Vahid Mirjalili - Python Machine Learning
Здесь есть возможность читать онлайн «Vahid Mirjalili - Python Machine Learning» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на испанском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Python Machine Learning
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Python Machine Learning: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Python Machine Learning»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Modernizado y ampliado para incluir las tecnologías de código abierto más recientes, como scikit-learn, Keras y TensorFlow, este manual proporciona el conocimiento práctico y las técnicas necesarias para crear eficaces aplicaciones de aprendizaje automático y aprendizaje profundo en Python.
El conocimiento y la experiencia únicos de Sebastian Raschka y Vahid Mirjalili presentan los algoritmos de aprendizaje automático y aprendizaje profundo, antes de continuar con temas avanzados en análisis de datos.
Combinan los principios teóricos del aprendizaje automático con un enfoque práctico de codificación para una comprensión completa de la teoría del aprendizaje automático y la implementación con Python.
Aprenderás a:
Explorar y entender los frameworks clave para la ciencia de datos, el aprendizaje automático y el aprendizaje profundo
Formular nuevas preguntas sobre datos con modelos de aprendizaje automático y redes neuronales
Aprovechar el poder de las últimas librerías de código abierto de Python para aprendizaje automático
Dominar la implementación de redes neuronales profundas con la librería de TensorFlow
Incrustar modelos de aprendizaje automáticos en aplicacions web accesibles
Predecir resultados objetivos continuos con análisis de regresión
Descubrir patrones ocultos y estructuras en datos con agrupamientos
Analizar imágenes mediante técnicas de aprendizaje profundo
Profundizar en datos de medios sociales y textuales con el análisis de sentimientos
Python Machine Learning — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Python Machine Learning», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
... n_iter=1000,
... random_state=1)
>>> lrgd.fit(X_train_01_subset,
... y_train_01_subset)The
>>> plot_decision_regions(X=X_train_01_subset,
... y=y_train_01_subset,
... classifier=lrgd)
>>> plt.xlabel('petal length [standardized]')
>>> plt.ylabel('petal width [standardized]')
>>> plt.legend(loc='upper left')
>>> plt.show()
La gráfica de la región de decisión resultante tiene el aspecto siguiente:
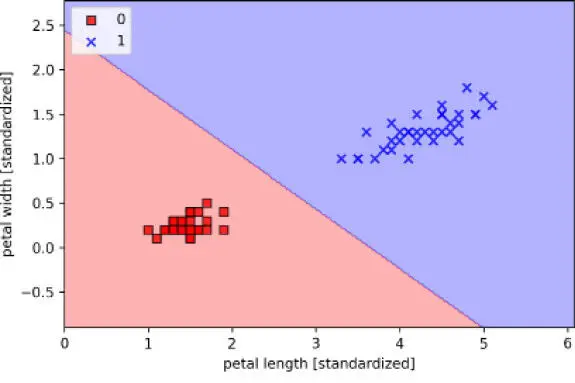
 |
 |
El algoritmo de aprendizaje del descenso del gradiente para regresión logísticaCon el cálculo, podemos mostrar que la actualización de peso en regresión logística mediante el descenso del gradiente es igual a la ecuación que utilizamos en Adaline en el Capítulo 2, Entrenar algoritmos simples de aprendizaje automático para clasificación. Sin embargo, debes tener en cuenta que la siguiente derivación de la regla de aprendizaje del descenso del gradiente va destinada a aquellos lectores que estén interesados en los conceptos matemáticos que hay detrás de la regla de aprendizaje del descenso del gradiente para regresión logística. No es esencial para seguir con el resto de este capítulo.Empezaremos calculando la derivada parcial de la función de probabilidad logarítmica con respecto al peso j: 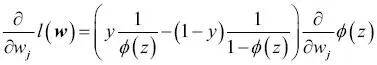 Antes de continuar, calcularemos también la derivada parcial de la función sigmoide: Antes de continuar, calcularemos también la derivada parcial de la función sigmoide: 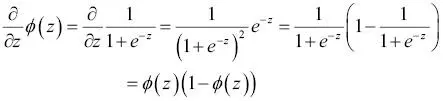 |
 |
 |
|
