Matthew B. Hamilton - Population Genetics
Здесь есть возможность читать онлайн «Matthew B. Hamilton - Population Genetics» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Population Genetics
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Population Genetics: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Population Genetics»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
is the classic, accessible introduction to the concepts of population genetics. Combining traditional conceptual approaches with classical hypotheses and debates, the book equips students to understand a wide array of empirical studies that are based on the first principles of population genetics.
Featuring a highly accessible introduction to coalescent theory, as well as covering the major conceptual advances in population genetics of the last two decades, the second edition now also includes end of chapter problem sets and revised coverage of recombination in the coalescent model, metapopulation extinction and recolonization, and the fixation index.
Population Genetics — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Population Genetics», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Empirical study in population genetics also plays a central role in constructing and evaluating predictions. In population genetics as in all sciences, empirical evidence is drawn from intentional observations, cleverly constructed comparisons, and experiments. Genetic patterns observed in actual populations are compared with expected patterns to test models constructed using general principles and assumptions. For example, we could construct a mathematical or computer simulation model of random genetic drift (change in allele frequency due to sampling from finite populations) based on abstract principles of sampling from a finite population and biological reproduction. We could then compare the predictions of such a model to the observed change in allele frequency through time in a laboratory population of Drosophila melanogaster (fruit flies). If the change in allele frequency in the fruit fly population matched the change in allele frequency predicted using the model of genetic drift, then we could conclude that the model effectively summarizes the biological sampling processes that take place in fruit fly populations.
It is also possible to use well‐tested and accepted model expectations as a basis to hypothesize what processes caused an observed pattern in a biological population. Again, to use a D. melanogaster population as an example, we might ask whether an observed change in allele frequency over some generations in a wild population could be explained by genetic drift. If the observed allele frequency change is within the range of the predicted change in allele frequencies based on a model of genetic drift, then we have identified a possible cause of the observed pattern. Comparing observed genetic patterns in populations often requires modifications to existing models or the construction of novel models in order to develop appropriate expectations. For example, a model of genetic drift constructed for D. melanogaster might naturally assume that all individuals in the population are diploid (individuals that possess paired sets of homologous chromosomes). If we wanted to use that same model to predict genetic drift in a population of honeybees, we would have to account for the fact that their males are haploid (individuals that possess single copies of each chromosome) while females are diploid. This change in reproductive biology could be taken into account by altering the assumptions of the model of genetic drift to make predictions appropriate for honeybee populations. Note that without some modifications, a single model of genetic drift would not accurately predict allele frequencies over time in both fruit flies and honeybees since their patterns of reproduction and chromosomal inheritance are different.
Parameters and parameter estimates
While developing the expectations of population genetics in this book, we will most often be working with idealized quantities. For example, allele frequency in a population is a fundamental quantity. For a genetic locus with two alleles, A and a, it is common to say that p equals the frequency of the A allele and q equals the frequency of the a allele. In mathematics, parameteris another term for an idealized quantity like an allele frequency. It is assumed that parameters have an exact value. Put another way, parameters are idealized quantities where the messy, real‐life details of how to measure the quantities they represent are completely ignored.
Empirical population genetics measures quantities such as allele frequencies to give parameter estimatesby sampling and then measuring the alleles and genotypes present in actual populations. All experiments, observations, and even simulations in population genetics produce parameter estimates of some sort. There is a subtle notational convention used to indicate an estimate, that is, the hat or ^ character above a variable. Estimates wear hats whereas parameters do not. Using allele frequency as an example, we would say 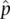 (pronounced “ p hat”) equals the number of A alleles sampled divided by the total number of alleles sampled. Intuitively, we can see from the denominator in the expression for
(pronounced “ p hat”) equals the number of A alleles sampled divided by the total number of alleles sampled. Intuitively, we can see from the denominator in the expression for 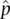 that the allele frequency estimate will depend on the sample we gather to make the estimate.
that the allele frequency estimate will depend on the sample we gather to make the estimate.
In actual populations, a parameter has a true value. For the allele frequency p , knowing this true value would require examining the genotype of every individual and counting all A and a alleles to determine their frequency in the population. This task is impractical or impossible in most cases. Instead, we rely on an estimate of allele frequency, 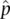 , obtained from a sample of individuals from the population. Sampling leads to some uncertainty in parameter estimates because repeating the sampling and parameter estimate process would likely lead to a somewhat different parameter estimate each time. Quantifying this uncertainty is important to determine whether repeated sampling might change a parameter estimate by just a little or change it by a lot. When dealing with parameters, we might expect that p + q = 1 exactly if there are only two alleles with allele frequencies p and q . However, if we are dealing with estimates, we might say the two allele frequency estimates should sum to approximately one (
, obtained from a sample of individuals from the population. Sampling leads to some uncertainty in parameter estimates because repeating the sampling and parameter estimate process would likely lead to a somewhat different parameter estimate each time. Quantifying this uncertainty is important to determine whether repeated sampling might change a parameter estimate by just a little or change it by a lot. When dealing with parameters, we might expect that p + q = 1 exactly if there are only two alleles with allele frequencies p and q . However, if we are dealing with estimates, we might say the two allele frequency estimates should sum to approximately one ( 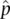 +
+  ≈ 1) since each allele frequency is estimated with some errors. The more uncertain the estimates of
≈ 1) since each allele frequency is estimated with some errors. The more uncertain the estimates of 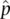 and
and 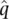 , the less we should be surprised to find that their sum does not equal the expected value of one.
, the less we should be surprised to find that their sum does not equal the expected value of one.
Parameter:A variable or constant appearing in a mathematical expression; a value (usually unknown) used to represent a certain population characteristic; any factor that defines a system and determines or limits its performance.
Estimate:An indication of the value of an unknown quantity based on observed data; an approximation of a true score, parameter, or value; a statistical estimate of the value of a parameter.
It could be said that statistics sits at the intersection of theoretical and empirical population genetics. Parameters and parameter estimates are fundamentally different things. Estimation requires effort to understand sampling variation and quantify sources of error and bias in samples and estimates. The distinction between parameters and estimates is critical when comparing actual populations with expectations to test hypotheses. When large, random samples can be taken, estimates are likely to have minimal errors. However, there are many cases where estimates have a great deal of uncertainty, which limits the ability to evaluate expectations. There are also instances where very different processes may produce very similar expected results. In such cases, it may be difficult or impossible to distinguish the different potential causes of a pattern due to the approximate nature of estimates. While this book focuses mostly on parameters, it is useful to bear in mind that testing or comparing expectations requires the use of parameter estimates and statistics that quantify sampling error. The Appendix provides a review of some basic statistics that are used in the text.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Population Genetics»
Представляем Вашему вниманию похожие книги на «Population Genetics» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Population Genetics» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.