Jane M. Horgan - Probability with R
Здесь есть возможность читать онлайн «Jane M. Horgan - Probability with R» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Probability with R
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Probability with R: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Probability with R»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
is used throughout the text, not only as a tool for calculation and data analysis, but also to illustrate concepts of probability and to simulate distributions. The examples in
cover a wide range of computer science applications, including: testing program performance; measuring response time and CPU time; estimating the reliability of components and systems; evaluating algorithms and queuing systems.
Chapters cover: The R language; summarizing statistical data; graphical displays; the fundamentals of probability; reliability; discrete and continuous distributions; and more.
This second edition includes:
improved R code throughout the text, as well as new procedures, packages and interfaces; updated and additional examples, exercises and projects covering recent developments of computing; an introduction to bivariate discrete distributions together with the R functions used to handle large matrices of conditional probabilities, which are often needed in machine translation; an introduction to linear regression with particular emphasis on its application to machine learning using testing and training data; a new section on spam filtering using Bayes theorem to develop the filters; an extended range of Poisson applications such as network failures, website hits, virus attacks and accessing the cloud; use of new allocation functions in R to deal with hash table collision, server overload and the general allocation problem. The book is supplemented with a Wiley Book Companion Site featuring data and solutions to exercises within the book.
Primarily addressed to students of computer science and related areas,
is also an excellent text for students of engineering and the general sciences. Computing professionals who need to understand the relevance of probability in their areas of practice will find it useful.
Probability with R — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Probability with R», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
which are all of the objects that contain the word “boxplot.”
1.6 Data Entry
Before carrying out a statistical analysis, it is necessary to get the data into the computer. How you do this varies depending on the amount of data involved.
1.6.1 Reading and Displaying Data on Screen
A small data set, for example, a small set of repeated measurements on a single variable, may be entered directly from the screen. It is usually stored as a vector, which is essentially a list of numbers.
Example 1.1 Entering data from the screen to a vector
The total downtime occurring in the last month of 23 workstations in a computer laboratory was observed (in minutes) as follows:
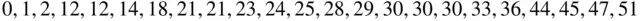
To input these data from the screen environment of R , write
downtime <- c(0, 1, 2, 12, 12, 14, 18, 21, 21, 23, 24, 25, 28, 29, 30, 30, 30, 33, 36, 44, 45, 47, 51)
The construct  is used to define a vector containing the 23 data points. These data are then assigned to a vector called downtime .
is used to define a vector containing the 23 data points. These data are then assigned to a vector called downtime .
To view the contents of the vector, type
downtime
which will display all the values in the vector 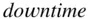 .
.
R handles a vector as a single object. Calculations can be done with vectors like ordinary numbers provided they are the same length.
1.6.2 Reading Data from a File to a Data Frame
When the data set is large, it is better to set up a text file to store the data than to enter them directly from the screen.
A large data set is usually stored as a matrix, which consists of columns and rows. The columns denote the variables, while the rows are the observations on the variables. In R , this type of data set is stored in what is referred to as a data frame .
Definition 1.1 Data frame
A data frame is an object with rows and columns or equivalently it is a list of vectors of the same length. Each vector consists of repeated observations of some variable. The variables may be numbers, strings or factors.
Example 1.2 Reading data from a file into a data frame
The examination results for a class of 119 students pursuing a computing degree are given on our companion website ( www.wiley.com/go/Horgan/probabilitywithr2e) as a text file called 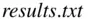 . The complete data set is also given in Appendix A.
. The complete data set is also given in Appendix A.
gender arch1 prog1 arch2 prog2 m 99 98 83 94 m NA NA 86 77 m 97 97 92 93 m 99 97 95 96 m 89 92 86 94 m 91 97 91 97 m 100 88 96 85 f 86 82 89 87 m 89 88 65 84 m 85 90 83 85 m 50 91 84 93 m 96 71 56 83 f 98 80 81 94 m 96 76 59 84 ....
The first row of the file contains the headings, gender and arch1, prog1, arch2, prog2, which are abbreviations for Architecture and Programming from Semester 1 and Semester 2, respectively. The remaining rows are the marks (%) obtained for each student. NA denotes that the marks are not available in this particular case.
