Samprit Chatterjee - Handbook of Regression Analysis With Applications in R
Здесь есть возможность читать онлайн «Samprit Chatterjee - Handbook of Regression Analysis With Applications in R» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Handbook of Regression Analysis With Applications in R
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Handbook of Regression Analysis With Applications in R: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Handbook of Regression Analysis With Applications in R»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
andbook and reference guide for students and practitioners of statistical regression-based analyses in R
Handbook of Regression Analysis
with Applications in R, Second Edition
The book further pays particular attention to methods that have become prominent in the last few decades as increasingly large data sets have made new techniques and applications possible. These include:
Regularization methods Smoothing methods Tree-based methods In the new edition of the
, the data analyst’s toolkit is explored and expanded. Examples are drawn from a wide variety of real-life applications and data sets. All the utilized R code and data are available via an author-maintained website.
Of interest to undergraduate and graduate students taking courses in statistics and regression, the
will also be invaluable to practicing data scientists and statisticians.
Handbook of Regression Analysis With Applications in R — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Handbook of Regression Analysis With Applications in R», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
There is a straightforward way to get a sense of the predictive power of a chosen model if enough data are available. This can be evaluated by holding out some data from the analysis (a holdoutor validationsample), applying the selected model from the original data to the holdout sample (based on the previously estimated parameters, not estimates based on the new data), and then examining the predictive performance of the model. If, for example, the standard deviation of the errors from this prediction is not very different from the standard error of the estimate in the original regression, chances are making inferences based on the chosen model will not be misleading. Similarly, if a (say) 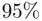 prediction interval does not include roughly
prediction interval does not include roughly 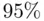 of the new observations, that indicates poorer‐than‐expected predictive performance on new data.
of the new observations, that indicates poorer‐than‐expected predictive performance on new data.
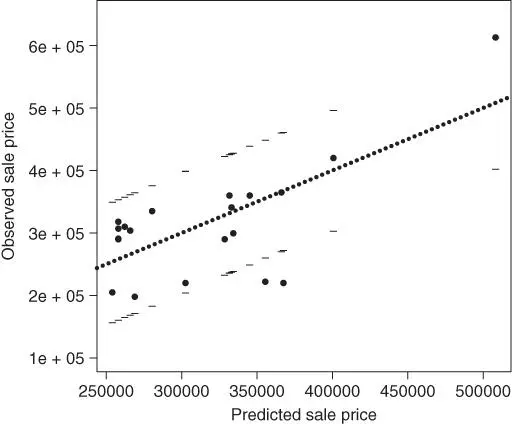
FIGURE 2.3: Plot of observed versus predicted house sale price values of validation sample, with pointwise 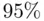 prediction interval limits superimposed. The dotted line corresponds to equality of observed values and predictions.
prediction interval limits superimposed. The dotted line corresponds to equality of observed values and predictions.
Figure 2.3illustrates a validation of the three‐predictor housing price model on a holdout sample of 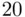 houses. The figure is a plot of the observed versus predicted prices, with pointwise
houses. The figure is a plot of the observed versus predicted prices, with pointwise 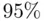 prediction interval limits superimposed. The intervals contain
prediction interval limits superimposed. The intervals contain 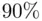 of the prices (
of the prices ( 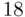 of
of 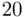 ), and the average predictive error on the new houses is only
), and the average predictive error on the new houses is only 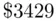 (compared to an average observed price of more than
(compared to an average observed price of more than 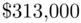 ), not suggesting the presence of any forecasting bias in the model. Two of the houses, however, have sale prices well below what would have been expected (more than
), not suggesting the presence of any forecasting bias in the model. Two of the houses, however, have sale prices well below what would have been expected (more than 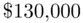 lower than expected), and this is reflected in a much higher standard deviation (
lower than expected), and this is reflected in a much higher standard deviation ( 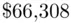 ) of the predictive errors than
) of the predictive errors than 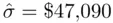 from the fitted regression. If the two outlying houses are omitted, the standard deviation of the predictive errors is much smaller (
from the fitted regression. If the two outlying houses are omitted, the standard deviation of the predictive errors is much smaller ( 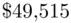 ), suggesting that while the fitted model's predictive performance for most houses is in line with its performance on the original sample, there are indications that it might not predict well for the occasional unusual house.
), suggesting that while the fitted model's predictive performance for most houses is in line with its performance on the original sample, there are indications that it might not predict well for the occasional unusual house.
If validating the model on new data this way is not possible, a simple adjustment that is helpful is to estimate the variance of the errors as
(2.4) 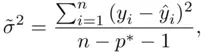
where 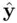 is based on the chosen “best” model, and
is based on the chosen “best” model, and 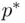 is the number of predictors in the most complex model examined, in the sense of most predictors (Ye, 1998). Clearly, if very complex models are included among the set of candidate models,
is the number of predictors in the most complex model examined, in the sense of most predictors (Ye, 1998). Clearly, if very complex models are included among the set of candidate models, 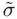 can be much larger than the standard error of the estimate from the chosen model, with correspondingly wider prediction intervals. This reinforces the benefit of limiting the set of candidate models (and the complexity of the models in that set) from the start. In this case
can be much larger than the standard error of the estimate from the chosen model, with correspondingly wider prediction intervals. This reinforces the benefit of limiting the set of candidate models (and the complexity of the models in that set) from the start. In this case 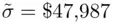 , so the effect is not that pronounced.
, so the effect is not that pronounced.
The adjustment of the denominator in (2.4)to account for model selection uncertainty is just a part of the more general problem that standard degrees of freedom calculations are no longer valid when multiple models are being compared to each other as in the comparison of all models with a given number of predictors in best subsets. This affects other uses of those degrees of freedom, including the calculation of information measures like 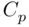 ,
, 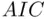 ,
, 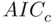 , and
, and 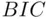 , and thus any decisions regarding model choice. This problem becomes progressively more serious as the number of potential predictors increases and is the subject of active research. This will be discussed further in Chapter 14.
, and thus any decisions regarding model choice. This problem becomes progressively more serious as the number of potential predictors increases and is the subject of active research. This will be discussed further in Chapter 14.
2.4 Indicator Variables and Modeling Interactions
It is not unusual for the observations in a sample to fall into two distinct subgroups; for example, people are either male or female. It might be that group membership has no relationship with the target variable (given other predictors); such a pooled modelignores the grouping and pools the two groups together.
On the other hand, it is clearly possible that group membership is predictive for the target variable (for example, expected salaries differing for men and women given other control variables could indicate gender discrimination). Such effects can be explored easily using an indicator variable, which takes on the value 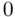 for one group and
for one group and 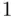 for the other (such variables are sometimes called dummy variablesor
for the other (such variables are sometimes called dummy variablesor 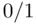 variables). The model takes the form
variables). The model takes the form
Интервал:
Закладка:
Похожие книги на «Handbook of Regression Analysis With Applications in R»
Представляем Вашему вниманию похожие книги на «Handbook of Regression Analysis With Applications in R» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Handbook of Regression Analysis With Applications in R» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.