — й элемент карты внимания показывает меру внимания, которая была уделена j -й метке в английском предложении при переводе i -й метки во французском.
Сразу можно увидеть, что механизм, судя по всему, работает неплохо. Внимание в основном уделяется именно нужным областям, хотя в предсказаниях модели и присутствует легкий шум. Возможно, добавление дополнительных слоев в сеть поможет добиться более четкого внимания.
Отметим особо, что словосочетание the European Economic Area («европейская экономическая зона») переводится на французский в обратном порядке — zone economique europeenne, и этот переворот отражается в весах внимания! Такие схемы могут быть еще интереснее, если переводить с английского на какой-то другой язык, который не так гладко разбивается слева направо. Разобрав и воплотив одну из важнейших архитектур, мы можем перейти к изучению поразительных новых достижений рекуррентных нейронных сетей и углубиться в более сложные аспекты обучения.
Резюме
В этой главе мы занимались анализом последовательностей. Мы разобрали, как заставить сети с прямым распространением сигнала обрабатывать последовательности, постарались понять работу рекуррентных нейронных сетей и остановились на многочисленных областях применения механизмов внимания: от переводов с языка на язык до расшифровки аудиофайлов.
Глава 8. Нейронные сети с дополнительной памятью
* * *
[96]
Мы уже убедились в том, насколько эффективной может быть РНС при решении таких сложных проблем, как машинный перевод. Но мы пока не раскрыли ее потенциал полностью. В главе 7 мы говорили о теоретических доказательствах того, что архитектура РНС обеспечит универсальное представление функций. Еще более точный результат можно получить при помощи полноты РНС по Тьюрингу . При грамотной архитектуре и адекватной установке параметров им будут под силу любые вычислительные задачи, решаемые компьютерными алгоритмами или машиной Тьюринга [97].
Нейронные машины Тьюринга
Однако добиться такой универсальности на практике крайне сложно. Причина в том, что мы имеем дело с огромным полем поиска вариантов архитектур и значений параметров РНС — настолько большим, что при помощи градиентного спуска очень трудно найти решение произвольной задачи. Ниже мы рассмотрим ряд подходов с переднего края исследований, позволяющих начать реализовывать этот потенциал.
Рассмотрим, например, очень простую проблему понимания чтения.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.