Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Невозможность освобождать и повторно использовать ячейки — второе ограничение архитектуры NTM. В результате новые данные записываются в новые ячейки, которые, скорее всего, как и в вышеприведенной задаче копирования, окажутся смежными. Это единственный способ хранения в NTM временной информации о данных: в порядке поступления. Если головка записи перепрыгнет в другое место памяти при записи последовательных данных, головка чтения не сможет восстановить временную связь между информацией, записанной до и после скачка. Таково третье ограничение NTM.
В октябре 2016 года Алекс Грейвз и коллеги по DeepMind опубликовали статью под названием «Гибридные вычисления с помощью нейронной сети с динамической внешней памятью» [100], где представили новую нейронную архитектуру с дополненной памятью — дифференцируемый нейронный компьютер (DNC). Это улучшение NTM, призванное устранить ограничения, которые мы упоминали выше. Как и NTM, DNC включает контроллер, взаимодействующий с внешней памятью. Память состоит из N слов размера W , составляющих матрицу N × W , которую мы назовем M . Контроллер принимает вектор входных данных размером X и R векторов размером W , прочитанных из памяти на предыдущем шаге, где R — число головок считывания. Затем он пропускает их через нейтральную сеть и выдает два вида данных.
• Вектор интерфейса , который содержит всю необходимую информацию для запроса в память (то есть записи и чтения).
• Предварительную версию выходного вектора размером Y.
Внешняя память принимает вектор интерфейса, проводит необходимую запись единственной головкой и читает R новых векторов из памяти. Она выдает только что прочитанные векторы в контроллер, где те суммируются с предварительным выходным вектором. Получается итоговый выходной вектор размером Y .
На рис. 8.6 наглядно показана работа DNC, которую мы только что описали. В отличие от NTM, DNC сохраняют и остальные структуры данных вместе с памятью, что позволяет отслеживать ее состояние. Как мы вскоре увидим, благодаря этим структурам и новым разумным механизмам внимания DNC способны успешно преодолеть ограничения NTM.
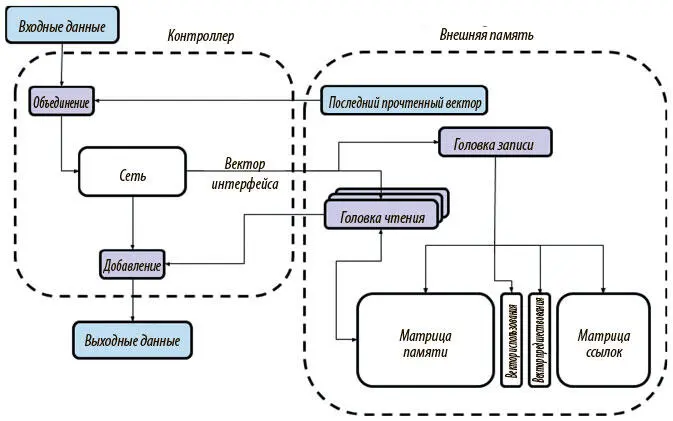
Рис. 8.6. Обзор архитектуры и схемы работы DNC. Внешняя память DNC отличается от NTM несколькими дополнительными структурами данных, а также механизмами внимания, используемыми для доступа
Чтобы архитектура была дифференцируемой, DNC получают доступ к памяти через вектора весов размера N , элементы которых определяют, насколько головки концентрируются в каждой ячейке. Имеется R взвешиваний для головок чтения 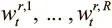 , где t обозначает временной шаг. И есть одно взвешивание записи
, где t обозначает временной шаг. И есть одно взвешивание записи 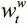 для единственной головки. Получив эти взвешивания, можно внести обновления в матрицу памяти:
для единственной головки. Получив эти взвешивания, можно внести обновления в матрицу памяти:
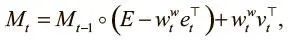
где e t, v t — векторы стирания и записи , которые нам уже знакомы по NTM и поступают от контроллера по вектору интерфейса как указания о том, что стереть из памяти и что в нее записать.
Получив обновленную матрицу M t , мы можем прочесть новые векторы считывания 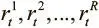 при помощи следующего уравнения для каждого взвешивания:
при помощи следующего уравнения для каждого взвешивания:
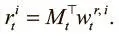
Пока создается впечатление, что в процедуре записи и считывания DNC и NTM все шаги совпадают. Разница станет заметна, когда мы перейдем к разбору механизмов внимания, используемых в DNC для получения этих взвешиваний. Обе машины используют механизм адресации по содержанию C(M, k, β), о котором шла речь выше, но механизмы DNC более совершенны; более эффективно и обращение к памяти.
Запись без помех в DNC
Первое ограничение NTM, о котором мы говорили, — невозможность обеспечить запись без помех. Интуитивный способ решения этой проблемы — разработать архитектуру, которая будет жестко концентрироваться на единственной свободной ячейке памяти, не дожидаясь, пока NTM научится это делать. Чтобы следить, какие ячейки свободны, а какие заняты, нам нужна новая структура данных, способная удерживать информацию такого рода. Назовем ее вектором использования . Вектор использования u t — вектор размера N , где каждый элемент имеет значение от 0 до 1. Это отражает степень использования соответствующей ячейки памяти: 0 — полностью свободная, 1 — полностью занятая. Вектор использования изначально содержит нули u 0 = 0и обновляется на каждом шаге при появлении информации. Благодаря ей становится ясно, что ячейка, на которую нужно обратить особое внимание, имеет наименьшее значение использования. Чтобы получить такое взвешивание, нужно отсортировать вектор использования и получить список индексов ячеек в восходящем порядке. Такой список называется свободным , обозначим его как ϕ t . Благодаря ему можно создать промежуточное взвешивание — взвешивание выделения a t , которое определяет, какая ячейка памяти отводится под новые данные. Вычисляется a t так:
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.