Jane M. Horgan - Probability with R
Здесь есть возможность читать онлайн «Jane M. Horgan - Probability with R» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Probability with R
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Probability with R: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Probability with R»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
is used throughout the text, not only as a tool for calculation and data analysis, but also to illustrate concepts of probability and to simulate distributions. The examples in
cover a wide range of computer science applications, including: testing program performance; measuring response time and CPU time; estimating the reliability of components and systems; evaluating algorithms and queuing systems.
Chapters cover: The R language; summarizing statistical data; graphical displays; the fundamentals of probability; reliability; discrete and continuous distributions; and more.
This second edition includes:
improved R code throughout the text, as well as new procedures, packages and interfaces; updated and additional examples, exercises and projects covering recent developments of computing; an introduction to bivariate discrete distributions together with the R functions used to handle large matrices of conditional probabilities, which are often needed in machine translation; an introduction to linear regression with particular emphasis on its application to machine learning using testing and training data; a new section on spam filtering using Bayes theorem to develop the filters; an extended range of Poisson applications such as network failures, website hits, virus attacks and accessing the cloud; use of new allocation functions in R to deal with hash table collision, server overload and the general allocation problem. The book is supplemented with a Wiley Book Companion Site featuring data and solutions to exercises within the book.
Primarily addressed to students of computer science and related areas,
is also an excellent text for students of engineering and the general sciences. Computing professionals who need to understand the relevance of probability in their areas of practice will find it useful.
Probability with R — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Probability with R», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
1.13 Project
Download RStudio and familiarize yourself with its workings, by using it to do Exercise 1. Decide, at this point, whether you prefer using RStudio for your data analysis rather than using R directly. Follow your preference throughout the rest of the book. It is up to you!
Reference
1 Venables, W.N., Smith, D.M. and the R Core Team (2018), An Introduction to R, Notes on R: A Programming Environment for Data Analysis and Graphics, Version 3.6.1 (2019-07-05).
2 Summarizing Statistical Data
In this chapter, we explore some of the procedures available in R to summarize statistical data, and we give some examples of writing programs.
2.1 Measures of Central Tendency
Measures of central tendency are typical or central points in the data. The most commonly used are the mean and the median.
Mean:The mean is the sum of all values divided by the number of cases, excluding the missing values.
To obtain the mean of the data in Example 1.1stored in 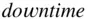 write
write
mean(downtime)[1] 25.04348
So the average downtime of all the computers in the laboratory is just over 25 minutes.
Going back to the original data in Exercise 1.1 stored in marks , to obtain the mean, write
mean(marks)
which gives
[1] 57.44
To obtain the mean marks for females, write
mean(marks[1:23]) [1] 65.86957
For males,
mean(marks[24:50]) [1] 50.25926
illustrating that the female average is substantially higher than the male average.
To obtain the mean of the corrected data in Exercise 1.1, recall that the mark of 86 for the 34th student on the list was an error, and that it should have been 46. We changed it with
marks[34] <- 46
The new overall average is
mean(marks) 56.64
and the new male average is
mean(marks[24:50]) [1] 48.77778
increasing the gap between the male and female averages even further.
If we perform a similar operation for the variables in the examination data given in Example 1.2, we run into trouble. Suppose we want the mean mark for Architecture in Semester 1. In R
mean(arch1)
gives
[1] NA
Recall that, in the results file, we recorded the missing marks with the special value 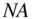 to indicate that these marks were “not available”. R will not perform arithmetic operations on objects containing NA , unless specifically mandated to skip
to indicate that these marks were “not available”. R will not perform arithmetic operations on objects containing NA , unless specifically mandated to skip  remove missing values. To do this, you need to insert the argument
remove missing values. To do this, you need to insert the argument na.rm = Tor na.rm = TRUE,(not available, remove) into the function.