The construct for reading this type of data into a data frame is read.table.
results <- read.table ("F:/data/results.txt", header = T)
assuming that your data file 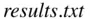 is stored in the
is stored in the 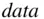 folder on the F drive. This command causes the data to be assigned to a data frame called results . Here
folder on the F drive. This command causes the data to be assigned to a data frame called results . Here header = Tor equivalently header = TRUEspecifies that the first line is a header, in this case containing the names of the variables. Notice that the forward slash (  ) is used in the filename, not the backslash
) is used in the filename, not the backslash (\)which would be expected in the windows environment. The backslash has itself a meaning within R , and cannot be used in this context: / or \\are used instead. Thus, we could have written
results <- read.table ("F:\\data\\results.txt", header = TRUE)
with the same effect.
The contents of the file results may be listed on screen by typing
results
which gives
gender arch1 prog1 arch2 prog2 1 m 99 98 83 94 2 m NA NA 86 77 3 m 97 97 92 93 4 m 99 97 95 96 5 m 89 92 86 94 6 m 91 97 91 97 7 m 100 88 96 85 8 f 86 82 89 87 9 m 89 88 65 84 10 m 85 90 83 85 11 m 50 91 84 93 12 m 96 71 56 83 13 f 98 80 81 94 14 m 96 76 59 84 ....
Notice that the gender variable is a factor with two levels “f” and “m,”while the remaining four variables are numeric. The figures in the first column on the left are the row numbers, and allows us to access individual elements in the data frame .
While we could list the entire data frame on the screen, this is inconvenient for all but the smallest data sets. R provides facilities for listing the first few rows and the last few rows.
head(results, n = 4)
gives the first four rows of the data set.
gender arch1 prog1 arch2 prog2 1 m 99 98 83 94 2 m NA NA 86 77 3 m 97 97 92 93 4 m 99 97 95 96
and
tail(results, n = 4)
gives the last four lines of the data set.
gender arch1 prog1 arch2 prog2 116 m 16 27 25 7 117 m 73 51 48 23 118 m 56 54 49 25 119 m 46 64 13 19
The convention for accessing the column variables is to use the name of the data frame followed by the name of the relevant column. For example,
results$arch1[5]
returns
[1] 89
which is the fifth observation in the column labeled arch1 .
Usually, when a new data frame is created, the following two commands are issued.
attach(results) names(results)
which give
[1] "gender" "arch1" "prog1" "arch2" "prog2"
indicating that the column variables can be accessed without the prefix results. For example,
arch1[5]
gives
[1] 89
The command read.tableassumes that the data in the text file are separated by spaces. Other forms include:
read.csv, used when the data points are separated by commas;
read.csv2, used when the data are separated by semicolons.
It is also possible to enter data into a spreadsheet and store it in a data frame, by writing
newdata <- data.frame() fix(newdata)
which brings up a blank spreadsheet called newdata , and the user may then enter the variable labels and the variable values.
Right click and close creates a data frame newdata in which the new information is stored.
If you subsequently need to amend or add to this data frame write
fix(newdata)
which retrieves the spreadsheet with the data. You can then edit the data as required. Right click and close saves the amended data frame.
1.7 Missing Values
R allows vectors to contain a special 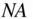 value to indicate that the data point is not available. In the second record in
value to indicate that the data point is not available. In the second record in 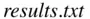 , notice that
, notice that 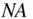 appears for arch1 and prog1 . This means that the marks for this student are not available in Architecture and Programming in the first semester; the student may not have sat these examinations. The absent marks are referred to as
appears for arch1 and prog1 . This means that the marks for this student are not available in Architecture and Programming in the first semester; the student may not have sat these examinations. The absent marks are referred to as 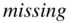
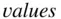 , and are not included at the analysis stage.
, and are not included at the analysis stage.
Интервал:
Закладка:
Похожие книги на «Probability with R»
Представляем Вашему вниманию похожие книги на «Probability with R» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Probability with R» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.