Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
def layer(input, weight_shape, bias_shape, phase_train):
weight_init = tf.random_normal_initializer(stddev=(1.0/weight_shape[0])**0.5)
bias_init = tf.constant_initializer(value=0)
W = tf.get_variable("W", weight_shape, initializer=weight_init)
b = tf.get_variable("b", bias_shape, initializer=bias_init)
logits = tf.matmul(input, W) + b
return tf.nn.sigmoid(layer_batch_norm(logits, weight_shape[1],
phase_train))
Теперь нужно выработать метрику (или целевую функцию), которая описывает, насколько хорошо функционирует наша модель. А именно: надо измерить, насколько близка реконструкция к исходному изображению. Это можно сделать, вычислив расстояние между исходными 784-мерными данными и воссозданными 784-мерными данными, полученными на выходе. Если входной вектор — I , а воссозданный — O , нужно минимизировать значение
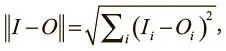
известное также как L2-норма разницы между двумя векторами. Мы усредняем функцию по всему мини-пакету и получаем итоговую целевую функцию. После этого мы обучаем сеть с помощью оптимизатора Adam, записывая скалярную статистику ошибок в каждом мини-пакете при помощи tf.scalar_summary. В TensorFlow операции расчета функции потерь и обучения можно кратко выразить так:
def loss(output, x):
with tf.variable_scope("training"):
l2 = tf.sqrt(tf.reduce_sum(tf.square(tf.sub(output, x)), 1))
train_loss = tf.reduce_mean(l2)
train_summary_op = tf.scalar_summary("train_cost", train_loss)
return train_loss, train_summary_op
def training(cost, global_step):
optimizer = tf.train.AdamOptimizer(learning_rate=0.001,
beta1=0.9, beta2=0.999, epsilon=1e-08,
use_locking=False, name='Adam')
train_op = optimizer.minimize(cost, global_step=global_step)
return train_op
Наконец, нам нужен способ оценки обобщающей способности модели. Как обычно, мы берем проверочный набор данных и вычисляем тот же показатель L2-нормы. Вдобавок мы сохраняем статистические данные по картинкам для сравнения входных изображений с их реконструкциями:
def image_summary(summary_label, tensor):
tensor_reshaped = tf.reshape(tensor, [-1, 28, 28, 1])
return tf.image_summary(summary_label, tensor_reshaped)
def evaluate(output, x):
with tf.variable_scope("validation"):
in_im_op = image_summary("input_image", x)
out_im_op = image_summary("output_image", output)
l2 = tf.sqrt(tf.reduce_sum(tf.square(tf.sub(output, x, name="val_diff")), 1))
val_loss = tf.reduce_mean(l2)
val_summary_op = tf.scalar_summary("val_cost", val_loss)
return val_loss, in_im_op, out_im_op, val_summary_op
Осталось построить из этих компонентов модель и начать ее обучать. По большей части код здесь знаком, но следует обратить внимание на пару дополнений. Во-первых, мы видоизменили обычный код, включив в него параметр командной строки для определения числа нейронов в слое плотного представления. Например, выполнение команды $ python autoencoder_mnist.py 2 запустит модель с двумя нейронами в этом слое. Также мы изменяем конфигурацию сохранения модели, чтобы получить больше снимков ее мгновенного состояния. Затем мы загрузим самую эффективную модель, чтобы сравнить ее производительность с методом главных компонент, так что нам нужно больше мгновенных снимков состояния модели.
Воспользуемся summary writer, чтобы записывать данные по изображениям, полученные в конце каждой эпохи:
if __name__ == ‘__main__':
parser = argparse.ArgumentParser(description='Test various
optimization strategies')
parser.add_argument(‘n_code', nargs=1, type=str)
args = parser.parse_args()
n_code = args.n_code[0]
mnist = input_data.read_data_sets("data/", one_hot=True)
with tf.Graph(). as_default():
with tf.variable_scope("autoencoder_model"):
x = tf.placeholder("float", [None, 784]) # mnist
data image of shape 28*28=784
phase_train = tf.placeholder(tf.bool)
code = encoder(x, int(n_code), phase_train)
output = decoder(code, int(n_code), phase_train)
cost, train_summary_op = loss(output, x)
global_step = tf.Variable(0, name='global_step', trainable=False)
train_op = training(cost, global_step)
eval_op, in_im_op, out_im_op, val_summary_op = evaluate(output, x)
summary_op = tf.merge_all_summaries()
saver = tf.train.Saver(max_to_keep=200)
sess = tf.Session()
train_writer = tf.train.SummaryWriter("mnist_autoencoder_hidden=" + n_code + "_logs/",graph=sess.graph)
val_writer = tf.train.SummaryWriter("mnist_autoencoder_hidden=" + n_code + "_logs/", graph=sess.graph)
init_op = tf.initialize_all_variables()
sess.run(init_op)
# Training cycle
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(mnist.train.num_examples/batch_size)
# Loop over all batches
for i in range(total_batch):
mbatch_x, mbatch_y =
mnist.train.next_batch(batch_size)
# Fit training using batch data
_, new_cost, train_summary = sess.run([
train_op, cost,
train_summary_op],
feed_dict={x: mbatch_x,
phase_train: True})
train_writer.add_summary(train_summary,
sess.run(global_step))
# Compute average loss
avg_cost += new_cost/total_batch
# Display logs per epoch step
if epoch % display_step == 0:
print "Epoch: ", ‘%04d' % (epoch+1), "cost =", "{:.9f}".format(avg_cost)
train_writer.add_summary(train_summary, sess.run(global_step))
val_images = mnist.validation.images
validation_loss, in_im, out_im,
val_summary = sess.run([eval_op, in_im_op, out_im_op, val_summary_op], feed_dict={x: val_images, phase_train: False})
val_writer.add_summary(in_im, sess.run (global_step))
val_writer.add_summary(out_im, sess.run (global_step))
val_writer.add_summary(val_summary, sess.run (global_step))
print "Validation Loss: ", validation_loss
saver.save(sess, "mnist_autoencoder_hidden=" + n_code + "_logs/model-checkpoint-" + ‘%04d' % (epoch+1), global_step=global_step)
print "Optimization Finished!"
test_loss = sess.run(eval_op, feed_dict={x: mnist.test.images, phase_train: False})
print "Test Loss: ", loss
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.