For arch 1, writing
mean(arch1, na.rm = TRUE)
yields
[1] 63.56897
To obtain the mean of all the variables in results file, we use the R function sapply.
sapply(results, mean, na.rm = T)
yields
gender arch1 prog1 arch2 prog2 NA 63.56897 59.01709 51.97391 53.78378
Notice that a  message is returned for gender. The reason for this is that the gender variable is nonnumeric, and R cannot calculate its mean. We could, instead specify the columns that we want to work on.
message is returned for gender. The reason for this is that the gender variable is nonnumeric, and R cannot calculate its mean. We could, instead specify the columns that we want to work on.
sapply(results[2:5], mean, na.rm = TRUE)
gives
arch1 prog1 arch2 prog2 63.56897 59.01709 51.97391 53.78378
Median:The median is the middle value of the data set; 50% of the observations is less and 50% is more than this value.
In R
median(downtime)
yields
[1] 25
which means that 50% of the computers experienced less than 25 minutes of downtime, while 50% experienced more than 25 minutes of downtime.
Also,
median(marks) [1] 55.5
In both of these examples ( 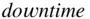 and
and 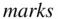 ), you will observe that the medians are not too far away from their respective means.
), you will observe that the medians are not too far away from their respective means.
The median is particularly useful when there are extreme values in the data. Let us look at another example.
Example 2.1 Apps Usage
Examining the nine apps with greatest usage on your smartphone, you may find the usage statistics (in MB) are
| App | Usage (MB) |
| 39.72 | |
| Chrome | 35.37 |
| 5.73 | |
| 5.60 | |
| System Account | 3.30 |
| 3.22 | |
| Gmail | 2.52 |
| Messenger | 1.71 |
| Maps | 1.55 |
To enter the data, write
usage <- c(39.72, 35.27, 5.73, 5.6, 3.3, 3.22, 2.52, 1.71, 1.55)
The mean is
mean(usage) [1] 10.95778
while the median is
median(usage) [1] 3.3
Unlike the previous examples, where the mean and median were similar, here the mean is more than three times the median. Looking at the data again, you will notice that the usage of the first two apps, Facebook and Chrome, is much larger than the usages of the other apps in the data set. These values are the cause of the mean being so high. Such values are often designated as outliers and are analyzed separately. Omitting them and calculating the mean and median once more, we get
mean(usage[3:9]) [1] 3.375714 median(usage[3:9]) [1] 3.22
Now, we see that there is not much difference between the mean and median.
When there are extremely high values in the data, using the mean as a measure of central tendency gives the wrong impression. A classic example of this is wage statistics where there may be a few instances of very high salaries, which will grossly inflate the average, giving the impression that salaries are higher than they actually are.
2.2 Measures of Dispersion
Measures of dispersion, as the name suggests, estimate the spread or variation in a data set. There are many ways of measuring spread, and we consider some of the most common.
Range:The simplest measure of spread of data is the range, which is the difference between the maximum and the minimum values.
rangedown <- max(downtime) - min(downtime) rangedown [1] 51
tells us that the range in the downtime data is 51 minutes.
rangearch1 <- max(arch1, na.rm = T) - min(arch1, na.rm = T) rangearch1 [1] 97
gives the range of the marks awarded in Architecture in Semester 1.
The R function rangemay also be used.
range(arch1, na.rm = TRUE) [1] 3 100
which gives the minimum (3) and the maximum (100) of the marks obtained in Architecture in Semester 1.
Note that, since arch1 contains missing values, the declaration of na.rm = Tor equivalently na.rm = TRUEneeds to be used.
To get the range for all the examination subjects in results, we use the function sapply.
sapply(results[2:5], range, na.rm = TRUE)
gives the minimum and maximum of each subject.
arch1 prog1 arch2 prog2 [1,] 3 12 6 5 [2,] 100 98 98 97
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Probability with R»
Представляем Вашему вниманию похожие книги на «Probability with R» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Probability with R» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.