Ahora, podemos volver a sustituir 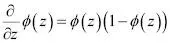 en nuestra primera ecuación para obtener lo siguiente: en nuestra primera ecuación para obtener lo siguiente: 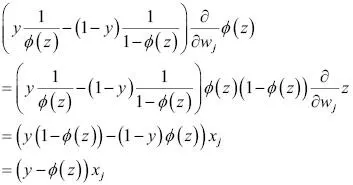 Recuerda que el objetivo es encontrar los pesos que maximicen la probabilidad logarítmica, por lo que llevamos a cabo la actualización para cada peso del modo siguiente: Recuerda que el objetivo es encontrar los pesos que maximicen la probabilidad logarítmica, por lo que llevamos a cabo la actualización para cada peso del modo siguiente: 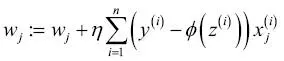 Como actualizamos todos los pesos simultáneamente, podemos escribir la regla de actualización general así: Como actualizamos todos los pesos simultáneamente, podemos escribir la regla de actualización general así: 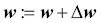 Definimos Definimos 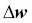 así: así: 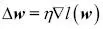 Como maximizar la probabilidad logarítmica es igual que minimizar la función de coste J que definimos anteriormente, podemos escribir la regla de actualización del descenso del gradiente del siguiente modo: Como maximizar la probabilidad logarítmica es igual que minimizar la función de coste J que definimos anteriormente, podemos escribir la regla de actualización del descenso del gradiente del siguiente modo: 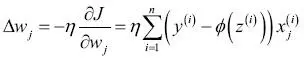 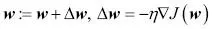 Esto es igual que la regla del descenso del gradiente para Adaline en el Capítulo 2, Entrenar algoritmos simples de aprendizaje automático para clasificación. Esto es igual que la regla del descenso del gradiente para Adaline en el Capítulo 2, Entrenar algoritmos simples de aprendizaje automático para clasificación. |
 |
Entrenar un modelo de regresión logística con scikit-learn
En la sección anterior, acabamos de ver algunos ejercicios de matemáticas y de código útiles, que nos han ayudado a ilustrar las diferencias conceptuales entre Adaline y la regresión logística. A continuación, aprenderemos cómo utilizar la implementación más optimizada de regresión logística de scikit-learn, que también soporta ajustes multiclase fuera de la librería (por defecto, OvR). En el siguiente código de ejemplo, utilizaremos la clase sklearn.linear_model.LogisticRegression, así como el ya conocido método fit, para entrenar el modelo en las tres clases en el conjunto de datos de entrenamiento de flores normalizado:
>>> from sklearn.linear_model import LogisticRegression
>>> lr = LogisticRegression(C=100.0, random_state=1)
>>> lr.fit(X_train_std, y_train)
>>> plot_decision_regions(X_combined_std,
... y_combined,
... classifier=lr,
... test_idx=range(105, 150))
>>> plt.xlabel('petal length [standardized]')
>>> plt.ylabel('petal width [standardized]')
>>> plt.legend(loc='upper left')
>>> plt.show()
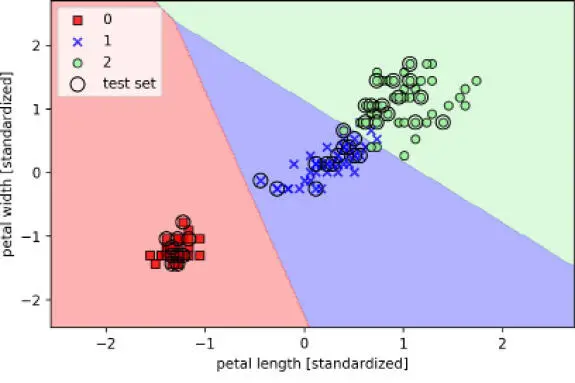
Después de ajustar el modelo en los datos de entrenamiento, hemos mostrado gráficamente las regiones de decisión, las muestras de entrenamiento y las muestras de prueba, como puedes ver en la siguiente imagen:
Si piensas en el código anterior que utilizamos para entrenar el modelo LogisticRegression, debes estar preguntándote: «¿Qué es este parámetro misterioso C?». Trataremos este parámetro en la siguiente subsección donde, en primer lugar, introduciremos los conceptos de sobreajuste y regularización. Sin embargo, antes de pasar a estos temas, vamos a acabar nuestra discusión sobre las probabilidades de pertenencia a una clase.
La probabilidad de que los ejemplos de entrenamiento pertenezcan a una determinada clase puede ser calculada con el método predict_proba. Por ejemplo, podemos predecir las probabilidades de las tres primeras muestras en la prueba como sigue:
>>> lr.predict_proba(X_test_std[:3, :])
Este fragmento de código devuelve la matriz siguiente:
array([[ 3.20136878e-08, 1.46953648e-01, 8.53046320e-01],
[ 8.34428069e-01, 1.65571931e-01, 4.57896429e-12],
[ 8.49182775e-01, 1.50817225e-01, 4.65678779e-13]])
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Python Machine Learning»
Представляем Вашему вниманию похожие книги на «Python Machine Learning» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Python Machine Learning» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.