Aiden A. Bruen - Cryptography, Information Theory, and Error-Correction
Здесь есть возможность читать онлайн «Aiden A. Bruen - Cryptography, Information Theory, and Error-Correction» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Cryptography, Information Theory, and Error-Correction
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Cryptography, Information Theory, and Error-Correction: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Cryptography, Information Theory, and Error-Correction»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
A rich examination of the technologies supporting secure digital information transfers from respected leaders in the field Cryptography, Information Theory, and Error-Correction: A Handbook for the 21ST Century
Cryptography, Information Theory, and Error-Correction
Cryptography, Information Theory, and Error-Correction — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Cryptography, Information Theory, and Error-Correction», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
2.5 Frequency Analysis
The idea behind the use of frequency analysis in cryptanalysis is that all human languages have underlying statistical patterns and redundancies that can be exploited to help break a variety of ciphers. For the English language, it is well documented that the distribution of the most frequent characters is remarkably similar throughout texts of diverse style and length, as indicated in Table 2.1.
Table 2.1Approximate frequencies of letters in the English language.
| Letter | Frequency (%) | Letter | Frequency (%) |
| a | 7.44 | b | 1.46 |
| c | 2.52 | d | 3.53 |
| e | 12.22 | f | 2.68 |
| g | 1.84 | h | 5.97 |
| i | 6.82 | j | 0.20 |
| k | 0.65 | l | 4.28 |
| m | 2.71 | n | 6.32 |
| o | 8.25 | p | 1.97 |
| q | 0.12 | r | 6.21 |
| s | 6.99 | t | 9.85 |
| u | 3.67 | v | 0.12 |
| w | 2.09 | x | 0.18 |
| y | 1.87 | z | 0.03 |
Source: These percentages are based on the book “The Tragical History of Doctor Faustus”, by Christopher Marlowe, which is a book of approximately 100 000 characters that was chosen randomly from the Project Gutenberg .
Frequency analysis can be used for cryptanalysis. However, one needs a lot of craft in its use, along with any information that can be gathered about the contents of the message and the sender.
2.6 Breaking the Vigenère Cipher, Babbage–Kasiski
Now that the Vigenère cipher has been defined, we will show how to use the frequencies of letters in English, to break this cipher. We have two tasks.
Find the keyword length.
Find the keyword itself.
We have two methods to find the length of the keyword. The first method, the Babbage–Kasiski method, attempts to find repeated successive triples (or four‐tuples, or five‐tuples, etc.,) of letters in the cipher text. The second method treats the English language like a stationary or even ergodic source (see Chapter 11).
We will use two fundamental principles in carrying out our tasks.
“E” is the most frequent letter of the English language.
Informally, written English tends to “repeat itself.” This means that the frequencies of a passage starting in position 1 are similar to the frequencies of the passage starting in position when we slide the text along itself.
Once we obtain 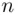 , the key‐length, we can find the keyword itself. We do this by using the first fundamental property above. Namely, we exploit the statistics of the letters in English, or pairs of letters (i.e. digrams), or trigrams, etc.
, the key‐length, we can find the keyword itself. We do this by using the first fundamental property above. Namely, we exploit the statistics of the letters in English, or pairs of letters (i.e. digrams), or trigrams, etc.
The second principle has two important interpretations. For the Babbage–Kasiski method, this means that if we find a repeated letter (or sequence of letters) in the cipher text there is a good chance that it comes from a given letter (or sequence of letters) in the plain text that has been enciphered by a given letter (or letters) in the key. Thus, there is a reasonable expectation that the distances between such repeated sequences of letters equals the key length or a multiple of the key length.
The second principle has an important implication in terms of our second method, called the method of “coincidences,” as well. The basic idea is explained in an example below.
The Babbage–Kasiski method
To demonstrate this method for finding 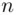 , suppose we received the following cipher text:
, suppose we received the following cipher text:
| EHMVL | VDWLP | WIWXW | PMMYD | PTKNF | RHWXS |
| LTWLP | OSKNF | WDGNF | DEWLP | SOXWP | HIWLL |
| EHMYD | LNGPT | EEUWE | QLLSX | TUP |
Our task is to search for repetitions in the above text. For a small cipher text, the brute‐force method is not too difficult. We focus on trigrams, and highlight some as follows:

After having found these, we compute the distances between the trigrams.
| EHM | ‐ | 60 |
| WLP | ‐ | 25,15,40 |
| XWP | ‐ | 39 |
| MYD | ‐ | 45 |
We note that with the exception of 39, 5 divides all of the distances. In fact, if we proceed with frequency analysis, it turns out that we can decipher this message with a key length of 5. The codeword is “ladel,” and the plain text is “Thor and the little mouse thought that they should douse the house with a thousand liters of lithium” (Who said that secret messages have to have a clear meaning!) Frequency analysis is used in our next example below.
It is purely by chance that we had the repeated trigram WXP – this repeated trigram was not the result of the same three letters being enciphered by the same part of the keyword. This highlights the fact that the above method is probabilistic.
The method of coincidences
We will now use the second principle of “coincidences,” to find the length of the keyword. The sequence of plain text letters in positions 1 to 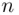 ,
, 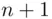 to
to 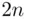 ,
, 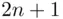 , to
, to 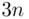 , etc., should be approximately the same, especially if
, etc., should be approximately the same, especially if 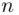 is large. It follows that a similar result holds true for the corresponding sequences of cipher text letters. Thus, if we slide the cipher text along itself and count the number of coincidences (i.e. agreements) at each displacement, then on average the maximum number of coincidences will occur after an integer multiple of the keyword length
is large. It follows that a similar result holds true for the corresponding sequences of cipher text letters. Thus, if we slide the cipher text along itself and count the number of coincidences (i.e. agreements) at each displacement, then on average the maximum number of coincidences will occur after an integer multiple of the keyword length 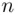 (i.e. the max occurs for some
(i.e. the max occurs for some 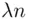 ,
, 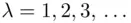 ). This technique can be illustrated using the following example: We will first determine the period
). This technique can be illustrated using the following example: We will first determine the period 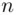 and use it to determine the nature of the keyword from a cipher text passage:
and use it to determine the nature of the keyword from a cipher text passage:
Интервал:
Закладка:
Похожие книги на «Cryptography, Information Theory, and Error-Correction»
Представляем Вашему вниманию похожие книги на «Cryptography, Information Theory, and Error-Correction» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Cryptography, Information Theory, and Error-Correction» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.